21 SQL for Aggregation in Data Warehouses
This chapter discusses aggregation of SQL, a basic aspect of data warehousing. It contains these topics:
Overview of SQL for Aggregation in Data Warehouses
Aggregation is a fundamental part of data warehousing. To improve aggregation performance in your warehouse, Oracle Database provides the following functionality:
-
CUBEandROLLUPextensions to theGROUPBYclause -
Three
GROUPINGfunctions -
GROUPINGSETSexpression -
Pivoting operations
The CUBE, ROLLUP, and GROUPING SETS extensions to SQL make querying and reporting easier and faster. CUBE, ROLLUP, and grouping sets produce a single result set that is equivalent to a UNION ALL of differently grouped rows. ROLLUP calculates aggregations such as SUM, COUNT, MAX, MIN, and AVG at increasing levels of aggregation, from the most detailed up to a grand total. CUBE is an extension similar to ROLLUP, enabling a single statement to calculate all possible combinations of aggregations. The CUBE, ROLLUP, and the GROUPING SETS extension lets you specify just the groupings needed in the GROUP BY clause. This allows efficient analysis across multiple dimensions without performing a CUBE operation. Computing a CUBE creates a heavy processing load, so replacing cubes with grouping sets can significantly increase performance.
To enhance performance, CUBE, ROLLUP, and GROUPING SETS can be parallelized: multiple processes can simultaneously execute all of these statements. These capabilities make aggregate calculations more efficient, thereby enhancing database performance, and scalability.
The three GROUPING functions help you identify the group each row belongs to and enable sorting subtotal rows and filtering results.
Analyzing Across Multiple Dimensions
One of the key concepts in decision support systems is multidimensional analysis: examining the enterprise from all necessary combinations of dimensions. We use the term dimension to mean any category used in specifying questions. Among the most commonly specified dimensions are time, geography, product, department, and distribution channel, but the potential dimensions are as endless as the varieties of enterprise activity. The events or entities associated with a particular set of dimension values are usually referred to as facts. The facts might be sales in units or local currency, profits, customer counts, production volumes, or anything else worth tracking.
Here are some examples of multidimensional requests:
-
Show total sales across all products at increasing aggregation levels for a geography dimension, from state to country to region, for 1999 and 2000.
-
Create a cross-tabular analysis of our operations showing expenses by territory in South America for 1999 and 2000. Include all possible subtotals.
-
List the top 10 sales representatives in Asia according to 2000 sales revenue for automotive products, and rank their commissions.
All these requests involve multiple dimensions. Many multidimensional questions require aggregated data and comparisons of data sets, often across time, geography or budgets.
To visualize data that has many dimensions, analysts commonly use the analogy of a data cube, that is, a space where facts are stored at the intersection of n dimensions. Figure 21-1 shows a data cube and how it can be used differently by various groups. The cube stores sales data organized by the dimensions of product, market, sales, and time. Note that this is only a metaphor: the actual data is physically stored in normal tables. The cube data consists of both detail and aggregated data.
Figure 21-1 Logical Cubes and Views by Different Users
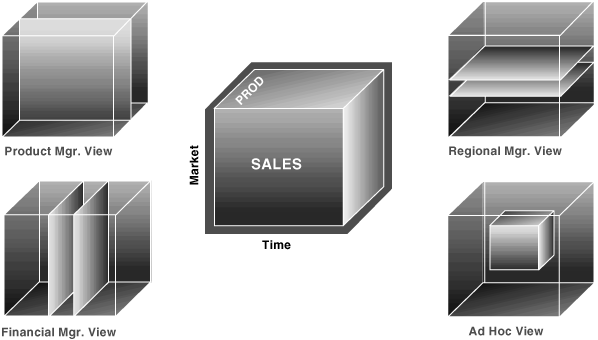
Description of "Figure 21-1 Logical Cubes and Views by Different Users"
You can retrieve slices of data from the cube. These correspond to cross-tabular reports such as the one shown in Table 21-1. Regional managers might study the data by comparing slices of the cube applicable to different markets. In contrast, product managers might compare slices that apply to different products. An ad hoc user might work with a wide variety of constraints, working in a subset cube.
Answering multidimensional questions often involves accessing and querying huge quantities of data, sometimes in millions of rows. Because the flood of detailed data generated by large organizations cannot be interpreted at the lowest level, aggregated views of the information are essential. Aggregations, such as sums and counts, across many dimensions are vital to multidimensional analyses. Therefore, analytical tasks require convenient and efficient data aggregation.
Optimized Performance
Not only multidimensional issues, but all types of processing can benefit from enhanced aggregation facilities. Transaction processing, financial and manufacturing systems—all of these generate large numbers of production reports needing substantial system resources. Improved efficiency when creating these reports will reduce system load. In fact, any computer process that aggregates data from details to higher levels will benefit from optimized aggregation performance.
These extensions provide aggregation features and bring many benefits, including:
-
Simplified programming requiring less SQL code for many tasks.
-
Quicker and more efficient query processing.
-
Reduced client processing loads and network traffic because aggregation work is shifted to servers.
-
Opportunities for caching aggregations because similar queries can leverage existing work.
An Aggregate Scenario
To illustrate the use of the GROUP BY extension, this chapter uses the sh data of the sample schema. All the examples refer to data from this scenario. The hypothetical company has sales across the world and tracks sales by both dollars and quantities information. Because there are many rows of data, the queries shown here typically have tight constraints on their WHERE clauses to limit the results to a small number of rows.
Example 21-1 Simple Cross-Tabular Report With Subtotals
Table 21-1 is a sample cross-tabular report showing the total sales by country_id and channel_desc for the US and France through the Internet and direct sales in September 2000.
Table 21-1 Simple Cross-Tabular Report With Subtotals
| Channel | Country | ||
|---|---|---|---|
|
France |
US |
Total |
|
|
Internet |
9,597 |
124,224 |
133,821 |
|
Direct Sales |
61,202 |
638,201 |
699,403 |
|
Total |
70,799 |
762,425 |
833,224 |
Consider that even a simple report such as this, with just nine values in its grid, generates four subtotals and a grand total. Half of the values needed for this report would not be calculated with a query that requested SUM(amount_sold) and did a GROUP BY(channel_desc, country_id). To get the higher-level aggregates would require additional queries. Database commands that offer improved calculation of subtotals bring major benefits to querying, reporting, and analytical operations.
