2 Getting Started with Oracle XML DB
This chapter provides some preliminary design criteria for consideration when planning your Oracle XML DB solution.
This chapter contains these topics:
Oracle XML DB Installation
Oracle XML DB is installed automatically in the following situations:
-
If Database Configuration Assistant (DBCA) is used to build Oracle Database using the general-purpose template
-
If you use SQL script
catqmto install Oracle Database
You can determine whether or not Oracle XML DB is already installed. If it is installed, then the following are true:
-
Database schema (user account)
XDBexists. To check that, run this query:SELECT * FROM ALL_USERS;
-
View
RESOURCE_VIEWexists. To check that, use this command:DESCRIBE RESOURCE_VIEW
See Also:
-
Chapter 34, "Administering Oracle XML DB" for information about installing and uninstalling Oracle XML DB manually
-
Oracle Database 2 Day + Security Guide for information about database schema
XDB
Oracle XML DB Use Cases
Oracle XML DB is suited for any application where some or all of the data processed by the application is represented using XML. Oracle XML DB provides for high-performance database ingestion, storage, processing and retrieval of XML data. It also lets you quickly and easily generate XML from existing relational data.
Applications for which Oracle XML DB is particularly suited include the following:
-
Business-to-business (B2B) and application-to-application (A2A) integration
-
Internet
-
Content-management
-
Messaging
-
Web Services
A typical Oracle XML DB application has one or more of the following characteristics:
-
Large numbers of XML documents must be ingested or generated
-
Large XML documents must be processed or generated
-
High-performance searching is needed, both within a document and across large collections of documents
-
High levels of security are needed
-
Fine-grained security is needed
-
Data processing must use XML documents, and data must be stored in relational tables
-
Programming must support open standards such as SQL, XML, XQuery, XPath, and XSL
-
Information must be accessed using standard Internet protocols such as FTP, HTTP(S)/WebDAV, and Java Database Connectivity (JDBC)
-
XML data must be queried from SQL
-
Analytic capabilities must be applied to XML data
-
XML documents must be validated against an XML schema
Oracle XML DB lets you fine-tune how XML documents are stored and processed in Oracle Database. Depending on the nature of the application, XML storage must have at least one of the following features
-
High performance ingestion and retrieval of XML documents
-
High performance indexing and searching of XML documents
-
Ability to update sections of an XML document
-
Management of structured or unstructured XML documents
Application Design Considerations for Oracle XML DB
This section mentions some preliminary design criteria that you can consider when planning your Oracle XML DB application.
Structure of Your Data
Is your data be highly structured (mostly XML), semi-structured, or mostly unstructured? If highly structured, are your tables XML schema-based or non-schema-based?
If your XML data is not XML schema-based, then, regardless of how structured it is, you can store it in an XMLType table or view as binary XML or as a CLOB instance, or you can store it as a file in an Oracle XML DB Repository folder.
If your XML data is XML schema-based then you can use unstructured, structured (object-relational), or binary XML storage for its structured parts. For the unstructured parts, you have the same options as for data that is not XML schema-based.
See Also:
Chapter 3, "Using Oracle XML DB"Oracle XML DB Repository Access
This section pertains to data that is stored as resources in Oracle XML DB Repository.
How do other applications and users need to access your XML and other data? How secure must the access be? Do you need versioning?
There are two main repository access methods:
-
Navigation-based access or path-based access. This is suitable for both content/document and data oriented applications. Oracle XML DB provides the following languages and access APIs:
-
SQL access through resource and path views. See Chapter 25, "Accessing the Repository using RESOURCE_VIEW and PATH_VIEW".
-
PL/SQL access through
DBMS_XDB. See Chapter 26, "Accessing the Repository using PL/SQL". -
Protocol-based access using HTTP(S)/WebDAV or FTP, most suited to content-oriented applications. See Chapter 28, "Accessing the Repository using Protocols".
-
-
Query-based access. This can be most suited to data oriented applications. Oracle XML DB provides access using SQL queries through the following APIs:
-
Java access (through JDBC). See Java DOM API for XMLType.
-
PL/SQL access. See Chapter 13, "PL/SQL APIs for XMLType".
-
These options for accessing repository data are also discussed in Chapter 21, "Accessing Oracle XML DB Repository Data".
You can also consider the following access criteria:
-
What levels of security do you need? See Chapter 27, "Repository Access Control".
