3 Partitioning for Availability, Manageability, and Performance
This chapter provides high-level insight into how partitioning enables availability, manageability, and performance. This chapter presents guidelines on when to use a given partitioning strategy. The main focus of this chapter is the use of table partitioning, though most of the recommendations and considerations apply to index partitioning as well.
This chapter contains the following sections:
Partition Pruning
Partition pruning is an essential performance feature for data warehouses. In partition pruning, the optimizer analyzes FROM and WHERE clauses in SQL statements to eliminate unneeded partitions when building the partition access list. This functionality enables Oracle Database to perform operations only on those partitions that are relevant to the SQL statement.
This section contains the following topics:
Benefits of Partition Pruning
Partition pruning dramatically reduces the amount of data retrieved from disk and shortens processing time, thus improving query performance and optimizing resource utilization. If you partition the index and table on different columns (with a global partitioned index), then partition pruning also eliminates index partitions even when the partitions of the underlying table cannot be eliminated.
Depending upon the actual SQL statement, Oracle Database may use static or dynamic pruning. Static pruning occurs at compile-time, with the information about the partitions accessed beforehand. Dynamic pruning occurs at run-time, meaning that the exact partitions to be accessed by a statement are not known beforehand. A sample scenario for static pruning is a SQL statement containing a WHERE condition with a constant literal on the partition key column. An example of dynamic pruning is the use of operators or functions in the WHERE condition.
Partition pruning affects the statistics of the objects where pruning occurs and also affects the execution plan of a statement.
Information That Can Be Used for Partition Pruning
Oracle Database prunes partitions when you use range, LIKE, equality, and IN-list predicates on the range or list partitioning columns, and when you use equality and IN-list predicates on the hash partitioning columns.
On composite partitioned objects, Oracle Database can prune at both levels using the relevant predicates. Examine the table sales_range_hash, which is partitioned by range on the column s_saledate and subpartitioned by hash on the column s_productid in Example 3-1.
Example 3-1 Creating a table with partition pruning
CREATE TABLE sales_range_hash(
s_productid NUMBER,
s_saledate DATE,
s_custid NUMBER,
s_totalprice NUMBER)
PARTITION BY RANGE (s_saledate)
SUBPARTITION BY HASH (s_productid) SUBPARTITIONS 8
(PARTITION sal99q1 VALUES LESS THAN
(TO_DATE('01-APR-1999', 'DD-MON-YYYY')),
PARTITION sal99q2 VALUES LESS THAN
(TO_DATE('01-JUL-1999', 'DD-MON-YYYY')),
PARTITION sal99q3 VALUES LESS THAN
(TO_DATE('01-OCT-1999', 'DD-MON-YYYY')),
PARTITION sal99q4 VALUES LESS THAN
(TO_DATE('01-JAN-2000', 'DD-MON-YYYY')));
SELECT * FROM sales_range_hash
WHERE s_saledate BETWEEN (TO_DATE('01-JUL-1999', 'DD-MON-YYYY'))
AND (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')) AND s_productid = 1200;
Oracle uses the predicate on the partitioning columns to perform partition pruning as follows:
-
When using range partitioning, Oracle accesses only partitions
sal99q2andsal99q3, representing the partitions for the third and fourth quarters of 1999. -
When using hash subpartitioning, Oracle accesses only the one subpartition in each partition that stores the rows with
s_productid=1200. The mapping between the subpartition and the predicate is calculated based on Oracle's internal hash distribution function.
A reference-partitioned table can take advantage of partition pruning through the join with the referenced table. Virtual column-based partitioned tables benefit from partition pruning for statements that use the virtual column-defining expression in the SQL statement.
How to Identify Whether Partition Pruning Has Been Used
Whether Oracle uses partition pruning is reflected in the execution plan of a statement, either in the plan table for the EXPLAIN PLAN statement or in the shared SQL area.
The partition pruning information is reflected in the plan columns PSTART (PARTITION_START) and PSTOP (PARTITION_STOP). For serial statements, the pruning information is also reflected in the OPERATION and OPTIONS columns.
See Also:
Oracle Database Performance Tuning Guide for more information aboutEXPLAIN PLAN and how to interpret itStatic Partition Pruning
For many cases, Oracle determines the partitions to be accessed at compile time. Static partition pruning occurs if you use static predicates, except for the following cases:
-
Partition pruning occurs using the result of a subquery.
-
The optimizer rewrites the query with a star transformation and pruning occurs after the star transformation.
-
The most efficient execution plan is a nested loop.
These three cases result in the use of dynamic pruning.
If at parse time Oracle can identify which contiguous set of partitions is accessed, then the PSTART and PSTOP columns in the execution plan show the begin and the end values of the partitions being accessed. Any other cases of partition pruning, including dynamic pruning, show the KEY value in PSTART and PSTOP, optionally with an additional attribute.
The following is an example:
SQL> explain plan for select * from sales where time_id = to_date('01-jan-2001', 'dd-mon-yyyy');
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------
Plan hash value: 3971874201
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 673 | 19517 | 27 (8)| 00:00:01 | | |
| 1 | PARTITION RANGE SINGLE| | 673 | 19517 | 27 (8)| 00:00:01 | 17 | 17 |
|* 2 | TABLE ACCESS FULL | SALES | 673 | 19517 | 27 (8)| 00:00:01 | 17 | 17 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("TIME_ID"=TO_DATE('2001-01-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
This plan shows that Oracle accesses partition number 17, as shown in the PSTART and PSTOP columns. The OPERATION column shows PARTITION RANGE SINGLE, indicating that only a single partition is being accessed. If OPERATION shows PARTITION RANGE ALL, then all partitions are being accessed and effectively no pruning takes place. PSTART then shows the very first partition of the table and PSTOP shows the very last partition.
An execution plan with a full table scan on an interval-partitioned table shows 1 for PSTART, and 1048575 for PSTOP, regardless of how many interval partitions were created.
Dynamic Partition Pruning
Dynamic pruning occurs if pruning is possible and static pruning is not possible. The following examples show multiple dynamic pruning cases:
Dynamic Pruning with Bind Variables
Statements that use bind variables against partition columns result in dynamic pruning. For example:
SQL> explain plan for select * from sales s where time_id in ( :a, :b, :c, :d);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------
Plan hash value: 513834092
---------------------------------------------------------------------------------------------------
| Id | Operation | Name |Rows|Bytes|Cost (%CPU)| Time | Pstart| Pstop|
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | |2517|72993| 292 (0)|00:00:04| | |
| 1 | INLIST ITERATOR | | | | | | | |
| 2 | PARTITION RANGE ITERATOR | |2517|72993| 292 (0)|00:00:04|KEY(I) |KEY(I)|
| 3 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |2517|72993| 292 (0)|00:00:04|KEY(I) |KEY(I)|
| 4 | BITMAP CONVERSION TO ROWIDS | | | | | | | |
|* 5 | BITMAP INDEX SINGLE VALUE |SALES_TIME_BIX| | | | |KEY(I) |KEY(I)|
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("TIME_ID"=:A OR "TIME_ID"=:B OR "TIME_ID"=:C OR "TIME_ID"=:D)
For parallel execution plans, only the partition start and stop columns contain the partition pruning information; the operation column contains information for the parallel operation, as shown in the following example:
SQL> explain plan for select * from sales where time_id in (:a, :b, :c, :d);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------
Plan hash value: 4058105390
-------------------------------------------------------------------------------------------------
| Id| Operation | Name |Rows|Bytes|Cost(%CP| Time |Pstart| Pstop| TQ |INOUT| PQ Dis|
-------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | |2517|72993| 75(36)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM)|:TQ10000|2517|72993| 75(36)|00:00:01| | |Q1,00| P->S|QC(RAND|
| 3| PX BLOCK ITERATOR| |2517|72993| 75(36)|00:00:01|KEY(I)|KEY(I)|Q1,00| PCWC| |
|* 4| TABLE ACCESS FULL| SALES |2517|72993| 75(36)|00:00:01|KEY(I)|KEY(I)|Q1,00| PCWP| |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("TIME_ID"=:A OR "TIME_ID"=:B OR "TIME_ID"=:C OR "TIME_ID"=:D)
See Also:
Oracle Database Performance Tuning Guide for more information aboutEXPLAIN PLAN and how to interpret itDynamic Pruning with Subqueries
Statements that explicitly use subqueries against partition columns result in dynamic pruning. For example:
SQL> explain plan for select sum(amount_sold) from sales where time_id in
(select time_id from times where fiscal_year = 2000);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 3827742054
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 25 | 523 (5)| 00:00:07 | | |
| 1 | SORT AGGREGATE | | 1 | 25 | | | | |
|* 2 | HASH JOIN | | 191K| 4676K| 523 (5)| 00:00:07 | | |
|* 3 | TABLE ACCESS FULL | TIMES | 304 | 3648 | 18 (0)| 00:00:01 | | |
| 4 | PARTITION RANGE SUBQUERY| | 918K| 11M| 498 (4)| 00:00:06 |KEY(SQ)|KEY(SQ)|
| 5 | TABLE ACCESS FULL | SALES | 918K| 11M| 498 (4)| 00:00:06 |KEY(SQ)|KEY(SQ)|
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("TIME_ID"="TIME_ID")
3 - filter("FISCAL_YEAR"=2000)
See Also:
Oracle Database Performance Tuning Guide for more information aboutEXPLAIN PLAN and how to interpret itDynamic Pruning with Star Transformation
Statements that get transformed by the database using the star transformation result in dynamic pruning. For example:
SQL> explain plan for select p.prod_name, t.time_id, sum(s.amount_sold)
from sales s, times t, products p
where s.time_id = t.time_id and s.prod_id = p.prod_id and t.fiscal_year = 2000
and t.fiscal_week_number = 3 and p.prod_category = 'Hardware'
group by t.time_id, p.prod_name;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------
Plan hash value: 4020965003
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Pstart| Pstop |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 79 | | |
| 1 | HASH GROUP BY | | 1 | 79 | | |
|* 2 | HASH JOIN | | 1 | 79 | | |
|* 3 | HASH JOIN | | 2 | 64 | | |
|* 4 | TABLE ACCESS FULL | TIMES | 6 | 90 | | |
| 5 | PARTITION RANGE SUBQUERY | | 587 | 9979 |KEY(SQ)|KEY(SQ)|
| 6 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES | 587 | 9979 |KEY(SQ)|KEY(SQ)|
| 7 | BITMAP CONVERSION TO ROWIDS | | | | | |
| 8 | BITMAP AND | | | | | |
| 9 | BITMAP MERGE | | | | | |
| 10 | BITMAP KEY ITERATION | | | | | |
| 11 | BUFFER SORT | | | | | |