SELECT channels.channel_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc='2000-09'
AND customers.country_id=countries.country_id
AND countries.country_iso_code IN ('US','FR')
GROUP BY CUBE(channels.channel_desc, countries.country_iso_code);
CHANNEL_DESC CO SALES$
-------------------- -- --------------
833,224
FR 70,799
US 762,425
Internet 133,821
Internet FR 9,597
Internet US 124,224
Direct Sales 699,403
Direct Sales FR 61,202
Direct Sales US 638,201
Interpreting NULLs in Examples
NULLs returned by the GROUP BY extensions are not always the traditional null meaning value unknown. Instead, a NULL may indicate that its row is a subtotal. To avoid introducing another non-value in the database system, these subtotal values are not given a special tag.
See Also:
"GROUPING Functions" for details on how the nulls representing subtotals are distinguished from nulls stored in the dataROLLUP Extension to GROUP BY
ROLLUP enables a SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions. It also calculates a grand total. ROLLUP is a simple extension to the GROUP BY clause, so its syntax is extremely easy to use. The ROLLUP extension is highly efficient, adding minimal overhead to a query.
The action of ROLLUP is straightforward: it creates subtotals that roll up from the most detailed level to a grand total, following a grouping list specified in the ROLLUP clause. ROLLUP takes as its argument an ordered list of grouping columns. First, it calculates the standard aggregate values specified in the GROUP BY clause. Then, it creates progressively higher-level subtotals, moving from right to left through the list of grouping columns. Finally, it creates a grand total.
ROLLUP creates subtotals at n+1 levels, where n is the number of grouping columns. For instance, if a query specifies ROLLUP on grouping columns of time, region, and department(n=3), the result set will include rows at four aggregation levels.
You might want to compress your data when using ROLLUP. This is particularly useful when there are few updates to older partitions.
When to Use ROLLUP
Use the ROLLUP extension in tasks involving subtotals.
-
It is very helpful for subtotaling along a hierarchical dimension such as time or geography. For instance, a query could specify a
ROLLUP(y,m,day)orROLLUP(country,state,city). -
For data warehouse administrators using summary tables,
ROLLUPcan simplify and speed up the maintenance of summary tables.
ROLLUP Syntax
ROLLUP appears in the GROUP BY clause in a SELECT statement. Its form is:
SELECT … GROUP BY ROLLUP(grouping_column_reference_list)
This example uses the data in the sh sample schema data, the same data as was used in Figure 21-1. The ROLLUP is across three dimensions.
SELECT channels.channel_desc, calendar_month_desc,
countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id = channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY
ROLLUP(channels.channel_desc, calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-09 140,793
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Internet 2000-10 151,593
Internet 292,387
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-09 723,424
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
Direct Sales 2000-10 774,222
Direct Sales 1,497,646
1,790,032
Note that results do not always add up due to rounding.
This query returns the following sets of rows:
-
Regular aggregation rows that would be produced by
GROUPBYwithout usingROLLUP. -
First-level subtotals aggregating across
country_idfor each combination ofchannel_descandcalendar_month. -
Second-level subtotals aggregating across
calendar_month_descandcountry_idfor eachchannel_descvalue. -
A grand total row.
Partial Rollup
You can also roll up so that only some of the sub-totals will be included. This partial rollup uses the following syntax:
GROUP BY expr1, ROLLUP(expr2, expr3);
In this case, the GROUP BY clause creates subtotals at (2+1=3) aggregation levels. That is, at level (expr1, expr2, expr3), (expr1, expr2), and (expr1).
SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY channel_desc, ROLLUP(calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-09 140,793
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Internet 2000-10 151,593
Internet 292,387
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-09 723,424
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
Direct Sales 2000-10 774,222
Direct Sales 1,497,646
This query returns the following sets of rows:
-
Regular aggregation rows that would be produced by
GROUPBYwithout usingROLLUP. -
First-level subtotals aggregating across
country_idfor each combination ofchannel_descandcalendar_month_desc. -
Second-level subtotals aggregating across
calendar_month_descandcountry_idfor eachchannel_descvalue. -
It does not produce a grand total row.
CUBE Extension to GROUP BY
CUBE takes a specified set of grouping columns and creates subtotals for all of their possible combinations. In terms of multidimensional analysis, CUBE generates all the subtotals that could be calculated for a data cube with the specified dimensions. If you have specified CUBE(time, region, department), the result set will include all the values that would be included in an equivalent ROLLUP statement plus additional combinations. For instance, in Figure 21-1, the departmental totals across regions (279,000 and 319,000) would not be calculated by a ROLLUP(time, region, department) clause, but they would be calculated by a CUBE(time, region, department) clause. If n columns are specified for a CUBE, there will be 2 to the n combinations of subtotals returned. Example 21-4 gives an example of a three-dimension cube.
See Also:
Oracle Database SQL Language Reference for syntax and restrictionsWhen to Use CUBE
Consider Using CUBE in any situation requiring cross-tabular reports. The data needed for cross-tabular reports can be generated with a single SELECT using CUBE. Like ROLLUP, CUBE can be helpful in generating summary tables. Note that population of summary tables is even faster if the CUBE query executes in parallel.
CUBE is typically most suitable in queries that use columns from multiple dimensions rather than columns representing different levels of a single dimension. For instance, a commonly requested cross-tabulation might need subtotals for all the combinations of month, state, and product. These are three independent dimensions, and analysis of all possible subtotal combinations is commonplace. In contrast, a cross-tabulation showing all possible combinations of year, month, and day would have several values of limited interest, because there is a natural hierarchy in the time dimension. Subtotals such as profit by day of month summed across year would be unnecessary in most analyses. Relatively few users need to ask "What were the total sales for the 16th of each month across the year?" See "Hierarchy Handling in ROLLUP and CUBE" for an example of handling rollup calculations efficiently.