-
What kind of indexing best suits your application? Do you need to use Oracle Text indexing and querying? See Chapter 4, "XMLType Operations", Chapter 6, "Indexing XMLType Data", and Chapter 12, "Full-Text Search Over XML Data".
-
Do you need to version the data? If yes, see Chapter 24, "Managing Resource Versions".
Application Language
In which languages do you program your application?
You can program your Oracle XML DB applications in the following languages:
-
Java (JDBC, Java Servlets)
-
PL/SQL
Processing
Do you need to generate XML data? See Chapter 18, "Generating XML Data from the Database".
How often are XML documents accessed, updated, and manipulated? Do you need to update fragments or whole documents?
Do you need to transform XML data to HTML, WML, or other languages? If so, how does your application do this? See Chapter 11, "Transforming and Validating XMLType Data".
Must your application be primarily database-resident or must it work in both the database and middle tier?
Is your application data-centric, document-centric (content-centric), or both?
The following processing options are available and should be considered when designing your Oracle XML DB application:
-
XSLT. Do you need to transform the XML data to HTML, WML, or other languages, and, if so, how does your application transform the XML data? While storing XML documents in Oracle XML DB, you can optionally ensure that their structure complies with (validates against) specific XML schemas. See Chapter 11, "Transforming and Validating XMLType Data".
-
DOM fidelity, document fidelity. Use unstructured storage to preserve document fidelity. Use binary XML or structured storage for XML schema-based data to preserve DOM fidelity. See Chapter 13, "PL/SQL APIs for XMLType" and "DOM Fidelity".
-
XPath searching. You can use XPath syntax embedded in a SQL statement or as part of an HTTP(S) request to query XML content in the database. See Chapter 4, "XMLType Operations", Chapter 12, "Full-Text Search Over XML Data", Chapter 21, "Accessing Oracle XML DB Repository Data", and Chapter 25, "Accessing the Repository using RESOURCE_VIEW and PATH_VIEW".
-
XML Generation and
XMLTypeviews. Do you need to generate or regenerate XML data? If yes, see Chapter 18, "Generating XML Data from the Database".
How often are XML documents accessed, updated, and manipulated? See Chapter 4, "XMLType Operations" and Chapter 25, "Accessing the Repository using RESOURCE_VIEW and PATH_VIEW".
Do you need to update fragments or whole documents? You can use XPath expressions to specify individual elements and attributes of your document during updates, without rewriting the entire document. This is more efficient, especially for large XML documents. Chapter 7, "XML Schema Storage and Query: Basic".
Is your application data-centric, document- and content-centric, or integrated (is both data- and document-centric)? See Chapter 3, "Using Oracle XML DB".
Messaging
Does your application exchange XML data with other applications across gateways? Do you need Oracle Streams Advanced Queuing (AQ) or SOAP compliance? See Chapter 37, "Exchanging XML Data using Oracle Streams AQ".
Advanced Queuing (AQ) supports XML and XMLType applications. You can create queues with payloads that contain XMLType attributes. These can be used for transmitting and storing messages that contain XML documents. By defining Oracle Database objects with XMLType attributes, you can do the following:
-
Store more than one type of XML document in the same queue. The documents are stored internally as
CLOBvalues. -
Selectively dequeue messages with
XMLTypeattributes using an XPath or XQuery expression. -
Define rule-based subscribers that query message content using an XPath or XQuery expression.
-
Define transformations to convert Oracle Database objects to
XMLType.
Storage
How and where do you store your relational data, XML data, XML schemas, and so on?
Note:
The choices you make for data structure, access, language, and processing are typically interdependent, but they are not dependent on the storage model you choose.Figure 2-1 shows the Oracle XML DB storage options for XMLType tables and views.
Figure 2-1 Oracle XML DB Storage Options for XML Data
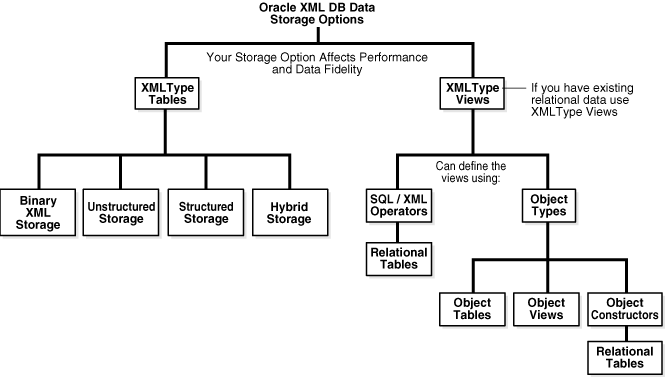
Description of "Figure 2-1 Oracle XML DB Storage Options for XML Data"
If you have existing relational data, you can access it as XML data by creating XMLType views over it. You can use the following to define the XMLType views:
-
SQL/XML functions. See Chapter 18, "Generating XML Data from the Database" and Chapter 5, "Using XQuery with Oracle XML DB".