|* 12 | TABLE ACCESS FULL | TIMES | 6 | 90 | | |
|* 13 | BITMAP INDEX RANGE SCAN | SALES_TIME_BIX | | |KEY(SQ)|KEY(SQ)|
| 14 | BITMAP MERGE | | | | | |
| 15 | BITMAP KEY ITERATION | | | | | |
| 16 | BUFFER SORT | | | | | |
| 17 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 14 | 658 | | |
|* 18 | INDEX RANGE SCAN | PRODUCTS_PROD_CAT_IX | 14 | | | |
|* 19 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX | | |KEY(SQ)|KEY(SQ)|
| 20 | TABLE ACCESS BY INDEX ROWID | PRODUCTS | 14 | 658 | | |
|* 21 | INDEX RANGE SCAN | PRODUCTS_PROD_CAT_IX | 14 | | | |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="P"."PROD_ID")
3 - access("S"."TIME_ID"="T"."TIME_ID")
4 - filter("T"."FISCAL_WEEK_NUMBER"=3 AND "T"."FISCAL_YEAR"=2000)
12 - filter("T"."FISCAL_WEEK_NUMBER"=3 AND "T"."FISCAL_YEAR"=2000)
13 - access("S"."TIME_ID"="T"."TIME_ID")
18 - access("P"."PROD_CATEGORY"='Hardware')
19 - access("S"."PROD_ID"="P"."PROD_ID")
21 - access("P"."PROD_CATEGORY"='Hardware')
Note
-----
- star transformation used for this statement
Note:
TheCost (%CPU) and Time columns were removed from the plan table output in this example.See Also:
Oracle Database Performance Tuning Guide for more information aboutEXPLAIN PLAN and how to interpret itDynamic Pruning with Nested Loop Joins
Statements that are most efficiently executed using a nested loop join use dynamic pruning. For example:
SQL> explain plan for select t.time_id, sum(s.amount_sold)
from sales s, times t
where s.time_id = t.time_id and t.fiscal_year = 2000 and t.fiscal_week_number = 3
group by t.time_id;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 50737729
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 168 | 126 (4)| 00:00:02 | | |
| 1 | HASH GROUP BY | | 6 | 168 | 126 (4)| 00:00:02 | | |
| 2 | NESTED LOOPS | | 3683 | 100K| 125 (4)| 00:00:02 | | |
|* 3 | TABLE ACCESS FULL | TIMES | 6 | 90 | 18 (0)| 00:00:01 | | |
| 4 | PARTITION RANGE ITERATOR| | 629 | 8177 | 18 (6)| 00:00:01 | KEY | KEY |
|* 5 | TABLE ACCESS FULL | SALES | 629 | 8177 | 18 (6)| 00:00:01 | KEY | KEY |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("T"."FISCAL_WEEK_NUMBER"=3 AND "T"."FISCAL_YEAR"=2000)
5 - filter("S"."TIME_ID"="T"."TIME_ID")
See Also:
Oracle Database Performance Tuning Guide for more information aboutEXPLAIN PLAN and how to interpret itPartition Pruning Tips
When using partition pruning, you should consider the following:
Data Type Conversions
To get the maximum performance benefit from partition pruning, you should avoid constructs that require the database to convert the data type you specify. Data type conversions typically result in dynamic pruning when static pruning would have otherwise been possible. SQL statements that benefit from static pruning perform better than statements that benefit from dynamic pruning.
A common case of data type conversions occurs when using the Oracle DATE data type. An Oracle DATE data type is not a character string but is only represented as such when querying the database; the format of the representation is defined by the NLS setting of the instance or the session. Consequently, the same reverse conversion has to happen when inserting data into a DATE field or when specifying a predicate on such a field.
A conversion can either happen implicitly or explicitly by specifying a TO_DATE conversion. Only a properly applied TO_DATE function guarantees that the database can uniquely determine the date value and using it potentially for static pruning, which is especially beneficial for single partition access.
Consider the following example that runs against the sample SH schema in an Oracle Database. You would like to know the total revenue number for the year 2000. There are multiple ways you can retrieve the answer to the query, but not every method is equally efficient.
explain plan for SELECT SUM(amount_sold) total_revenue FROM sales, WHERE time_id between '01-JAN-00' and '31-DEC-00';
The plan should now be similar to the following:
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 525 (8)| 00:00:07 | | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | | |
|* 2 | FILTER | | | | | | | |
| 3 | PARTITION RANGE ITERATOR| | 230K| 2932K| 525 (8)| 00:00:07 | KEY | KEY |
|* 4 | TABLE ACCESS FULL | SALES | 230K| 2932K| 525 (8)| 00:00:07 | KEY | KEY |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE('01-JAN-00')<=TO_DATE('31-DEC-00'))
4 - filter("TIME_ID">='01-JAN-00' AND "TIME_ID"<='31-DEC-00')
In this case, the keyword KEY for both PSTART and PSTOP means that dynamic partition pruning occurs at run-time. Consider the following case.
explain plan for select sum(amount_sold) from sales where time_id between '01-JAN-2000' and '31-DEC-2000' ;
The execution plan now shows the following:
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 127 (4)| | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | |
| 2 | PARTITION RANGE ITERATOR| | 230K| 2932K| 127 (4)| 13 | 16 |
|* 3 | TABLE ACCESS FULL | SALES | 230K| 2932K| 127 (4)| 13 | 16 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', "syyyy-mm-dd hh24:mi:ss'))
Note:
TheTime column was removed from the execution plan.The execution plan shows static partition pruning. The query accesses a contiguous list of partitions 13 to 16. In this particular case, the way the date format was specified matches the NLS date format setting. Though this example shows the most efficient execution plan, you cannot rely on the NLS date format setting to define a certain format.
alter session set nls_date_format='fmdd Month yyyy'; explain plan for select sum(amount_sold) from sales where time_id between '01-JAN-2000' and '31-DEC-2000' ;
The execution plan now shows the following:
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 525 (8)| | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | |
|* 2 | FILTER | | | | | | |
| 3 | PARTITION RANGE ITERATOR| | 230K| 2932K| 525 (8)| KEY | KEY |
|* 4 | TABLE ACCESS FULL | SALES | 230K| 2932K| 525 (8)| KEY | KEY |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE('01-JAN-2000')<=TO_DATE('31-DEC-2000'))
4 - filter("TIME_ID">='01-JAN-2000' AND "TIME_ID"<='31-DEC-2000')
Note:
TheTime column was removed from the execution plan.This plan, which uses dynamic pruning, again is less efficient than the static pruning execution plan. To guarantee a static partition pruning plan, you should explicitly convert data types to match the partition column data type. For example:
explain plan for select sum(amount_sold)
from sales
where time_id between to_date('01-JAN-2000','dd-MON-yyyy')
and to_date('31-DEC-2000','dd-MON-yyyy') ;
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 127 (4)| | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | |
| 2 | PARTITION RANGE ITERATOR| | 230K| 2932K| 127 (4)| 13 | 16 |
|* 3 | TABLE ACCESS FULL | SALES | 230K| 2932K| 127 (4)| 13 | 16 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Note:
TheTime column was removed from the execution plan.See Also:
-
Oracle Database SQL Language Reference for details about the
DATEdata type -
Oracle Database Globalization Support Guide for details about NLS settings and globalization issues
Function Calls
There are several cases when the optimizer cannot perform pruning. One common reasons is when an operator is used on top of a partitioning column. This could be an explicit operator (for example, a function) or even an implicit operator introduced by Oracle as part of the necessary data type conversion for executing the statement. For example, consider the following query:
EXPLAIN PLAN FOR
SELECT SUM(quantity_sold)
FROM sales
WHERE time_id = TO_TIMESTAMP('1-jan-2000', 'dd-mon-yyyy');
Because time_id is of type DATE and Oracle must promote it to the TIMESTAMP type to get the same data type, this predicate is internally rewritten as:
TO_TIMESTAMP(time_id) = TO_TIMESTAMP('1-jan-2000', 'dd-mon-yyyy')
The execution plan for this statement is as follows:
--------------------------------------------------------------------------------------------
|Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 11 | 6 (17)| 00:00:01 | | |
| 1 | SORT AGGREGATE | | 1 | 11 | | | | |
| 2 | PARTITION RANGE ALL| | 10 | 110 | 6 (17)| 00:00:01 | 1 | 16 |
|*3 | TABLE ACCESS FULL | SALES | 10 | 110 | 6 (17)| 00:00:01 | 1 | 16 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(INTERNAL_FUNCTION("TIME_ID")=TO_TIMESTAMP('1-jan-2000',:B1))
15 rows selected
The SELECT statement accesses all partitions even though pruning down to a single partition could have taken place. Consider the example to find the total sales revenue number for 2000. Another way to construct the query would be:
EXPLAIN PLAN FOR SELECT SUM(amount_sold) FROM sales WHERE TO_CHAR(time_id,'yyyy') = '2000';
This query applies a function call to the partition key column, which generally disables partition pruning. The execution plan shows a full table scan with no partition pruning:
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 527 (9)| 00:00:07 | | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | | |
| 2 | PARTITION RANGE ALL| | 9188 | 116K| 527 (9)| 00:00:07 | 1 | 28 |
|* 3 | TABLE ACCESS FULL | SALES | 9188 | 116K| 527 (9)| 00:00:07 | 1 | 28 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(TO_CHAR(INTERNAL_FUNCTION("TIME_ID"),'yyyy')='2000')
Avoid using implicit or explicit functions on the partition columns. If your queries commonly use function calls, then consider using a virtual column and virtual column partitioning to benefit from partition pruning in these cases.
Collection Tables
The following example illustrates what an EXPLAIN PLAN statement might look like when it contains Collection Tables, which, for the purposes of this discussion, are ordered collection tables or nested tables. It is based on the CREATE TABLE statement in "Partitioning of Collections in XMLType and Objects". Note that a full table access is not performed because it is constrained to just the partition in question.
EXPLAIN PLAN FOR SELECT p.ad_textdocs_ntab FROM print_media_part p; Explained. PLAN_TABLE_OUTPUT ----------------------------------------------------------------------- Plan hash value: 2207588228 ----------------------------------------------------------------------- | Id | Operation | Name | Pstart| Pstop | ----------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | 1 | PARTITION REFERENCE SINGLE| | KEY | KEY | | 2 | TABLE ACCESS FULL | TEXTDOC_NT | KEY | KEY | | 3 | PARTITION RANGE ALL | | 1 | 2 | | 4 | TABLE ACCESS FULL | PRINT_MEDIA_PART | 1 | 2 | ----------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement
Partition-Wise Joins
Partition-wise joins reduce query response time by minimizing the amount of data exchanged among parallel execution servers when joins execute in parallel. This significantly reduces response time and improves the use of both CPU and memory resources. In Oracle Real Application Clusters (Oracle RAC) environments, partition-wise joins also avoid or at least limit the data traffic over the interconnect, which is the key to achieving good scalability for massive join operations.