CUBE Syntax
CUBE appears in the GROUP BY clause in a SELECT statement. Its form is:
SELECT … GROUP BY CUBE (grouping_column_reference_list)
SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id
AND customers.country_id = countries.country_id
AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND countries.country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
1,790,032
GB 208,257
US 1,581,775
2000-09 864,217
2000-09 GB 101,792
2000-09 US 762,425
2000-10 925,815
2000-10 GB 106,465
2000-10 US 819,351
Internet 292,387
Internet GB 31,109
Internet US 261,278
Internet 2000-09 140,793
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-10 151,593
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Direct Sales 1,497,646
Direct Sales GB 177,148
Direct Sales US 1,320,497
Direct Sales 2000-09 723,424
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-10 774,222
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
This query illustrates CUBE aggregation across three dimensions.
Partial CUBE
Partial CUBE resembles partial ROLLUP in that you can limit it to certain dimensions and precede it with columns outside the CUBE operator. In this case, subtotals of all possible combinations are limited to the dimensions within the cube list (in parentheses), and they are combined with the preceding items in the GROUP BY list.
The syntax for partial CUBE is as follows:
GROUP BY expr1, CUBE(expr2, expr3)
This syntax example calculates 2*2, or 4, subtotals. That is:
-
(
expr1,expr2,expr3) -
(
expr1,expr2) -
(
expr1,expr3) -
(
expr1)
Using the sales database, you can issue the following statement:
SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id = times.time_id
AND sales.cust_id = customers.cust_id
AND customers.country_id=countries.country_id
AND sales.channel_id = channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY channel_desc, CUBE(calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 292,387
Internet GB 31,109
Internet US 261,278
Internet 2000-09 140,793
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-10 151,593
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Direct Sales 1,497,646
Direct Sales GB 177,148
Direct Sales US 1,320,497
Direct Sales 2000-09 723,424
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-10 774,222
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
Calculating Subtotals Without CUBE
Just as for ROLLUP, multiple SELECT statements combined with UNION ALL statements could provide the same information gathered through CUBE. However, this might require many SELECT statements. For an n-dimensional cube, 2 to the n SELECT statements are needed. In the three-dimension example, this would mean issuing SELECT statements linked with UNION ALL. So many SELECT statements yield inefficient processing and very lengthy SQL.
Consider the impact of adding just one more dimension when calculating all possible combinations: the number of SELECT statements would double to 16. The more columns used in a CUBE clause, the greater the savings compared to the UNION ALL approach.
GROUPING Functions
Two challenges arise with the use of ROLLUP and CUBE. First, how can you programmatically determine which result set rows are subtotals, and how do you find the exact level of aggregation for a given subtotal? You often need to use subtotals in calculations such as percent-of-totals, so you need an easy way to determine which rows are the subtotals. Second, what happens if query results contain both stored NULL values and "NULL" values created by a ROLLUP or CUBE? How can you differentiate between the two? This section discusses some of these situations.
See Also:
Oracle Database SQL Language Reference for syntax and restrictionsGROUPING Function
GROUPING handles these problems. Using a single column as its argument, GROUPING returns 1 when it encounters a NULL value created by a ROLLUP or CUBE operation. That is, if the NULL indicates the row is a subtotal, GROUPING returns a 1. Any other type of value, including a stored NULL, returns a 0.
GROUPING appears in the selection list portion of a SELECT statement. Its form is:
SELECT … [GROUPING(dimension_column)…] …
GROUP BY … {CUBE | ROLLUP| GROUPING SETS} (dimension_column)
Example 21-6 GROUPING to Mask Columns
This example uses GROUPING to create a set of mask columns for the result set shown in Example 21-3. The mask columns are easy to analyze programmatically.
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$, GROUPING(channel_desc) AS Ch,
GROUPING(calendar_month_desc) AS Mo, GROUPING(country_iso_code) AS Co
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(channel_desc, calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$ CH MO CO
-------------------- -------- -- -------------- ---------- ---------- ----------
Internet 2000-09 GB 16,569 0 0 0
Internet 2000-09 US 124,224 0 0 0
Internet 2000-09 140,793 0 0 1
Internet 2000-10 GB 14,539 0 0 0
Internet 2000-10 US 137,054 0 0 0
Internet 2000-10 151,593 0 0 1
Internet 292,387 0 1 1
Direct Sales 2000-09 GB 85,223 0 0 0
Direct Sales 2000-09 US 638,201 0 0 0
Direct Sales 2000-09 723,424 0 0 1
Direct Sales 2000-10 GB 91,925 0 0 0
Direct Sales 2000-10 US 682,297 0 0 0
Direct Sales 2000-10 774,222 0 0 1
Direct Sales 1,497,646 0 1 1
1,790,032 1 1 1
A program can easily identify the detail rows by a mask of "0 0 0" on the T, R, and D columns. The first level subtotal rows have a mask of "0 0 1", the second level subtotal rows have a mask of "0 1 1", and the overall total row has a mask of "1 1 1".
You can improve the readability of result sets by using the GROUPING and DECODE functions as shown in Example 21-7.
Example 21-7 GROUPING For Readability
SELECT DECODE(GROUPING(channel_desc), 1, 'Multi-channel sum', channel_desc) AS
Channel, DECODE (GROUPING (country_iso_code), 1, 'Multi-country sum',
country_iso_code) AS Country, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc= '2000-09'
AND country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, country_iso_code);
CHANNEL COUNTRY SALES$
-------------------- ----------------- --------------
Multi-channel sum Multi-country sum 864,217
Multi-channel sum GB 101,792
Multi-channel sum US 762,425
Internet Multi-country sum 140,793
Internet GB 16,569
Internet US 124,224
Direct Sales Multi-country sum 723,424
Direct Sales GB 85,223
Direct Sales US 638,201
To understand the previous statement, note its first column specification, which handles the channel_desc column. Consider the first line of the previous statement:
SELECT DECODE(GROUPING(channel_desc), 1, 'All Channels', channel_desc)AS Channel
In this, the channel_desc value is determined with a DECODE function that contains a GROUPING function. The GROUPING function returns a 1 if a row value is an aggregate created by ROLLUP or CUBE, otherwise it returns a 0. The DECODE function then operates on the GROUPING function's results. It returns the text "All Channels" if it receives a 1 and the channel_desc value from the database if it receives a 0. Values from the database will be either a real value such as "Internet" or a stored NULL. The second column specification, displaying country_id, works the same way.