-
Object types: object tables, object constructors, and object views.
Regardless of which storage options you choose for your application, Oracle XML DB provides the same functionality. Though the storage model you use can affect your application performance and XML data fidelity, it is totally independent of all of the following:
-
How, and how often, you query or update your data.
-
How you access your data. This is determined only by your application processing requirements.
-
What language(s) your application uses. This is determined only by your application processing requirements.
See Also:
Oracle XML DB Performance
One objection to using XML to represent data is that it generates higher overhead than other representations. Oracle XML DB incorporates several features specifically designed to address this issue by significantly improving the performance of XML processing. These are described in the following sections:
XML Storage Requirements
Data represented in XML and stored in a text file averages three times the size of the same data in a Java object or in relational tables. There are two main reasons for this:
-
Tag names (metadata describing the data) and white space (formatting characters) take up a significant amount of space in the document, particularly for highly structured, data-centric XML.
-
All data in an XML file is represented in human readable (string) format.
The string representation of a numeric value needs about twice as many bytes as the native (binary) representation. When XML documents are stored in Oracle XML DB using structured or binary XML storage, the storage process discards all tags and white space in the document.
The amount of space saved by this optimization depends on the ratio of tag names to data, and the number of collections in the document. For highly-structured, data-centric XML data, the savings can be significant. When a document is printed, or when node-based operations such as XPath evaluation take place, Oracle XML DB uses the information contained in the associated XML schema to dynamically reconstruct any necessary tag information.
XML Memory Management
Document Object Model (DOM) is the dominant programming model for XML documents. DOM APIs are easy to use but the DOM Tree that underpins them is expensive to generate, in terms of memory. A typical DOM implementation maintains approximately 80 to 120 bytes of system overhead for each node in the DOM tree. For highly structured data, the DOM tree can require 10 to 20 times more memory than the document on which it is based.
A conventional DOM implementation requires the entire contents of an XML document to be loaded into the DOM tree before any operations can take place. If an application only needs to process a small percentage of the nodes in the document, this is extremely inefficient in terms of memory and processing overhead. The alternative Simple API for XML (SAX) approach reduces the amount of memory required to process an XML document, but its disadvantage is that it only allows linear processing of nodes in the XML document.
See Also:
-
http://www.w3.org/DOM/for information about DOM -
http://www.saxproject.org/for information about SAX
Use of XOBs Reduces Memory Overhead for XML Schema-Based Documents
Oracle XML DB reduces memory overhead associated with DOM programming by managing XML schema-based XML documents using an internal structure in dynamic memory called an XML Object (XOB). A XOB is much smaller than the equivalent DOM since it does not duplicate information like tag names and node types, that can easily be obtained from the associated XML schema. Oracle XML DB automatically uses a XOB whenever an application works with the contents of a schema-based XMLType. The use of the XOB is transparent to you. It is hidden behind the XMLType data type and the C, PL/SQL, and Java APIs.
XOB Uses a Lazily-Loaded Virtual DOM
The XOB can also reduce the amount of memory required to work with an XML document using the Lazily-Loaded Virtual DOM feature. This lets Oracle XML DB defer loading the dynamic memory representation of nodes that are part of sub-elements or collection until code attempts to operate on a node in that object. Consequently, if an application only operates on a few nodes in a document, only those nodes and their immediate siblings are loaded into memory.The XOB can only used when an XML document is based on an XML schema. If the contents of the XML document are not based on an XML schema, a traditional DOM is used instead of the XOB.
XML Parsing Optimizations
To populate a DOM tree the application must parse the XML document. The process of creating a DOM tree from an XML file is very CPU- intensive. In a typical DOM-based application, where the XML documents are stored as text, every document has to be parsed and loaded into the DOM tree before the application can work with it. If the contents of the DOM tree are updated the entire tree must be serialized back into a text format and written out to disk.