Partition-wise joins can be full or partial. Oracle Database decides which type of join to use.
This section contains the following topics:
Full Partition-Wise Joins
A full partition-wise join divides a large join into smaller joins between a pair of partitions from the two joined tables. To use this feature, you must equipartition both tables on their join keys, or use reference partitioning. For example, consider a large join between a sales table and a customer table on the column cust_id. The query "find the records of all customers who bought more than 100 articles in Quarter 3 of 1999" is a typical example of a SQL statement performing such a join, as shown in Example 3-2.
Example 3-2 Querying with a full partition-wise join
SELECT c.cust_last_name, COUNT(*)
FROM sales s, customers c
WHERE s.cust_id = c.cust_id AND
s.time_id BETWEEN TO_DATE('01-JUL-1999', 'DD-MON-YYYY') AND
(TO_DATE('01-OCT-1999', 'DD-MON-YYYY'))
GROUP BY c.cust_last_name HAVING COUNT(*) > 100;
Such a large join is typical in data warehousing environments. In this case, the entire customer table is joined with one quarter of the sales data. In large data warehouse applications, this might mean joining millions of rows. The join method to use in that case is obviously a hash join. You can reduce the processing time for this hash join even more if both tables are equipartitioned on the cust_id column. This functionality enables a full partition-wise join.
When you execute a full partition-wise join in parallel, the granule of parallelism is a partition. Consequently, the degree of parallelism is limited to the number of partitions. For example, you require at least 16 partitions to set the degree of parallelism of the query to 16.
You can use various partitioning methods to equipartition both tables. These methods are described at a high level in the following subsections:
Full Partition-Wise Joins: Single-Level - Single-Level
This is the simplest method: two tables are both partitioned by the join column. In the example, the customers and sales tables are both partitioned on the cust_id columns. This partitioning method enables full partition-wise joins when the tables are joined on cust_id, both representing the same customer identification number. This scenario is available for range-range, list-list, and hash-hash partitioning. Interval-range and interval-interval full partition-wise joins are also supported and can be compared to range-range.
In serial, this join is performed between pairs of matching hash partitions, one at a time. When one partition pair has been joined, the join of another partition pair begins. The join completes when all partition pairs have been processed. To ensure a good workload distribution, you should either have many more partitions than the requested degree of parallelism or use equisize partitions with as many partitions as the requested degree of parallelism. Using hash partitioning on a unique or almost-unique column, with the number of partitions equal to a power of 2, is a good way to create equisized partitions.
Note:
-
A pair of matching hash partitions is defined as one partition with the same partition number from each table. For example, with full partition-wise joins based on hash partitioning, the database joins partition 0 of
saleswith partition 0 ofcustomers, partition 1 ofsaleswith partition 1 ofcustomers, and so on. -
Reference partitioning is an easy way to co-partition two tables so that the optimizer can always consider a full partition-wise join if the tables are joined in a statement.
Parallel execution of a full partition-wise join is a straightforward parallelization of the serial execution. Instead of joining one partition pair at a time, partition pairs are joined in parallel by the query servers. Figure 3-1 illustrates the parallel execution of a full partition-wise join.
Figure 3-1 Parallel Execution of a Full Partition-wise Join
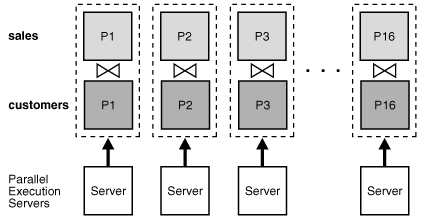
Description of "Figure 3-1 Parallel Execution of a Full Partition-wise Join"
The following example shows the execution plan for sales and customers co-partitioned by hash with the same number of partitions. The plan shows a full partition-wise join.
explain plan for SELECT c.cust_last_name, COUNT(*)
FROM sales s, customers c
WHERE s.cust_id = c.cust_id AND
s.time_id BETWEEN TO_DATE('01-JUL-1999', 'DD-MON-YYYY') AND
(TO_DATE('01-OCT-1999', 'DD-MON-YYYY'))
GROUP BY c.cust_last_name HAVING COUNT(*) > 100;
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 46 | 1196 | | | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 46 | 1196 | | | Q1,01 | P->S | QC (RAND) |
|* 3 | FILTER | | | | | | Q1,01 | PCWC | |
| 4 | HASH GROUP BY | | 46 | 1196 | | | Q1,01 | PCWP | |
| 5 | PX RECEIVE | | 46 | 1196 | | | Q1,01 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | 46 | 1196 | | | Q1,00 | P->P | HASH |
| 7 | HASH GROUP BY | | 46 | 1196 | | | Q1,00 | PCWP | |
| 8 | PX PARTITION HASH ALL| | 59158 | 1502K| 1 | 16 | Q1,00 | PCWC | |
|* 9 | HASH JOIN | | 59158 | 1502K| | | Q1,00 | PCWP | |
| 10 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 704K| 1 | 16 | Q1,00 | PCWP | |
|* 11 | TABLE ACCESS FULL | SALES | 59158 | 751K| 1 | 16 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
9 - access("S"."CUST_ID"="C"."CUST_ID")
11 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Note:
TheCost (%CPU) and Time columns were removed from the plan table output in this example.In Oracle RAC environments running on massive parallel processing (MPP) platforms, placing partitions on nodes is critical to achieving good scalability. To avoid remote I/O, both matching partitions should have affinity to the same node. Partition pairs should be spread over all of the nodes to avoid bottlenecks and to use all CPU resources available on the system.
Nodes can host multiple pairs when there are more pairs than nodes. For example, with an 8-node system and 16 partition pairs, each node receives two pairs.
See Also:
Oracle Real Application Clusters Administration and Deployment Guide for more information about data affinityFull Partition-Wise Joins: Composite - Single-Level
This method is a variation of the single-level - single-level method. In this scenario, one table (typically the larger table) is composite partitioned on two dimensions, using the join columns as the subpartition key. In the example, the sales table is a typical example of a table storing historical data. Using range partitioning is a logical initial partitioning method for a table storing historical information.
For example, assume you want to partition the sales table into eight partitions by range on the column time_id. Also assume you have two years and that each partition represents a quarter. Instead of using range partitioning, you can use composite partitioning to enable a full partition-wise join while preserving the partitioning on time_id. For example, partition the sales table by range on time_id and then subpartition each partition by hash on cust_id using 16 subpartitions for each partition, for a total of 128 subpartitions. The customers table can use hash partitioning with 16 partitions.
When you use the method just described, a full partition-wise join works similarly to the one created by a single-level - single-level hash-hash method. The join is still divided into 16 smaller joins between hash partition pairs from both tables. The difference is that now each hash partition in the sales table is composed of a set of 8 subpartitions, one from each range partition.
Figure 3-2 illustrates how the hash partitions are formed in the sales table. Each cell represents a subpartition. Each row corresponds to one range partition, for a total of 8 range partitions. Each range partition has 16 subpartitions. Each column corresponds to one hash partition for a total of 16 hash partitions; each hash partition has 8 subpartitions. Note that hash partitions can be defined only if all partitions have the same number of subpartitions, in this case, 16.
Hash partitions are implicit in a composite table. However, Oracle does not record them in the data dictionary, and you cannot manipulate them with DDL commands as you can range or list partitions.
Figure 3-2 Range and Hash Partitions of a Composite Table
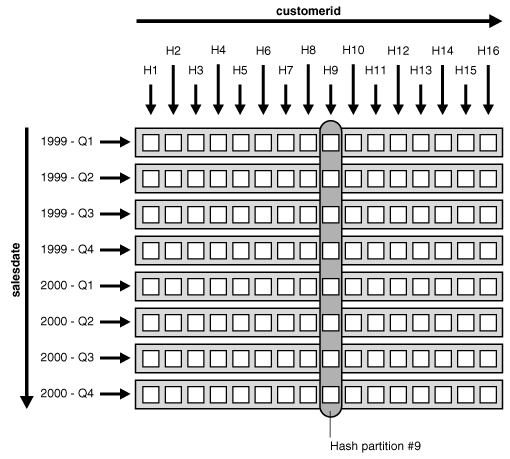
Description of "Figure 3-2 Range and Hash Partitions of a Composite Table"
The following example shows the execution plan for the full partition-wise join with the sales table range partitioned by time_id, and subpartitioned by hash on cust_id.
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Pstart| Pstop |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | | | P->S | QC (RAND) |
|* 3 | FILTER | | | | PCWC | |
| 4 | HASH GROUP BY | | | | PCWP | |
| 5 | PX RECEIVE | | | | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | | | P->P | HASH |
| 7 | HASH GROUP BY | | | | PCWP | |
| 8 | PX PARTITION HASH ALL | | 1 | 16 | PCWC | |
|* 9 | HASH JOIN | | | | PCWP | |
| 10 | TABLE ACCESS FULL | CUSTOMERS | 1 | 16 | PCWP | |
| 11 | PX PARTITION RANGE ITERATOR| | 8 | 9 | PCWC | |
|* 12 | TABLE ACCESS FULL | SALES | 113 | 144 | PCWP | |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
9 - access("S"."CUST_ID"="C"."CUST_ID")
12 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Note:
TheRows, Cost (%CPU), Time, and TQ columns were removed from the plan table output in this example.Composite - single-level partitioning is effective because it enables you to combine pruning on one dimension with a full partition-wise join on another dimension. In the previous example query, pruning is achieved by scanning only the subpartitions corresponding to Q3 of 1999, in other words, row number 3 in Figure 3-2. Oracle then joins these subpartitions with the customer table, using a full partition-wise join.
All characteristics of the single-level - single-level partition-wise join apply to the composite - single-level partition-wise join. In particular, for this example, these two points are common to both methods:
-
The degree of parallelism for this full partition-wise join cannot exceed 16. Even though the
salestable has 128 subpartitions, it has only 16 hash partitions. -
The rules for data placement on MPP systems apply here. The only difference is that a subpartition is now a collection of subpartitions. You must ensure that all of these subpartitions are placed on the same node as the matching hash partition from the other table. For example, in Figure 3-2, store hash partition 9 of the
salestable shown by the eight circled subpartitions, on the same node as hash partition 9 of thecustomerstable.