When to Use GROUPING
The GROUPING function is not only useful for identifying NULLs, it also enables sorting subtotal rows and filtering results. In Example 21-8, you retrieve a subset of the subtotals created by a CUBE and none of the base-level aggregations. The HAVING clause constrains columns that use GROUPING functions.
Example 21-8 GROUPING Combined with HAVING
SELECT channel_desc, calendar_month_desc, country_iso_code, TO_CHAR(
SUM(amount_sold), '9,999,999,999') SALES$, GROUPING(channel_desc) CH, GROUPING
(calendar_month_desc) MO, GROUPING(country_iso_code) CO
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, calendar_month_desc, country_iso_code)
HAVING (GROUPING(channel_desc)=1 AND GROUPING(calendar_month_desc)= 1
AND GROUPING(country_iso_code)=1) OR (GROUPING(channel_desc)=1
AND GROUPING (calendar_month_desc)= 1) OR (GROUPING(country_iso_code)=1
AND GROUPING(calendar_month_desc)= 1);
CHANNEL_DESC C CO SALES$ CH MO CO
-------------------- - -- -------------- ---------- ---------- ----------
US 1,581,775 1 1 0
GB 208,257 1 1 0
Direct Sales 1,497,646 0 1 1
Internet 292,387 0 1 1
1,790,032 1 1 1
Compare the result set of Example 21-8 with that in Example 21-3 to see how Example 21-8 is a precisely specified group: it contains only the yearly totals, regional totals aggregated over time and department, and the grand total.
GROUPING_ID Function
To find the GROUP BY level of a particular row, a query must return GROUPING function information for each of the GROUP BY columns. If we do this using the GROUPING function, every GROUP BY column requires another column using the GROUPING function. For instance, a four-column GROUP BY clause must be analyzed with four GROUPING functions. This is inconvenient to write in SQL and increases the number of columns required in the query. When you want to store the query result sets in tables, as with materialized views, the extra columns waste storage space.
To address these problems, you can use the GROUPING_ID function. GROUPING_ID returns a single number that enables you to determine the exact GROUP BY level. For each row, GROUPING_ID takes the set of 1's and 0's that would be generated if you used the appropriate GROUPING functions and concatenates them, forming a bit vector. The bit vector is treated as a binary number, and the number's base-10 value is returned by the GROUPING_ID function. For instance, if you group with the expression CUBE(a, b) the possible values are as shown in Table 21-2.
Table 21-2 GROUPING_ID Example for CUBE(a, b)
| Aggregation Level | Bit Vector | GROUPING_ID |
|---|---|---|
|
a, b |
0 0 |
0 |
|
a |
0 1 |
1 |
|
b |
1 0 |
2 |
|
Grand Total |
1 1 |
3 |
GROUPING_ID clearly distinguishes groupings created by grouping set specification, and it is very useful during refresh and rewrite of materialized views.
GROUP_ID Function
While the extensions to GROUP BY offer power and flexibility, they also allow complex result sets that can include duplicate groupings. The GROUP_ID function lets you distinguish among duplicate groupings. If there are multiple sets of rows calculated for a given level, GROUP_ID assigns the value of 0 to all the rows in the first set. All other sets of duplicate rows for a particular grouping are assigned higher values, starting with 1. For example, consider the following query, which generates a duplicate grouping:
SELECT country_iso_code, SUBSTR(cust_state_province,1,12), SUM(amount_sold),
GROUPING_ID(country_iso_code, cust_state_province) GROUPING_ID, GROUP_ID()
FROM sales, customers, times, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id=countries.country_id AND times.time_id= '30-OCT-00'
AND country_iso_code IN ('FR', 'ES')
GROUP BY GROUPING SETS (country_iso_code,
ROLLUP(country_iso_code, cust_state_province));
CO SUBSTR(CUST_ SUM(AMOUNT_SOLD) GROUPING_ID GROUP_ID()
-- ------------ ---------------- ----------- ----------
ES Alicante 135.32 0 0
ES Valencia 4133.56 0 0
ES Barcelona 24.22 0 0
FR Centre 74.3 0 0
FR Aquitaine 231.97 0 0
FR Rhtne-Alpes 1624.69 0 0
FR Ile-de-Franc 1860.59 0 0
FR Languedoc-Ro 4287.4 0 0
12372.05 3 0
ES 4293.1 1 0
FR 8078.95 1 0
ES 4293.1 1 1
FR 8078.95 1 1
This query generates the following groupings: (country_id, cust_state_province), (country_id), (country_id), and (). Note that the grouping (country_id) is repeated twice. The syntax for GROUPING SETS is explained in "GROUPING SETS Expression".
This function helps you filter out duplicate groupings from the result. For example, you can filter out duplicate (region) groupings from the previous example by adding a HAVING clause condition GROUP_ID()=0 to the query.
GROUPING SETS Expression
You can selectively specify the set of groups that you want to create using a GROUPING SETS expression within a GROUP BY clause. This allows precise specification across multiple dimensions without computing the whole CUBE. For example, you can say:
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'US')
GROUP BY GROUPING SETS((channel_desc, calendar_month_desc, country_iso_code),
(channel_desc, country_iso_code), (calendar_month_desc, country_iso_code));
Note that this statement uses composite columns, described in "Composite Columns". This statement calculates aggregates over three groupings:
-
(channel_desc, calendar_month_desc, country_iso_code) -
(channel_desc, country_iso_code) -
(calendar_month_desc, country_iso_code)
Compare the previous statement with the following alternative, which uses the CUBE operation and the GROUPING_ID function to return the desired rows:
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$,
GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code) gid
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, calendar_month_desc, country_iso_code)
HAVING GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code)=0
OR GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code)=2
OR GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code)=4;
This statement computes all the 8 (2 *2 *2) groupings, though only the previous 3 groups are of interest to you.