Oracle XML DB eliminates the need to parse documents over and over again. No parsing is needed when an XML document is loaded from disk into memory, if the document is stored as structured or binary XML storage. Oracle XML DB maps directly between the format on disk and the format in dynamic memory using information derived from the associated XML schema. When changes are made to XML schema-based data, Oracle XML DB is able to write just the updated data back to disk. When XML data is not based on an XML schema, a traditional DOM is used instead.
Node-Searching Optimizations
Most DOM implementations use string comparisons when searching for a particular node in the DOM tree. Even a simple search of a DOM tree can require hundreds or thousands of instruction cycles. Searching for a node in a XOB is much more efficient than searching for a node in a DOM. A XOB is based on a computed offset model, similar to a C/C++ object, and uses dynamic hashtables rather than string comparisons to perform node searches.
XML Schema Optimizations
Making use of the powerful features associated with XML schema in a conventional XML application can generate significant amounts of additional overhead. For example, before an XML document can be validated against an XML schema, the schema itself must be located, parsed, and validated.
Oracle XML DB minimizes the overhead associated with using XML schema. When an XML schema is registered with the database, it is loaded in the Oracle XML DB schema cache, together with all of the metadata required to map between the textual, XOB and on- disk representations of the data. After the XML schema has been registered with the database no additional parsing or validation of the XML schema is required before it can be used. The schema cache is shared by all users of the database. Whenever an Oracle XML DB operation requires information contained in the XML schema, it can access the required information directly from the cache.
Load Balancing Through Cached XML Schema
Some operations, such as performing a full schema validation, or serializing an XML document back into text form, can still require significant memory and CPU resources. Oracle XML DB let these operations be off-loaded to the client or middle tier processor. Both Oracle Call Interface (OCI) interface and the OCI driver for JDBC allow the XOB to be managed by the client.The cached representation of the XML schema can also be downloaded to the client. This lets operations such as XML printing, and XML schema validation be performed using client or middle tier resources, rather than server resources.
Reduced Bottlenecks From Code That Is Not Native
Another bottleneck for XML-based Java applications happens when parsing an XML file. Even natively compiled or JIT compiled Java performs XML parsing operations twice as slowly compared to using native C language. One of the major performance bottlenecks in implementing XML applications is the cost of transforming data in an XML document between text, Java, and native server representations. The cost of performing these transformations is proportional to the size and complexity of the XML file and becomes severe even in moderately sized files.
Oracle XML DB addresses these issues by implementing all of the Java and PL/SQL interfaces as thin facades over a native implementation in the C language. Java, C, PL/SQL, and SQL all use the same underlying implementation. This provides for language-neutral XML support and higher performance XML parsing and DOM processing.
Reduced Java Type Conversion Bottlenecks
One of the biggest bottlenecks when using Java and XML is with type conversions. Internally Java uses UCS-2 to represent character data. Most XML files and databases do not contain UCS-2 encoded data. All data contained in an XML file must be converted from 8-Bit or UTF-8 encoding to UCS-2 encoding before it can be manipulated in a Java program.
Oracle XML DB addresses these problems with lazy type conversions. With lazy type conversions, the content of a node is not converted into the format required by Java until the application attempts to access the contents of the node. Data remains in the internal representation till the last moment. Avoiding unnecessary type conversions can result in significant performance improvements when an application only needs to access a few nodes in an XML document.
Consider a JSP that loads a name from the Oracle Database and prints it out in the generated HTML output. Typical JSP implementations read the name from the database (that probably contains data in the ASCII or ISO8859 character sets), convert the data to UCS-2, and return it to Java as a string. The JSP would not look at the string content, but only print it out after printing the enclosing HTML, probably converting back to the same ASCII or ISO8859 for the client browser. Oracle XML DB provides a write interface on XMLType so that any element can write itself directly to a stream (such as a ServletOutputStream) without conversion through Java character sets. Figure 2-2 shows the Oracle XML DB Application Program Interface (API) stack.
Figure 2-2 Oracle XML DB Application Program Interface (API) Stack
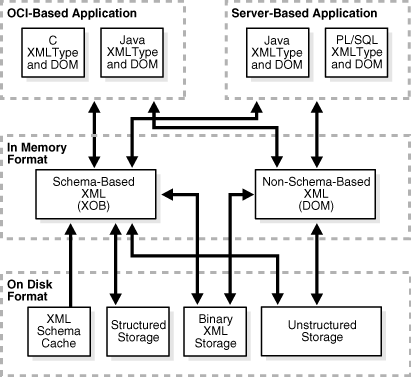
Description of "Figure 2-2 Oracle XML DB Application Program Interface (API) Stack"