Full Partition-Wise Joins: Composite - Composite
If needed, you can also partition the customers table by the composite method. For example, you partition it by range on a postal code column to enable pruning based on postal codes. You then subpartition it by hash on cust_id using the same number of partitions (16) to enable a partition-wise join on the hash dimension.
You can get full partition-wise joins on all combinations of partition and subpartition partitions: partition - partition, partition - subpartition, subpartition - partition, and subpartition - subpartition.
Partial Partition-Wise Joins
Oracle Database can perform partial partition-wise joins only in parallel. Unlike full partition-wise joins, partial partition-wise joins require you to partition only one table on the join key, not both tables. The partitioned table is referred to as the reference table. The other table may or may not be partitioned. Partial partition-wise joins are more common than full partition-wise joins.
To execute a partial partition-wise join, the database dynamically repartitions the other table based on the partitioning of the reference table. After the other table is repartitioned, the execution is similar to a full partition-wise join.
The performance advantage that partial partition-wise joins have over joins in nonpartitioned tables is that the reference table is not moved during the join operation. Parallel joins between nonpartitioned tables require both input tables to be redistributed on the join key. This redistribution operation involves exchanging rows between parallel execution servers. This is a CPU-intensive operation that can lead to excessive interconnect traffic in Oracle RAC environments. Partitioning large tables on a join key, either a foreign or primary key, prevents this redistribution every time the table is joined on that key. Of course, if you choose a foreign key to partition the table, which is the most common scenario, then select a foreign key that is involved in many queries.
To illustrate partial partition-wise joins, consider the previous sales/customers example. Assume that customers is not partitioned or is partitioned on a column other than cust_id. Because sales is often joined with customers on cust_id, and because this join dominates our application workload, partition sales on cust_id to enable partial partition-wise joins every time customers and sales are joined. As with full partition-wise joins, you have several alternatives:
Partial Partition-Wise Joins: Single-Level Partitioning
The simplest method to enable a partial partition-wise join is to partition sales by hash on cust_id. The number of partitions determines the maximum degree of parallelism, because the partition is the smallest granule of parallelism for partial partition-wise join operations.
The parallel execution of a partial partition-wise join is illustrated in Figure 3-3, which assumes that both the degree of parallelism and the number of partitions of sales are 16. The execution involves two sets of query servers: one set, labeled set 1 in Figure 3-3, scans the customers table in parallel. The granule of parallelism for the scan operation is a range of blocks.
Rows from customers that are selected by the first set, in this case all rows, are redistributed to the second set of query servers by hashing cust_id. For example, all rows in customers that could have matching rows in partition P1 of sales are sent to query server 1 in the second set. Rows received by the second set of query servers are joined with the rows from the corresponding partitions in sales. Query server number 1 in the second set joins all customers rows that it receives with partition P1 of sales.
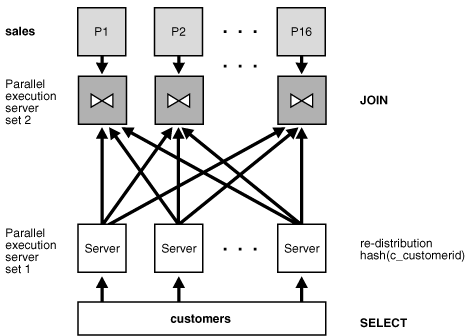
The example below shows the execution plan for the partial partition-wise join between sales and customers.
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Pstart| Pstop |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | | | P->S | QC (RAND) |
|* 3 | FILTER | | | | PCWC | |
| 4 | HASH GROUP BY | | | | PCWP | |
| 5 | PX RECEIVE | | | | PCWP | |
| 6 | PX SEND HASH | :TQ10001 | | | P->P | HASH |
| 7 | HASH GROUP BY | | | | PCWP | |
|* 8 | HASH JOIN | | | | PCWP | |
| 9 | PART JOIN FILTER CREATE | :BF0000 | | | PCWP | |
| 10 | PX RECEIVE | | | | PCWP | |
| 11 | PX SEND PARTITION (KEY) | :TQ10000 | | | P->P | PART (KEY) |
| 12 | PX BLOCK ITERATOR | | | | PCWC | |
| 13 | TABLE ACCESS FULL | CUSTOMERS | | | PCWP | |
| 14 | PX PARTITION HASH JOIN-FILTER| |:BF0000|:BF0000| PCWC | |
|* 15 | TABLE ACCESS FULL | SALES |:BF0000|:BF0000| PCWP | |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
8 - access("S"."CUST_ID"="C"."CUST_ID")
15 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Note that the query runs in parallel, as you can see in the plan because there are PX row sources. One table is partitioned, which is the SALES table. You can determine this because the PX PARTITION HASH row source contains a nonpartitioned table CUSTOMERS that is distributed through PX SEND PARTITION to a different slave set that performs the join.
Note:
TheRows, Cost (%CPU), Time, and TQ columns were removed from the plan table output in this example.Note:
This section is based on hash partitioning, but it also applies for range, list, and interval partial partition-wise joins.Considerations for full partition-wise joins also apply to partial partition-wise joins:
-
The degree of parallelism does not need to equal the number of partitions. In Figure 3-3, the query executes with two sets of 16 query servers. In this case, Oracle assigns 1 partition to each query server of the second set. Again, the number of partitions should always be a multiple of the degree of parallelism.
-
In Oracle RAC environments on MPPs, each hash partition of
salesshould preferably have affinity to only one node to avoid remote I/Os. Also, spread partitions over all nodes to avoid bottlenecks and use all CPU resources available on the system. A node can host multiple partitions when there are more partitions than nodes.See Also:
Oracle Real Application Clusters Administration and Deployment Guide for more information about data affinity
Partial Partition-Wise Joins: Composite
As with full partition-wise joins, the prime partitioning method for the sales table is to use the range method on column time_id. This is because sales is a typical example of a table that stores historical data. To enable a partial partition-wise join while preserving this range partitioning, subpartition sales by hash on column cust_id using 16 subpartitions for each partition. Both pruning and partial partition-wise joins can be used if a query joins customers and sales and if the query has a selection predicate on time_id.
When the sales table is composite partitioned, the granule of parallelism for a partial partition-wise join is a hash partition and not a subpartition. Refer to Figure 3-2 for an illustration of a hash partition in a composite table. Again, the number of hash partitions should be a multiple of the degree of parallelism. Also, on an MPP system, ensure that each hash partition has affinity to a single node. In the previous example, the eight subpartitions composing a hash partition should have affinity to the same node.
Note:
This section is based on range-hash, but it also applies for all other combinations of composite partial partition-wise joins.The following example shows the execution plan for the query between sales and customers with sales range partitioned by time_id and subpartitioned by hash on cust_id.
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Pstart| Pstop |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | | | P->S | QC (RAND) |
|* 3 | FILTER | | | | PCWC | |
| 4 | HASH GROUP BY | | | | PCWP | |
| 5 | PX RECEIVE | | | | PCWP | |
| 6 | PX SEND HASH | :TQ10001 | | | P->P | HASH |
| 7 | HASH GROUP BY | | | | PCWP | |
|* 8 | HASH JOIN | | | | PCWP | |
| 9 | PART JOIN FILTER CREATE | :BF0000 | | | PCWP | |
| 10 | PX RECEIVE | | | | PCWP | |
| 11 | PX SEND PARTITION (KEY) | :TQ10000 | | | P->P | PART (KEY) |
| 12 | PX BLOCK ITERATOR | | | | PCWC | |
| 13 | TABLE ACCESS FULL | CUSTOMERS | | | PCWP | |
| 14 | PX PARTITION RANGE ITERATOR| | 8 | 9 | PCWC | |
| 15 | PX PARTITION HASH ALL | | 1 | 16 | PCWC | |
|* 16 | TABLE ACCESS FULL | SALES | 113 | 144 | PCWP | |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
8 - access("S"."CUST_ID"="C"."CUST_ID")
16 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Note:
TheRows, Cost (%CPU), Time, and TQ columns were removed from the plan table output in this example.Index Partitioning
The rules for partitioning indexes are similar to those for tables:
-
An index can be partitioned unless:
-
The index is a cluster index.
-
The index is defined on a clustered table.
-
-
You can mix partitioned and nonpartitioned indexes with partitioned and nonpartitioned tables:
-
A partitioned table can have partitioned or nonpartitioned indexes.
-
A nonpartitioned table can have partitioned or nonpartitioned indexes.
-
-
Bitmap indexes on nonpartitioned tables cannot be partitioned.
-
A bitmap index on a partitioned table must be a local index.
However, partitioned indexes are more complicated than partitioned tables because there are three types of partitioned indexes:
-
Local prefixed
-
Local nonprefixed
-
Global prefixed
Oracle Database supports all three types. However, there are some restrictions. For example, a key cannot be an expression when creating a local unique index on a partitioned table.
This section discusses the following topics:
Local Partitioned Indexes
In a local index, all keys in a particular index partition refer only to rows stored in a single underlying table partition. A local index is created by specifying the LOCAL attribute.
Oracle constructs the local index so that it is equipartitioned with the underlying table. Oracle partitions the index on the same columns as the underlying table, creates the same number of partitions or subpartitions, and gives them the same partition bounds as corresponding partitions of the underlying table.
Oracle also maintains the index partitioning automatically when partitions in the underlying table are added, dropped, merged, or split, or when hash partitions or subpartitions are added or coalesced. This ensures that the index remains equipartitioned with the table.
A local index can be created UNIQUE if the partitioning columns form a subset of the index columns. This restriction guarantees that rows with identical index keys always map into the same partition, where uniqueness violations can be detected.
Local indexes have the following advantages:
-
Only one index partition must be rebuilt when a maintenance operation other than
SPLITPARTITIONorADDPARTITIONis performed on an underlying table partition. -
The duration of a partition maintenance operation remains proportional to partition size if the partitioned table has only local indexes.
-
Local indexes support partition independence.
-
Local indexes support smooth roll-out of old data and roll-in of new data in historical tables.
-
Oracle can take advantage of the fact that a local index is equipartitioned with the underlying table to generate better query access plans.
-
Local indexes simplify the task of tablespace incomplete recovery. To recover a partition or subpartition of a table to a point in time, you must also recover the corresponding index entries to the same point in time. The only way to accomplish this is with a local index. Then you can recover the corresponding table and index partitions or subpartitions.