Another alternative is the following statement, which is lengthy due to several unions. This statement requires three scans of the base table, making it inefficient. CUBE and ROLLUP can be thought of as grouping sets with very specific semantics. For example, consider the following statement:
CUBE(a, b, c)
This statement is equivalent to:
GROUPING SETS ((a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), ()) ROLLUP(a, b, c)
And this statement is equivalent to:
GROUPING SETS ((a, b, c), (a, b), ())
GROUPING SETS Syntax
GROUPING SETS syntax lets you define multiple groupings in the same query. GROUP BY computes all the groupings specified and combines them with UNION ALL. For example, consider the following statement:
GROUP BY GROUPING sets (channel_desc, calendar_month_desc, country_id )
This statement is equivalent to:
GROUP BY channel_desc UNION ALL GROUP BY calendar_month_desc UNION ALL GROUP BY country_id
Table 21-3 shows grouping sets specification and equivalent GROUP BY specification. Note that some examples use composite columns.
Table 21-3 GROUPING SETS Statements and Equivalent GROUP BY
| GROUPING SETS Statement | Equivalent GROUP BY Statement |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
In the absence of an optimizer that looks across query blocks to generate the execution plan, a query based on UNION would need multiple scans of the base table, sales. This could be very inefficient as fact tables will normally be huge. Using GROUPING SETS statements, all the groupings of interest are available in the same query block.
Composite Columns
A composite column is a collection of columns that are treated as a unit during the computation of groupings. You specify the columns in parentheses as in the following statement:
ROLLUP (year, (quarter, month), day)
In this statement, the data is not rolled up across year and quarter, but is instead equivalent to the following groupings of a UNION ALL:
-
(
year,quarter,month,day), -
(
year,quarter,month), -
(
year) -
()
Here, (quarter, month) form a composite column and are treated as a unit. In general, composite columns are useful in ROLLUP, CUBE, GROUPING SETS, and concatenated groupings. For example, in CUBE or ROLLUP, composite columns would mean skipping aggregation across certain levels. That is, the following statement:
GROUP BY ROLLUP(a, (b, c))
This is equivalent to:
GROUP BY a, b, c UNION ALL GROUP BY a UNION ALL GROUP BY ()
Here, (b, c) are treated as a unit and rollup will not be applied across (b, c). It is as if you have an alias, for example z, for (b, c) and the GROUP BY expression reduces to GROUP BY ROLLUP(a, z). Compare this with the normal rollup as in the following:
GROUP BY ROLLUP(a, b, c)
This would be the following:
GROUP BY a, b, c UNION ALL GROUP BY a, b UNION ALL GROUP BY a UNION ALL GROUP BY ().
Similarly, the following statement is equivalent to the four GROUP BYs:
GROUP BY CUBE((a, b), c) GROUP BY a, b, c UNION ALL GROUP BY a, b UNION ALL GROUP BY c UNION ALL GROUP By ()
In GROUPING SETS, a composite column is used to denote a particular level of GROUP BY. See Table 21-3 for more examples of composite columns.
Example 21-10 Composite Columns
You do not have full control over what aggregation levels you want with CUBE and ROLLUP. For example, consider the following statement:
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(channel_desc, calendar_month_desc, country_iso_code);
This statement results in Oracle computing the following groupings:
-
(channel_desc, calendar_month_desc, country_iso_code) -
(channel_desc, calendar_month_desc) -
(channel_desc) -
()
If you are just interested in the first, third, and fourth of these groupings, you cannot limit the calculation to those groupings without using composite columns. With composite columns, this is possible by treating month and country as a single unit while rolling up. Columns enclosed in parentheses are treated as a unit while computing CUBE and ROLLUP. Thus, you would say:
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(channel_desc, (calendar_month_desc, country_iso_code));
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 2000-09 GB 228,241
Internet 2000-09 US 228,241
Internet 2000-10 GB 239,236
Internet 2000-10 US 239,236
Internet 934,955
Direct Sales 2000-09 GB 1,217,808
Direct Sales 2000-09 US 1,217,808
Direct Sales 2000-10 GB 1,225,584
Direct Sales 2000-10 US 1,225,584
Direct Sales 4,886,784
5,821,739
Concatenated Groupings
Concatenated groupings offer a concise way to generate useful combinations of groupings. Groupings specified with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product operation enables even a small number of concatenated groupings to generate a large number of final groups. The concatenated groupings are specified simply by listing multiple grouping sets, cubes, and rollups, and separating them with commas. Here is an example of concatenated grouping sets:
GROUP BY GROUPING SETS(a, b), GROUPING SETS(c, d)
This SQL defines the following groupings:
(a, c), (a, d), (b, c), (b, d)
Concatenation of grouping sets is very helpful for these reasons:
-
Ease of query development
You need not enumerate all groupings manually.
-
Use by applications
SQL generated by analytical applications often involves concatenation of grouping sets, with each grouping set defining groupings needed for a dimension.
Example 21-11 Concatenated Groupings
You can also specify more than one grouping in the GROUP BY clause. For example, if you want aggregated sales values for each product rolled up across all levels in the time dimension (year, month and day), and across all levels in the geography dimension (region), you can issue the following statement:
SELECT channel_desc, calendar_year, calendar_quarter_desc, country_iso_code,
cust_state_province, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id = times.time_id AND sales.cust_id = customers.cust_id
AND sales.channel_id = channels.channel_id AND countries.country_id =
customers.country_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN ('2000-09',
'2000-10') AND countries.country_iso_code IN ('GB', 'FR')
GROUP BY channel_desc, GROUPING SETS (ROLLUP(calendar_year,
calendar_quarter_desc),
ROLLUP(country_iso_code, cust_state_province));
This results in the following groupings:
-
(
channel_desc,calendar_year,calendar_quarter_desc) -
(
channel_desc,calendar_year) -
(
channel_desc) -
(
channel_desc,country_iso_code,cust_state_province) -
(
channel_desc,country_iso_code) -
(
channel_desc)
This is the cross-product of the following:
-
The expression,
channel_desc -
ROLLUP(calendar_year,calendar_quarter_desc), which is equivalent to ((calendar_year,calendar_quarter_desc), (calendar_year), ()) -
ROLLUP(country_iso_code, cust_state_province), which is equivalent to ((country_iso_code,cust_state_province), (country_iso_code), ())
Note that the output contains two occurrences of (channel_desc) group. To filter out the extra (channel_desc) group, the query could use a GROUP_ID function.