This section contains the following topics:
See Also:
Oracle Database PL/SQL Packages and Types Reference for a description of theDBMS_PCLXUTIL packageLocal Prefixed Indexes
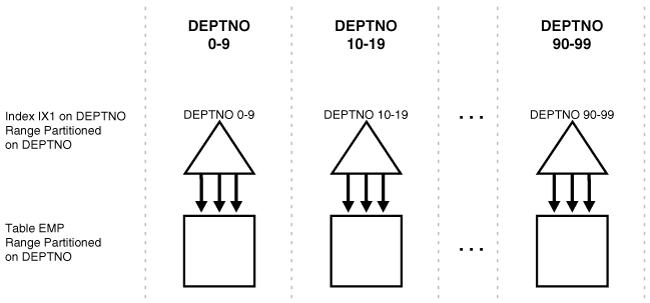
A local index is prefixed if it is partitioned on a left prefix of the index columns and the subpartioning key is included in the index key. Local prefixed indexes can be unique or nonunique.
For example, if the sales table and its local index sales_ix are partitioned on the week_num column, then index sales_ix is local prefixed if it is defined on the columns (week_num, xaction_num). On the other hand, if index sales_ix is defined on column product_num then it is not prefixed.
Figure 3-4 illustrates another example of a local prefixed index.
Local Nonprefixed Indexes
A local index is nonprefixed if it is not partitioned on a left prefix of the index columns or if the index key does not include the subpartitioning key. You cannot have a unique local nonprefixed index unless the partitioning key is a subset of the index key.
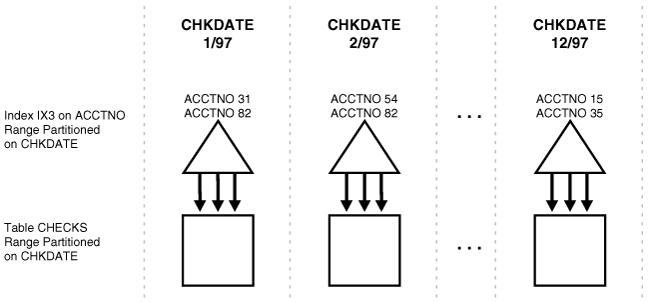
Figure 3-5 illustrates an example of a local nonprefixed index.
Global Partitioned Indexes
In a global partitioned index, the keys in a particular index partition may refer to rows stored in multiple underlying table partitions or subpartitions. A global index can be range or hash partitioned, though it can be defined on any type of partitioned table.
A global index is created by specifying the GLOBAL attribute. The database administrator is responsible for defining the initial partitioning of a global index at creation and for maintaining the partitioning over time. Index partitions can be merged or split as necessary.
Normally, a global index is not equipartitioned with the underlying table. There is nothing to prevent an index from being equipartitioned with the underlying table, but Oracle does not take advantage of the equipartitioning when generating query plans or executing partition maintenance operations. So an index that is equipartitioned with the underlying table should be created as LOCAL.
A global partitioned index contains a single B-tree with entries for all rows in all partitions. Each index partition may contain keys that refer to many different partitions or subpartitions in the table.
The highest partition of a global index must have a partition bound that includes all values that are MAXVALUE. This insures that all rows in the underlying table can be represented in the index.
This section contains the following topics:
Prefixed and Nonprefixed Global Partitioned Indexes
A global partitioned index is prefixed if it is partitioned on a left prefix of the index columns.A global partitioned index is nonprefixed if it is not partitioned on a left prefix of the index columns. Oracle does not support global nonprefixed partitioned indexes. See Figure 3-6 for an example.
Global prefixed partitioned indexes can be unique or nonunique. Nonpartitioned indexes are treated as global prefixed nonpartitioned indexes.
Management of Global Partitioned Indexes
Global partitioned indexes are harder to manage than local indexes because of the following:
-
When the data in an underlying table partition is moved or removed (
SPLIT,MOVE,DROP, orTRUNCATE), all partitions of a global index are affected. Consequently global indexes do not support partition independence. -
When an underlying table partition or subpartition is recovered to a point in time, all corresponding entries in a global index must be recovered to the same point in time. Because these entries may be scattered across all partitions or subpartitions of the index, mixed with entries for other partitions or subpartitions that are not being recovered, there is no way to accomplish this except by re-creating the entire global index.
Figure 3-6 Global Prefixed Partitioned Index
Description of "Figure 3-6 Global Prefixed Partitioned Index"
Summary of Partitioned Index Types
Table 3-1 summarizes the types of partitioned indexes that Oracle supports. The key points are:
-
If an index is local, then it is equipartitioned with the underlying table. Otherwise, it is global.
-
A prefixed index is partitioned on a left prefix of the index columns. Otherwise, it is nonprefixed.
Table 3-1 Types of Partitioned Indexes
| Type of Index | Index Equipartitioned with Table | Index Partitioned on Left Prefix of Index Columns | UNIQUE Attribute Allowed | Example: Table Partitioning Key | Example: Index Columns | Example: Index Partitioning Key |
|---|---|---|---|---|---|---|
|
Local Prefixed (any partitioning method) |
Yes |
Yes |
Yes |
A |
A, B |
A |
|
Local Nonprefixed (any partitioning method) |
Yes |
No |
YesFoot 1 |
A |
B, A |
A |
|
Global Prefixed (range partitioning only) |
NoFoot 2 |
Yes |
Yes |
A |
B |
B |
Footnote 1 For a unique local nonprefixed index, the partitioning key must be a subset of the index key.
Footnote 2 Although a global partitioned index may be equipartitioned with the underlying table, Oracle does not take advantage of the partitioning or maintain equipartitioning after partition maintenance operations such as DROP or SPLIT PARTITION.
The Importance of Nonprefixed Indexes
Nonprefixed indexes are particularly useful in historical databases. In a table containing historical data, it is common for an index to be defined on one column to support the requirements of fast access by that column. However, the index can also be partitioned on another column (the same column as the underlying table) to support the time interval for rolling out old data and rolling in new data.
Consider a sales table partitioned by week. It contains a year's worth of data, divided into 13 partitions. It is range partitioned on week_no, four weeks to a partition. You might create a nonprefixed local index sales_ix on sales. The sales_ix index is defined on acct_no because there are queries that need fast access to the data by account number. However, it is partitioned on week_no to match the sales table. Every four weeks, the oldest partitions of sales and sales_ix are dropped and new ones are added.
Performance Implications of Prefixed and Nonprefixed Indexes
It is more expensive to probe into a nonprefixed index than to probe into a prefixed index. If an index is prefixed (either local or global) and Oracle is presented with a predicate involving the index columns, then partition pruning can restrict application of the predicate to a subset of the index partitions.
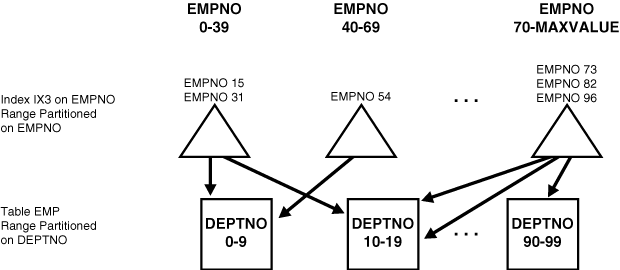
For example, in Figure 3-4, if the predicate is deptno=15, the optimizer knows to apply the predicate only to the second partition of the index. (If the predicate involves a bind variable, the optimizer does not know exactly which partition but it may still know there is only one partition involved, in which case at run time, only one index partition is accessed.)
When an index is nonprefixed, Oracle often has to apply a predicate involving the index columns to all N index partitions. This is required to look up a single key, or to do an index range scan. For a range scan, Oracle must also combine information from N index partitions. For example, in Figure 3-5, a local index is partitioned on chkdate with an index key on acctno. If the predicate is acctno=31, Oracle probes all 12 index partitions.
Of course, if there is also a predicate on the partitioning columns, then multiple index probes might not be necessary. Oracle takes advantage of the fact that a local index is equipartitioned with the underlying table to prune partitions based on the partition key. For example, if the predicate in Figure 3-4 is chkdate<3/97, Oracle only has to probe two partitions.
So for a nonprefixed index, if the partition key is a part of the WHERE clause but not of the index key, then the optimizer determines which index partitions to probe based on the underlying table partition.
When many queries and DML statements using keys of local, nonprefixed, indexes have to probe all index partitions, this effectively reduces the degree of partition independence provided by such indexes.
Table 3-2 Comparing Prefixed Local, Nonprefixed Local, and Global Indexes
| Index Characteristics | Prefixed Local | Nonprefixed Local | Global |
|---|---|---|---|
|
Unique possible? |
Yes |
Yes |
Yes. Must be global if using indexes on columns other than the partitioning columns |
|
Manageability |
Easy to manage |
Easy to manage |
Harder to manage |
|
OLTP |
Good |
Bad |
Good |
|
Long Running (DSS) |
Good |
Good |
Not Good |
Guidelines for Partitioning Indexes
When deciding how to partition indexes on a table, consider the mix of applications that must access the table. There is a trade-off between performance and availability and manageability. Here are some guidelines you should consider:
-
-
Global indexes and local prefixed indexes provide better performance than local nonprefixed indexes because they minimize the number of index partition probes.
-
Local indexes support more availability when there are partition or subpartition maintenance operations on the table. Local nonprefixed indexes are very useful for historical databases.
-
-
For DSS applications, local nonprefixed indexes can improve performance because many index partitions can be scanned in parallel by range queries on the index key.
For example, a query using the predicate "
acctnobetween 40 and 45" on the tablechecksof Figure 3-4 causes parallel scans of all the partitions of the nonprefixed indexix3. On the other hand, a query using the predicatedeptno BETWEEN 40 AND 45on the tabledeptnoof Figure 3-5 cannot be parallelized because it accesses a single partition of the prefixed indexix1. -
For historical tables, indexes should be local if possible. This limits the effect of regularly scheduled drop partition operations.
-
Unique indexes on columns other than the partitioning columns must be global because unique local nonprefixed indexes whose keys do not contain the partitioning key are not supported.
-
Unusable indexes do not consume space. See Oracle Database Administrator's Guide for more information.
Physical Attributes of Index Partitions
Default physical attributes are initially specified when a CREATE INDEX statement creates a partitioned index. Because there is no segment corresponding to the partitioned index itself, these attributes are only used in derivation of physical attributes of member partitions. Default physical attributes can later be modified using ALTER INDEX MODIFY DEFAULT ATTRIBUTES.