Another concatenated join example is Example 21-12, showing the cross product of two grouping sets.
Example 21-12 Concatenated Groupings (Cross-Product of Two Grouping Sets)
SELECT country_iso_code, cust_state_province, calendar_year,
calendar_quarter_desc, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
countries.country_id=customers.country_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'FR')
GROUP BY GROUPING SETS (country_iso_code, cust_state_province),
GROUPING SETS (calendar_year, calendar_quarter_desc);
This statement results in the computation of groupings:
-
(
country_iso_code,year), (country_iso_code,calendar_quarter_desc), (cust_state_province,year) and (cust_state_province,calendar_quarter_desc)
Concatenated Groupings and Hierarchical Data Cubes
One of the most important uses for concatenated groupings is to generate the aggregates needed for a hierarchical cube of data. A hierarchical cube is a data set where the data is aggregated along the rollup hierarchy of each of its dimensions and these aggregations are combined across dimensions. It includes the typical set of aggregations needed for business intelligence queries. By using concatenated groupings, you can generate all the aggregations needed by a hierarchical cube with just n ROLLUPs (where n is the number of dimensions), and avoid generating unwanted aggregations.
Consider just three of the dimensions in the sh sample schema data set, each of which has a multilevel hierarchy:
-
time:
year,quarter,month,day(weekis in a separate hierarchy) -
product:
category,subcategory,prod_name -
geography:
region,subregion,country,state,city
This data is represented using a column for each level of the hierarchies, creating a total of twelve columns for dimensions, plus the columns holding sales figures.
For our business intelligence needs, we would like to calculate and store certain aggregates of the various combinations of dimensions. In Example 21-13, we create the aggregates for all levels, except for "day", which would create too many rows. In particular, we want to use ROLLUP within each dimension to generate useful aggregates. Once we have the ROLLUP-based aggregates within each dimension, we want to combine them with the other dimensions. This will generate our hierarchical cube. Note that this is not at all the same as a CUBE using all twelve of the dimension columns: that would create 2 to the 12th power (4,096) aggregation groups, of which we need only a small fraction. Concatenated grouping sets make it easy to generate exactly the aggregations we need. Example 21-13 shows where a GROUP BY clause is needed.
Example 21-13 Concatenated Groupings and Hierarchical Cubes
SELECT calendar_year, calendar_quarter_desc, calendar_month_desc,
country_region, country_subregion, countries.country_iso_code,
cust_state_province, cust_city, prod_category_desc, prod_subcategory_desc,
prod_name, TO_CHAR(SUM (amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries, products
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND sales.prod_id=products.prod_id AND
customers.country_id=countries.country_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND prod_name IN ('Envoy Ambassador',
'Mouse Pad') AND countries.country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(calendar_year, calendar_quarter_desc, calendar_month_desc),
ROLLUP(country_region, country_subregion, countries.country_iso_code,
cust_state_province, cust_city),
ROLLUP(prod_category_desc, prod_subcategory_desc, prod_name);
The rollups in the GROUP BY specification generate the following groups, four for each dimension.
Table 21-4 Hierarchical CUBE Example
| ROLLUP By Time | ROLLUP By Product | ROLLUP By Geography |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The concatenated grouping sets specified in the previous SQL will take the ROLLUP aggregations listed in the table and perform a cross-product on them. The cross-product will create the 96 (4x4x6) aggregate groups needed for a hierarchical cube of the data. There are major advantages in using three ROLLUP expressions to replace what would otherwise require 96 grouping set expressions: the concise SQL is far less error-prone to develop and far easier to maintain, and it enables much better query optimization. You can picture how a cube with more dimensions and more levels would make the use of concatenated groupings even more advantageous.
See "Working with Hierarchical Cubes in SQL" for more information regarding hierarchical cubes.
Considerations when Using Aggregation
This section discusses the following topics.
Hierarchy Handling in ROLLUP and CUBE
The ROLLUP and CUBE extensions work independently of any hierarchy metadata in your system. Their calculations are based entirely on the columns specified in the SELECT statement in which they appear. This approach enables CUBE and ROLLUP to be used whether or not hierarchy metadata is available. The simplest way to handle levels in hierarchical dimensions is by using the ROLLUP extension and indicating levels explicitly through separate columns. The following code shows a simple example of this with months rolled up to quarters and quarters rolled up to years.
Example 21-14 ROLLUP and CUBE Hierarchy Handling
SELECT calendar_year, calendar_quarter_number,
calendar_month_number, SUM(amount_sold)
FROM sales, times, products, customers, countries
WHERE sales.time_id=times.time_id
AND sales.prod_id=products.prod_id
AND customers.country_id = countries.country_id
AND sales.cust_id=customers.cust_id
AND prod_name IN ('Envoy Ambassador', 'Mouse Pad')
AND country_iso_code = 'GB' AND calendar_year=1999
GROUP BY ROLLUP(calendar_year, calendar_quarter_number, calendar_month_number);
CALENDAR_YEAR CALENDAR_QUARTER_NUMBER CALENDAR_MONTH_NUMBER SUM(AMOUNT_SOLD)
------------- ----------------------- --------------------- ----------------
1999 1 1 5521.34
1999 1 2 22232.95
1999 1 3 10672.63
1999 1 38426.92
1999 2 4 23658.05
1999 2 5 5766.31
1999 2 6 23939.32
1999 2 53363.68
1999 3 7 12132.18
1999 3 8 13128.96
1999 3 9 19571.96
1999 3 44833.1
1999 4 10 15752.18
1999 4 11 7011.21
1999 4 12 14257.5
1999 4 37020.89
1999 173644.59
173644.59
Column Capacity in ROLLUP and CUBE
CUBE, ROLLUP, and GROUPING SETS do not restrict the GROUP BY clause column capacity. The GROUP BY clause, with or without the extensions, can work with up to 255 columns. However, the combinatorial explosion of CUBE makes it unwise to specify a large number of columns with the CUBE extension. Consider that a 20-column list for CUBE would create 2 to the 20 combinations in the result set. A very large CUBE list could strain system resources, so any such query must be tested carefully for performance and the load it places on the system.