Physical attributes of partitions created by CREATE INDEX are determined as follows:
-
Values of physical attributes specified (explicitly or by default) for the index are used whenever the value of a corresponding partition attribute is not specified. Handling of the
TABLESPACEattribute of partitions of aLOCALindex constitutes an important exception to this rule in that without a user-specifiedTABLESPACEvalue (at both partition and index levels), the value of the physical attribute of the corresponding partition of the underlying table is used. -
Physical attributes (other than
TABLESPACE, as explained in the preceding) of partitions of local indexes created during processingALTERTABLEADDPARTITIONare set to the default physical attributes of each index.
Physical attributes (other than TABLESPACE) of index partitions created by ALTER TABLE SPLIT PARTITION are determined as follows:
-
Values of physical attributes of the index partition being split are used.
Physical attributes of an existing index partition can be modified by ALTER INDEX MODIFY PARTITION and ALTER INDEX REBUILD PARTITION. Resulting attributes are determined as follows:
-
Values of physical attributes of the partition before the statement was issued are used whenever a new value is not specified. Note that
ALTERINDEXREBUILD PARTITIONcan change the tablespace in which a partition resides.
Physical attributes of global index partitions created by ALTER INDEX SPLIT PARTITION are determined as follows:
-
Values of physical attributes of the partition being split are used whenever a new value is not specified.
-
Physical attributes of all partitions of an index (along with default values) may be modified by
ALTERINDEX, for example,ALTERINDEXindexnameNOLOGGINGchanges the logging mode of all partitions ofindexnametoNOLOGGING.
For more detailed examples of adding partitions and examples of rebuilding indexes, refer to Chapter 4, "Partition Administration".
Partitioning and Table Compression
You can compress several partitions or a complete partitioned heap-organized table. You do this by either defining a complete partitioned table as being compressed, or by defining it on a per-partition level. Partitions without a specific declaration inherit the attribute from the table definition or, if nothing is specified on table level, from the tablespace definition.
The decision whether a partition should be compressed or uncompressed adheres to the same rules as a nonpartitioned table. However, due to the capability of range and composite partitioning to separate data logically into distinct partitions, such a partitioned table is an ideal candidate for compressing parts of the data (partitions) that are mainly read-only. For example, it is beneficial in all rolling window operations as a intermediate stage before aging out old data. With data segment compression, you can keep more old data online, minimizing the burden of additional storage consumption.
You can also change any existing uncompressed table partition later on, add new compressed and uncompressed partitions, or change the compression attribute as part of any partition maintenance operation that requires data movement, such as MERGE PARTITION, SPLIT PARTITION, or MOVE PARTITION. The partitions can contain data or can be empty.
The access and maintenance of a partially or fully compressed partitioned table are the same as for a fully uncompressed partitioned table. Everything that applies to fully uncompressed partitioned tables is also valid for partially or fully compressed partitioned tables.
This section contains the following topics:
See Also:
-
Oracle Database Data Warehousing Guide for a generic discussion of table compression
-
Oracle Database Administrator's Guide for more detailed information
-
Oracle Database Performance Tuning Guide for an example of calculating the compression ratio
Table Compression and Bitmap Indexes
To use table compression on partitioned tables with bitmap indexes, you must do the following before you introduce the compression attribute for the first time:
-
Mark bitmap indexes unusable.
-
Set the compression attribute.
-
Rebuild the indexes.
The first time you make a compressed partition part of an existing, fully uncompressed partitioned table, you must either drop all existing bitmap indexes or mark them UNUSABLE before adding a compressed partition. This must be done irrespective of whether any partition contains any data. It is also independent of the operation that causes one or more compressed partitions to become part of the table. This does not apply to a partitioned table having B-tree indexes only.
This rebuilding of the bitmap index structures is necessary to accommodate the potentially higher number of rows stored for each data block with table compression enabled. Enabling table compression must be done only for the first time. All subsequent operations, whether they affect compressed or uncompressed partitions, or change the compression attribute, behave identically for uncompressed, partially compressed, or fully compressed partitioned tables.
To avoid the recreation of any bitmap index structure, Oracle recommends creating every partitioned table with at least one compressed partition whenever you plan to partially or fully compress the partitioned table in the future. This compressed partition can stay empty or even can be dropped after the partition table creation.
Having a partitioned table with compressed partitions can lead to slightly larger bitmap index structures for the uncompressed partitions. The bitmap index structures for the compressed partitions, however, are usually smaller than the appropriate bitmap index structure before table compression. This highly depends on the achieved compression rates.
Note:
Oracle Database raises an error if compression is introduced to an object for the first time and there are usable bitmap index segments.Example of Table Compression and Partitioning
The following statement moves and compresses an existing partition sales_q1_1998 of table sales:
ALTER TABLE sales MOVE PARTITION sales_q1_1998 TABLESPACE ts_arch_q1_1998 COMPRESS;
Alternatively, you could choose Hybrid Columnar Compression (HCC), as in the following:
ALTER TABLE sales MOVE PARTITION sales_q1_1998 TABLESPACE ts_arch_q1_1998 COMPRESS FOR ARCHIVE LOW;
If you use the MOVE statement, then the local indexes for partition sales_q1_1998 become unusable. You must rebuild them afterward, as follows:
ALTER TABLE sales MODIFY PARTITION sales_q1_1998 REBUILD UNUSABLE LOCAL INDEXES;
You can also include the UPDATE INDEXES clause in the MOVE statement in order for the entire operation to be completed automatically without any negative effect on users accessing the table.
The following statement merges two existing partitions into a new, compressed partition, residing in a separate tablespace. The local bitmap indexes have to be rebuilt afterward, as in the following:
ALTER TABLE sales MERGE PARTITIONS sales_q1_1998, sales_q2_1998 INTO PARTITION sales_1_1998 TABLESPACE ts_arch_1_1998 COMPRESS FOR OLTP UPDATE INDEXES;
For more details and examples for partition management operations, refer to Chapter 4, "Partition Administration".
See Also:
-
Oracle Database Performance Tuning Guide for details regarding how to estimate the compression ratio when using table compression
-
Oracle Database SQL Language Reference for the SQL syntax
-
Oracle Database Concepts for more information about Hybrid Columnar Compression. Hybrid Columnar Compression is a feature of certain Oracle storage systems.
-
Oracle Database Administrator's Guide for information about changing the compression level using online redefinition
Recommendations for Choosing a Partitioning Strategy
The following sections provide recommendations for choosing a partitioning strategy:
When to Use Range or Interval Partitioning
Range partitioning is a convenient method for partitioning historical data. The boundaries of range partitions define the ordering of the partitions in the tables or indexes.
Interval partitioning is an extension to range partitioning in which, beyond a point in time, partitions are defined by an interval. Interval partitions are automatically created by the database when data is inserted into the partition.
Range or interval partitioning is often used to organize data by time intervals on a column of type DATE. Thus, most SQL statements accessing range partitions focus on timeframes. An example of this is a SQL statement similar to "select data from a particular period in time". In such a scenario, if each partition represents data for one month, the query "find data of month 06-DEC" must access only the December partition of year 2006. This reduces the amount of data scanned to a fraction of the total data available, an optimization method called partition pruning.
Range partitioning is also ideal when you periodically load new data and purge old data, because it is easy to add or drop partitions. For example, it is common to keep a rolling window of data, keeping the past 36 months' worth of data online. Range partitioning simplifies this process. To add data from a new month, you load it into a separate table, clean it, index it, and then add it to the range-partitioned table using the EXCHANGE PARTITION statement, all while the original table remains online. After you add the new partition, you can drop the trailing month with the DROP PARTITION statement. The alternative to using the DROP PARTITION statement can be to archive the partition and make it read only, but this works only when your partitions are in separate tablespaces. You can also implement a rolling window of data using inserts into the partitioned table.
Interval partitioning provides an easy way for interval partitions to be automatically created as data arrives. Interval partitions can also be used for all other partition maintenance operations. Refer to Chapter 4, "Partition Administration" for more information about the partition maintenance operations on interval partitions.
In conclusion, consider using range or interval partitioning when:
-
Very large tables are frequently scanned by a range predicate on a good partitioning column, such as
ORDER_DATEorPURCHASE_DATE. Partitioning the table on that column enables partition pruning. -
You want to maintain a rolling window of data.
-
You cannot complete administrative operations, such as backup and restore, on large tables in an allotted time frame, but you can divide them into smaller logical pieces based on the partition range column.
Example 3-3 creates the table salestable for a period of two years, 2005 and 2006, and partitions it by range according to the column s_salesdate to separate the data into eight quarters, each corresponding to a partition. Future partitions are created automatically through the monthly interval definition. Interval partitions are created in the provided list of tablespaces in a round-robin manner. Analysis of sales figures by a short interval can take advantage of partition pruning. The sales table also supports a rolling window approach.
Example 3-3 Creating a table with range and interval partitioning
CREATE TABLE salestable
(s_productid NUMBER,
s_saledate DATE,
s_custid NUMBER,
s_totalprice NUMBER)
PARTITION BY RANGE(s_saledate)
INTERVAL(NUMTOYMINTERVAL(1,'MONTH')) STORE IN (tbs1,tbs2,tbs3,tbs4)
(PARTITION sal05q1 VALUES LESS THAN (TO_DATE('01-APR-2005', 'DD-MON-YYYY'))
TABLESPACE tbs1,
PARTITION sal05q2 VALUES LESS THAN (TO_DATE('01-JUL-2005', 'DD-MON-YYYY'))
TABLESPACE tbs2,
PARTITION sal05q3 VALUES LESS THAN (TO_DATE('01-OCT-2005', 'DD-MON-YYYY'))
TABLESPACE tbs3,
PARTITION sal05q4 VALUES LESS THAN (TO_DATE('01-JAN-2006', 'DD-MON-YYYY'))
TABLESPACE tbs4,
PARTITION sal06q1 VALUES LESS THAN (TO_DATE('01-APR-2006', 'DD-MON-YYYY'))
TABLESPACE tbs1,
PARTITION sal06q2 VALUES LESS THAN (TO_DATE('01-JUL-2006', 'DD-MON-YYYY'))
TABLESPACE tbs2,
PARTITION sal06q3 VALUES LESS THAN (TO_DATE('01-OCT-2006', 'DD-MON-YYYY'))
TABLESPACE tbs3,
PARTITION sal06q4 VALUES LESS THAN (TO_DATE('01-JAN-2007', 'DD-MON-YYYY'))
TABLESPACE tbs4);
When to Use Hash Partitioning
There are times when it is not obvious in which partition data should reside, although the partitioning key can be identified. Rather than group similar data, there are times when it is desirable to distribute data such that it does not correspond to a business or a logical view of the data, as it does in range partitioning. With hash partitioning, a row is placed into a partition based on the result of passing the partitioning key into a hashing algorithm.
Using this approach, data is randomly distributed across the partitions rather than grouped. This is a good approach for some data, but may not be an effective way to manage historical data. However, hash partitions share some performance characteristics with range partitions. For example, partition pruning is limited to equality predicates. You can also use partition-wise joins, parallel index access, and parallel DML. See "Partition-Wise Joins" for more information.
As a general rule, use hash partitioning for the following purposes:
-
To enable partial or full parallel partition-wise joins with likely equisized partitions.
-
To distribute data evenly among the nodes of an MPP platform that uses Oracle Real Application Clusters. Consequently, you can minimize interconnect traffic when processing internode parallel statements.
-
To use partition pruning and partition-wise joins according to a partitioning key that is mostly constrained by a distinct value or value list.
-
To randomly distribute data to avoid I/O bottlenecks if you do not use a storage management technique that stripes and mirrors across all available devices.
For more information, refer to Chapter 10, "Storage Management for VLDBs".
Note:
With hash partitioning, only equality orIN-list predicates are supported for partition pruning.For optimal data distribution, the following requirements should be satisfied:
-
Choose a column or combination of columns that is unique or almost unique.
-
Create multiple partitions and subpartitions for each partition that is a power of two. For example, 2, 4, 8, 16, 32, 64, 128, and so on.
Example 3-4 creates four hash partitions for the table sales_hash using the column s_productid as the partitioning key. Parallel joins with the products table can take advantage of partial or full partition-wise joins. Queries accessing sales figures for only a single product or a list of products benefit from partition pruning.
Example 3-4 Creating a table with hash partitioning
CREATE TABLE sales_hash (s_productid NUMBER, s_saledate DATE, s_custid NUMBER, s_totalprice NUMBER) PARTITION BY HASH(s_productid) ( PARTITION p1 TABLESPACE tbs1 , PARTITION p2 TABLESPACE tbs2 , PARTITION p3 TABLESPACE tbs3 , PARTITION p4 TABLESPACE tbs4 );
If you do not explicitly specify partition names, but instead you specify the number of hash partitions, then Oracle automatically generates internal names for the partitions. Also, you can use the STORE IN clause to assign hash partitions to tablespaces in a round-robin manner. For more examples, refer to Chapter 4, "Partition Administration".
See Also:
Oracle Database SQL Language Reference for partitioning syntaxWhen to Use List Partitioning
You should use list partitioning when you want to specifically map rows to partitions based on discrete values. In Example 3-5, all the customers for states Oregon and Washington are stored in one partition and customers in other states are stored in different partitions. Account managers who analyze their accounts by region can take advantage of partition pruning.
Example 3-5 Creating a table with list partitioning
CREATE TABLE accounts
( id NUMBER
, account_number NUMBER
, customer_id NUMBER
, branch_id NUMBER
, region VARCHAR(2)
, status VARCHAR2(1)
)
PARTITION BY LIST (region)
( PARTITION p_northwest VALUES ('OR', 'WA')
, PARTITION p_southwest VALUES ('AZ', 'UT', 'NM')
, PARTITION p_northeast VALUES ('NY', 'VM', 'NJ')
, PARTITION p_southeast VALUES ('FL', 'GA')
, PARTITION p_northcentral VALUES ('SD', 'WI')
, PARTITION p_southcentral VALUES ('OK', 'TX')
);
Unlike range and hash partitioning, multi-column partition keys are not supported for list partitioning. If a table is partitioned by list, the partitioning key can only consist of a single column of the table.
When to Use Composite Partitioning
Composite partitioning offers the benefits of partitioning on two dimensions. From a performance perspective you can take advantage of partition pruning on one or two dimensions depending on the SQL statement, and you can take advantage of the use of full or partial partition-wise joins on either dimension.
You can take advantage of parallel backup and recovery of a single table. Composite partitioning also increases the number of partitions significantly, which may be beneficial for efficient parallel execution. From a manageability perspective, you can implement a rolling window to support historical data and still partition on another dimension if many statements can benefit from partition pruning or partition-wise joins.
You can split backups of your tables and you can decide to store data differently based on identification by a partitioning key. For example, you may decide to store data for a specific product type in a read-only, compressed format, and keep other product type data uncompressed.
The database stores every subpartition in a composite partitioned table as a separate segment. Thus, the subpartitions may have properties that differ from the properties of the table or from the partition to which the subpartitions belong.
This section contains the following topics:
See Also:
Oracle Database SQL Language Reference for details regarding syntax and restrictionsWhen to Use Composite Range-Hash Partitioning
Composite range-hash partitioning is particularly common for tables that store history, are very large consequently, and are frequently joined with other large tables. For these types of tables (typical of data warehouse systems), composite range-hash partitioning provides the benefit of partition pruning at the range level with the opportunity to perform parallel full or partial partition-wise joins at the hash level. Specific cases can benefit from partition pruning on both dimensions for specific SQL statements.
Composite range-hash partitioning can also be used for tables that traditionally use hash partitioning, but also use a rolling window approach. Over time, data can be moved from one storage tier to another storage tier, compressed, stored in a read-only tablespace, and eventually purged. Information Lifecycle Management (ILM) scenarios often use range partitions to implement a tiered storage approach. See Chapter 5, "Using Partitioning for Information Lifecycle Management" for more details.
Example 3-6 is an example of a range-hash partitioned page_history table of an Internet service provider. The table definition is optimized for historical analysis for either specific client_ip values (in which case queries benefit from partition pruning) or for analysis across many IP addresses, in which case queries can take advantage of full or partial partition-wise joins.
Example 3-6 Creating a table with composite range-hash partitioning
CREATE TABLE page_history
( id NUMBER NOT NULL
, url VARCHAR2(300) NOT NULL
, view_date DATE NOT NULL
, client_ip VARCHAR2(23) NOT NULL
, from_url VARCHAR2(300)
, to_url VARCHAR2(300)
, timing_in_seconds NUMBER
) PARTITION BY RANGE(view_date) INTERVAL (NUMTODSINTERVAL(1,'DAY'))
SUBPARTITION BY HASH(client_ip)
SUBPARTITIONS 32
(PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-2006','dd-MON-yyyy')))
PARALLEL 32 COMPRESS;
This example shows the use of interval partitioning. Interval partitioning can be used in addition to range partitioning in order for interval partitions to be created automatically as data is inserted into the table.
When to Use Composite Range-List Partitioning
Composite range-list partitioning is commonly used for large tables that store historical data and are commonly accessed on multiple dimensions. Often the historical view of the data is one access path, but certain business cases add another categorization to the access path. For example, regional account managers are very interested in how many new customers they signed up in their region in a specific time period. ILM and its tiered storage approach is a common reason to create range-list partitioned tables so that older data can be moved and compressed, but partition pruning on the list dimension is still available.
Example 3-7 creates a range-list partitioned call_detail_records table. A telecommunication company can use this table to analyze specific types of calls over time. The table uses local indexes on from_number and to_number.
Example 3-7 Creating a table with composite range-list partitioning
CREATE TABLE call_detail_records
( id NUMBER
, from_number VARCHAR2(20)
, to_number VARCHAR2(20)
, date_of_call DATE
, distance VARCHAR2(1)
, call_duration_in_s NUMBER(4)
) PARTITION BY RANGE(date_of_call)
INTERVAL (NUMTODSINTERVAL(1,'DAY'))
SUBPARTITION BY LIST(distance)
SUBPARTITION TEMPLATE
( SUBPARTITION local VALUES('L') TABLESPACE tbs1
, SUBPARTITION medium_long VALUES ('M') TABLESPACE tbs2
, SUBPARTITION long_distance VALUES ('D') TABLESPACE tbs3
, SUBPARTITION international VALUES ('I') TABLESPACE tbs4
)
(PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-2005','dd-MON-yyyy')))
PARALLEL;
CREATE INDEX from_number_ix ON call_detail_records(from_number)
LOCAL PARALLEL NOLOGGING;
CREATE INDEX to_number_ix ON call_detail_records(to_number)
LOCAL PARALLEL NOLOGGING;
This example shows the use of interval partitioning. Interval partitioning can be used in addition to range partitioning in order for interval partitions to be created automatically as data is inserted into the table.
When to Use Composite Range-Range Partitioning
Composite range-range partitioning is useful for applications that store time-dependent data on multiple time dimensions. Often these applications do not use one particular time dimension to access the data, but rather another time dimension, or sometimes both at the same time. For example, a web retailer wants to analyze its sales data based on when orders were placed, and when orders were shipped (handed over to the shipping company).
Other business cases for composite range-range partitioning include ILM scenarios, and applications that store historical data and want to categorize its data by range on another dimension.
Example 3-8 shows a range-range partitioned table account_balance_history. A bank may use access to individual subpartitions to contact its customers for low-balance reminders or specific promotions relevant to a certain category of customers.
Example 3-8 Creating a table with composite range-range partitioning
CREATE TABLE account_balance_history
( id NUMBER NOT NULL
, account_number NUMBER NOT NULL
, customer_id NUMBER NOT NULL
, transaction_date DATE NOT NULL
, amount_credited NUMBER
, amount_debited NUMBER
, end_of_day_balance NUMBER NOT NULL
) PARTITION BY RANGE(transaction_date)
INTERVAL (NUMTODSINTERVAL(7,'DAY'))
SUBPARTITION BY RANGE(end_of_day_balance)
SUBPARTITION TEMPLATE
( SUBPARTITION unacceptable VALUES LESS THAN (-1000)
, SUBPARTITION credit VALUES LESS THAN (0)
, SUBPARTITION low VALUES LESS THAN (500)
, SUBPARTITION normal VALUES LESS THAN (5000)
, SUBPARTITION high VALUES LESS THAN (20000)
, SUBPARTITION extraordinary VALUES LESS THAN (MAXVALUE)
)
(PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-2007','dd-MON-yyyy')));
This example shows the use of interval partitioning. Interval partitioning can be used in addition to range partitioning in order for interval partitions to be created automatically as data is inserted into the table. In this case 7-day (weekly) intervals are created, starting Monday, January 1, 2007.
When to Use Composite List-Hash Partitioning
Composite list-hash partitioning is useful for large tables that are usually accessed on one dimension, but (due to their size) still must take advantage of parallel full or partial partition-wise joins on another dimension in joins with other large tables.
Example 3-9 shows a credit_card_accounts table. The table is list-partitioned on region in order for account managers to quickly access accounts in their region. The subpartitioning strategy is hash on customer_id so that queries against the transactions table, which is subpartitioned on customer_id, can take advantage of full partition-wise joins. Joins with the hash-partitioned customers table can also benefit from full partition-wise joins. The table has a local bitmap index on the is_active column.