HAVING Clause Used with GROUP BY Extensions
The HAVING clause of SELECT statements is unaffected by the use of GROUP BY. Note that the conditions specified in the HAVING clause apply to both the subtotal and non-subtotal rows of the result set. In some cases a query may need to exclude the subtotal rows or the non-subtotal rows from the HAVING clause. This can be achieved by using a GROUPING or GROUPING_ID function together with the HAVING clause. See Example 21-8 and its associated SQL statement for an example.
ORDER BY Clause Used with GROUP BY Extensions
In many cases, a query must order the rows in a certain way, and this is done with the ORDER BY clause. The ORDER BY clause of a SELECT statement is unaffected by the use of GROUP BY, since the ORDER BY clause is applied after the GROUP BY calculations are complete.
Note that the ORDER BY specification makes no distinction between aggregate and non-aggregate rows of the result set. For instance, you might wish to list sales figures in declining order, but still have the subtotals at the end of each group. Simply ordering sales figures in descending sequence will not be sufficient, since that will place the subtotals (the largest values) at the start of each group. Therefore, it is essential that the columns in the ORDER BY clause include columns that differentiate aggregate from non-aggregate columns. This requirement means that queries using ORDER BY along with aggregation extensions to GROUP BY will generally need to use one or more of the GROUPING functions.
Using Other Aggregate Functions with ROLLUP and CUBE
The examples in this chapter show ROLLUP and CUBE used with the SUM function. While this is the most common type of aggregation, these extensions can also be used with all other functions available to the GROUP BY clause, for example, COUNT, AVG, MIN, MAX, STDDEV, and VARIANCE. COUNT, which is often needed in cross-tabular analyses, is likely to be the second most commonly used function.
Computation Using the WITH Clause
The WITH clause (formally known as subquery_factoring_clause) enables you to reuse the same query block in a SELECT statement when it occurs more than once within a complex query. WITH is a part of the SQL-99 standard. This is particularly useful when a query has multiple references to the same query block and there are joins and aggregations. Using the WITH clause, Oracle retrieves the results of a query block and stores them in the user's temporary tablespace. Note that Oracle Database does not support recursive use of the WITH clause. Note that Oracle Database supports recursive use of the WITH clause that may be used for such queries as are used with a bill of materials or expansion of parent-child hierarchies to parent-descendant hierarchies. See Oracle Database SQL Language Reference for more information.
The following query is an example of where you can improve performance and write SQL more simply by using the WITH clause. The query calculates the sum of sales for each channel and holds it under the name channel_summary. Then it checks each channel's sales total to see if any channel's sales are greater than one third of the total sales. By using the WITH clause, the channel_summary data is calculated just once, avoiding an extra scan through the large sales table.
WITH channel_summary AS (SELECT channels.channel_desc, SUM(amount_sold) AS channel_total FROM sales, channels WHERE sales.channel_id = channels.channel_id GROUP BY channels.channel_desc) SELECT channel_desc, channel_total FROM channel_summary WHERE channel_total > (SELECT SUM(channel_total) * 1/3 FROM channel_summary); CHANNEL_DESC CHANNEL_TOTAL -------------------- ------------- Direct Sales 57875260.6
Note that this example could also be performed efficiently using the reporting aggregate functions described in Chapter 22, "SQL for Analysis and Reporting".
Working with Hierarchical Cubes in SQL
This section illustrates examples of working with hierarchical cubes.
Specifying Hierarchical Cubes in SQL
Oracle Database can specify hierarchical cubes in a simple and efficient SQL query. These hierarchical cubes represent the logical cubes referred to in many analytical SQL products. To specify data in the form of hierarchical cubes, you can use one of the extensions to the GROUP BY clause, concatenated grouping sets, to generate the aggregates needed for a hierarchical cube of data. By using concatenated rollup (rolling up along the hierarchy of each dimension and then concatenate them across multiple dimensions), you can generate all the aggregations needed by a hierarchical cube.
Example 21-16 Concatenated ROLLUP
The following shows the GROUP BY clause needed to create a hierarchical cube for a 2-dimensional example similar to Example 21-13. The following simple syntax performs a concatenated rollup:
GROUP BY ROLLUP(year, quarter, month), ROLLUP(Division, brand, item)
This concatenated rollup takes the ROLLUP aggregations similar to those listed in Table 21-4, "Hierarchical CUBE Example" in the prior section and performs a cross-product on them. The cross-product will create the 16 (4x4) aggregate groups needed for a hierarchical cube of the data.
Querying Hierarchical Cubes in SQL
Analytic applications treat data as cubes, but they want only certain slices and regions of the cube. Concatenated rollup (hierarchical cube) enables relational data to be treated as cubes. To handle complex analytic queries, the fundamental technique is to enclose a hierarchical cube query in an outer query that specifies the exact slice needed from the cube. Oracle Database optimizes the processing of hierarchical cubes nested inside slicing queries. By applying many powerful algorithms, these queries can be processed at unprecedented speed and scale. This enables SQL analytical tools and applications to use a consistent style of queries to handle the most complex questions.
Example 21-17 Hierarchical Cube Query
Consider the following analytic query. It consists of a hierarchical cube query nested in a slicing query.
SELECT month, division, sum_sales FROM
(SELECT year, quarter, month, division, brand, item, SUM(sales) sum_sales,
GROUPING_ID(grouping-columns) gid
FROM sales, products, time
WHERE join-condition
GROUP BY ROLLUP(year, quarter, month),
ROLLUP(division, brand, item))
WHERE division = 25 AND month = 200201 AND gid = gid-for-Division-Month;
The inner hierarchical cube specified defines a simple cube, with two dimensions and four levels in each dimension. It would generate 16 groups (4 Time levels * 4 Product levels). The GROUPING_ID function in the query identifies the specific group each row belongs to, based on the aggregation level of the grouping-columns in its argument.