Example 3-9 Creating a table with composite list-hash partitioning
CREATE TABLE credit_card_accounts
( account_number NUMBER(16) NOT NULL
, customer_id NUMBER NOT NULL
, customer_region VARCHAR2(2) NOT NULL
, is_active VARCHAR2(1) NOT NULL
, date_opened DATE NOT NULL
) PARTITION BY LIST (customer_region)
SUBPARTITION BY HASH (customer_id)
SUBPARTITIONS 16
( PARTITION emea VALUES ('EU','ME','AF')
, PARTITION amer VALUES ('NA','LA')
, PARTITION apac VALUES ('SA','AU','NZ','IN','CH')
) PARALLEL;
CREATE BITMAP INDEX is_active_bix ON credit_card_accounts(is_active)
LOCAL PARALLEL NOLOGGING;
When to Use Composite List-List Partitioning
Composite list-list partitioning is useful for large tables that are often accessed on different dimensions. You can specifically map rows to partitions on those dimensions based on discrete values.
Example 3-10 shows an example of a very frequently accessed current_inventory table. The table is constantly updated with the current inventory in the supermarket supplier's local warehouses. Potentially perishable foods are supplied from those warehouses to supermarkets, and it is important to optimize supplies and deliveries. The table has local indexes on warehouse_id and product_id.
Example 3-10 Creating a table with composite list-list partitioning
CREATE TABLE current_inventory
( warehouse_id NUMBER
, warehouse_region VARCHAR2(2)
, product_id NUMBER
, product_category VARCHAR2(12)
, amount_in_stock NUMBER
, unit_of_shipping VARCHAR2(20)
, products_per_unit NUMBER
, last_updated DATE
) PARTITION BY LIST (warehouse_region)
SUBPARTITION BY LIST (product_category)
SUBPARTITION TEMPLATE
( SUBPARTITION perishable VALUES ('DAIRY','PRODUCE','MEAT','BREAD')
, SUBPARTITION non_perishable VALUES ('CANNED','PACKAGED')
, SUBPARTITION durable VALUES ('TOYS','KITCHENWARE')
)
( PARTITION p_northwest VALUES ('OR', 'WA')
, PARTITION p_southwest VALUES ('AZ', 'UT', 'NM')
, PARTITION p_northeast VALUES ('NY', 'VM', 'NJ')
, PARTITION p_southeast VALUES ('FL', 'GA')
, PARTITION p_northcentral VALUES ('SD', 'WI')
, PARTITION p_southcentral VALUES ('OK', 'TX')
);
CREATE INDEX warehouse_id_ix ON current_inventory(warehouse_id)
LOCAL PARALLEL NOLOGGING;
CREATE INDEX product_id_ix ON current_inventory(product_id)
LOCAL PARALLEL NOLOGGING;
When to Use Composite List-Range Partitioning
Composite list-range partitioning is useful for large tables that are accessed on different dimensions. For the most commonly used dimension, you can specifically map rows to partitions on discrete values. List-range partitioning is commonly used for tables that use range values within a list partition, whereas range-list partitioning is commonly used for a discrete list values within a range partition. List-range partitioning is less commonly used to store historical data, even though equivalent scenarios are all suitable. Range-list partitioning can be implemented using interval-list partitioning, whereas list-range partitioning does not support interval partitioning.
Example 3-11 shows a donations table that stores donations in different currencies. The donations are categorized into small, medium, and high, depending on the amount. Due to currency differences, the ranges are different.
Example 3-11 Creating a table with composite list-range partitioning
CREATE TABLE donations
( id NUMBER
, name VARCHAR2(60)
, beneficiary VARCHAR2(80)
, payment_method VARCHAR2(30)
, currency VARCHAR2(3)
, amount NUMBER
) PARTITION BY LIST (currency)
SUBPARTITION BY RANGE (amount)
( PARTITION p_eur VALUES ('EUR')
( SUBPARTITION p_eur_small VALUES LESS THAN (8)
, SUBPARTITION p_eur_medium VALUES LESS THAN (80)
, SUBPARTITION p_eur_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_gbp VALUES ('GBP')
( SUBPARTITION p_gbp_small VALUES LESS THAN (5)
, SUBPARTITION p_gbp_medium VALUES LESS THAN (50)
, SUBPARTITION p_gbp_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_aud_nzd_chf VALUES ('AUD','NZD','CHF')
( SUBPARTITION p_aud_nzd_chf_small VALUES LESS THAN (12)
, SUBPARTITION p_aud_nzd_chf_medium VALUES LESS THAN (120)
, SUBPARTITION p_aud_nzd_chf_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_jpy VALUES ('JPY')
( SUBPARTITION p_jpy_small VALUES LESS THAN (1200)
, SUBPARTITION p_jpy_medium VALUES LESS THAN (12000)
, SUBPARTITION p_jpy_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_inr VALUES ('INR')
( SUBPARTITION p_inr_small VALUES LESS THAN (400)
, SUBPARTITION p_inr_medium VALUES LESS THAN (4000)
, SUBPARTITION p_inr_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_zar VALUES ('ZAR')
( SUBPARTITION p_zar_small VALUES LESS THAN (70)
, SUBPARTITION p_zar_medium VALUES LESS THAN (700)
, SUBPARTITION p_zar_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_default VALUES (DEFAULT)
( SUBPARTITION p_default_small VALUES LESS THAN (10)
, SUBPARTITION p_default_medium VALUES LESS THAN (100)
, SUBPARTITION p_default_high VALUES LESS THAN (MAXVALUE)
)
) ENABLE ROW MOVEMENT;
When to Use Interval Partitioning
Interval partitioning can be used for every table that is range partitioned and uses fixed intervals for new partitions. The database automatically creates interval partitions as data for that partition is inserted. Until this happens, the interval partition exists but no segment is created for the partition.
The benefit of interval partitioning is that you do not need to create your range partitions explicitly. You should consider using interval partitioning unless you create range partitions with different intervals, or if you always set specific partition attributes when you create range partitions. Note that you can specify a list of tablespaces in the interval definition. The database creates interval partitions in the provided list of tablespaces in a round-robin manner.
If you upgrade your application and you use range partitioning or composite range-* partitioning, then you can easily change your existing table definition to use interval partitioning. Note that you cannot manually add partitions to an interval-partitioned table. If you have automated the creation of new partitions, then in the future you must change your application code to prevent the explicit creation of range partitions.
The following example shows how to change the sales table in the sample sh schema from range partitioning to start using monthly interval partitioning.
ALTER TABLE sales SET INTERVAL (NUMTOYMINTERVAL(1,'MONTH'));
You cannot use interval partitioning with reference partitioned tables.
Serializable transactions do not work with interval partitioning. Inserting data into a partition of an interval partitioned table that does not have a segment yet causes an error.
When to Use Reference Partitioning
Reference partitioning is useful in the following scenarios:
-
If you have denormalized, or would denormalize, a column from a master table into a child table to get partition pruning benefits on both tables.
For example, your
orderstable stores theorder_date, but theorder_itemstable, which stores one or more items for each order, does not. To get good performance for historical analysis of orders data, you would traditionally duplicate theorder_datecolumn in theorder_itemstable to use partition pruning on theorder_itemstable.You should consider reference partitioning in such a scenario and avoid having to duplicate the
order_datecolumn. Queries that join both tables and use a predicate onorder_dateautomatically benefit from partition pruning on both tables. -
If two large tables are joined frequently, then the tables are not partitioned on the join key, but you want to take advantage of partition-wise joins.
Reference partitioning implicitly enables full partition-wise joins.
-
If data in multiple tables has a related life cycle, then reference partitioning can provide significant manageability benefits.
Partition management operations against the master table are automatically cascaded to its descendents. For example, when you add a partition to the master table, that addition is automatically propagated to all its descendents.
To use reference partitioning, you must enable and enforce the foreign key relationship between the master table and the reference table in place. You can cascade reference-partitioned tables.
When to Partition on Virtual Columns
Virtual column partitioning enables you to partition on an expression, which may use data from other columns, and perform calculations with these columns. PL/SQL function calls are not supported in virtual column definitions that are to be used as a partitioning key.
Virtual column partitioning supports all partitioning methods, plus performance and manageability features. To get partition pruning benefits, consider using virtual columns if tables are frequently accessed using a predicate that is not directly captured in a column, but can be derived. Traditionally, to get partition pruning benefits, you would have to add a separate column to capture and calculate the correct value and ensure the column is always populated correctly to ensure correct query retrieval.
Example 3-12 shows a car_rentals table. The customer's confirmation number contains a two-character country name as the location where the rental car is picked up. Rental car analyses usually evaluate regional patterns, so it makes sense to partition by country.
Example 3-12 Creating a table with virtual columns for partitioning
CREATE TABLE car_rentals
( id NUMBER NOT NULL
, customer_id NUMBER NOT NULL
, confirmation_number VARCHAR2(12) NOT NULL
, car_id NUMBER
, car_type VARCHAR2(10)
, requested_car_type VARCHAR2(10) NOT NULL
, reservation_date DATE NOT NULL
, start_date DATE NOT NULL
, end_date DATE
, country as (substr(confirmation_number,9,2))
) PARTITION BY LIST (country)
SUBPARTITION BY HASH (customer_id)
SUBPARTITIONS 16
( PARTITION north_america VALUES ('US','CA','MX')
, PARTITION south_america VALUES ('BR','AR','PE')
, PARTITION europe VALUES ('GB','DE','NL','BE','FR','ES','IT','CH')
, PARTITION apac VALUES ('NZ','AU','IN','CN')
) ENABLE ROW MOVEMENT;
In this example, the column country is defined as a virtual column derived from the confirmation number. The virtual column does not require any storage. As the example illustrates, row movement is supported with virtual columns. The database migrates a row to a different partition if the virtual column evaluates to a different value in another partition.
Considerations When Using Read-Only Tablespaces
When a referential integrity constraint is defined between parent and child tables, an index is defined on the foreign key, and the tablespace in which that index resides is made read-only. Then the integrity check for the constraint is implemented in SQL and not through consistent read buffer access.
The implication of this is that, if the child is partitioned, only some child partitions have their indexes in read-only tables and, if an insert is made into one nonread-only child segment, then a TM enqueue is acquired on the child table in SX mode.
SX mode is incompatible with S requests, so that if you try to insert into the parent, it is blocked because that insert attempts to acquire an S TM enqueue against the child.