The outer query applies the constraints needed for our specific query, limiting Division to a value of 25 and Month to a value of 200201 (representing January 2002 in this case). In conceptual terms, it slices a small chunk of data from the cube. The outer query's constraint on the GID column, indicated in the query by gid-for-division-month would be the value of a key indicating that the data is grouped as a combination of division and month. The GID constraint selects only those rows that are aggregated at the level of a GROUP BY month, division clause.
Oracle Database removes unneeded aggregation groups from query processing based on the outer query conditions. The outer conditions of the previous query limit the result set to a single group aggregating division and month. Any other groups involving year, month, brand, and item are unnecessary here. The group pruning optimization recognizes this and transforms the query into:
SELECT month, division, sum_sales FROM (SELECT null, null, month, division, null, null, SUM(sales) sum_sales, GROUPING_ID(grouping-columns) gid FROM sales, products, time WHERE join-condition GROUP BY month, division) WHERE division = 25 AND month = 200201 AND gid = gid-for-Division-Month;
The bold items highlight the changed SQL. The inner query now has a simple GROUP BY clause of month, division. The columns year, quarter, brand, and item have been converted to null to match the simplified GROUP BY clause. Because the query now requests just one group, fifteen out of sixteen groups are removed from the processing, greatly reducing the work. For a cube with more dimensions and more levels, the savings possible through group pruning can be far greater. Note that the group pruning transformation works with all the GROUP BY extensions: ROLLUP, CUBE, and GROUPING SETS.
While the optimizer has simplified the previous query to a simple GROUP BY, faster response times can be achieved if the group is precomputed and stored in a materialized view. Because online analytical queries can ask for any slice of the cube many groups may need to be precomputed and stored in a materialized view. This is discussed in the next section.
SQL for Creating Materialized Views to Store Hierarchical Cubes
Analytical SQL requires fast response times for multiple users, and this in turn demands that significant parts of a cube be precomputed and held in materialized views.
Data warehouse designers can choose exactly how much data to materialize. A data warehouse can have the full hierarchical cube materialized. While this will take the most storage space, it ensures quick response for any query within the cube. Alternatively, a data warehouse could have just partial materialization, saving storage space, but allowing only a subset of possible queries to be answered at highest speed. If the queries cover the full range of aggregate groupings possible in its data set, it may be best to materialize the whole hierarchical cube.
This means that each dimension's aggregation hierarchy is precomputed in combination with each of the other dimensions. Naturally, precomputing a full hierarchical cube requires more disk space and higher creation and refresh times than a small set of aggregate groups. The trade-off in processing time and disk space versus query performance must be considered before deciding to create it. An additional possibility you could consider is to use data compression to lessen your disk space requirements.
See Also:
-
Oracle Database SQL Language Reference for table compression syntax and restrictions
-
Oracle Database Administrator's Guide for further details about table compression
-
"Storage And Table Compression" for details regarding table compression
Examples of Hierarchical Cube Materialized Views
This section shows complete and partial hierarchical cube materialized views. Many of the examples are meant to illustrate capabilities, and do not actually run.
In a data warehouse where rolling window scenario is very common, it is recommended that you store the hierarchical cube in multiple materialized views - one for each level of time you are interested in. Hence, a complete hierarchical cube will be stored in four materialized views: sales_hierarchical_mon_cube_mv, sales_hierarchical_qtr_cube_mv, sales_hierarchical_yr_cube_mv, and sales_hierarchical_all_cube_mv.
The following statements create a complete hierarchical cube stored in a set of three composite partitioned and one list partitioned materialized view.
Example 21-18 Complete Hierarchical Cube Materialized View
CREATE MATERIALIZED VIEW sales_hierarchical_mon_cube_mv
PARTITION BY RANGE (mon)
SUBPARTITION BY LIST (gid)
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, calendar_quarter_desc qtr, calendar_month_desc mon,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(calendar_year, calendar_quarter_desc, calendar_month_desc,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales,
COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year, calendar_quarter_desc, calendar_month_desc,
ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
...;
CREATE MATERIALIZED VIEW sales_hierarchical_qtr_cube_mv
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, calendar_quarter_desc qtr,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(calendar_year, calendar_quarter_desc,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales,
COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id
AND s.time_id = t.time_id
GROUP BY calendar_year, calendar_quarter_desc,
ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
PARTITION BY RANGE (qtr)
SUBPARTITION BY LIST (gid)
...;
CREATE MATERIALIZED VIEW sales_hierarchical_yr_cube_mv
PARTITION BY RANGE (year)
SUBPARTITION BY LIST (gid)
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(calendar_year, country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year,
ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
...;
CREATE MATERIALIZED VIEW sales_hierarchical_all_cube_mv
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
PARTITION BY LIST (gid)
...;
This allows use of PCT refresh on the materialized views sales_hierarchical_mon_cube_mv, sales_hierarchical_qtr_cube_mv, and sales_hierarchical_yr_cube_mv on partition maintenance operations to sales table. PCT refresh can also be used when there have been significant changes to the base table and log based fast refresh is estimated to be slower than PCT refresh. You can just specify the method as force (method => '?') in to refresh sub-programs in the DBMS_MVIEW package and Oracle Database will pick the best method of refresh. See "Partition Change Tracking (PCT) Refresh" for more information regarding PCT refresh.
Because sales_hierarchical_qtr_cube_mv does not contain any column from times table, PCT refresh is not enabled on it. But, you can still call refresh sub-programs in the DBMS_MVIEW package with method as force (method => '?') and Oracle Database will pick the best method of refresh.
If you are interested in a partial cube (that is, a subset of groupings from the complete cube), then Oracle recommends storing the cube as a "federated cube". A federated cube stores each grouping of interest in a separate materialized view.
CREATE MATERIALIZED VIEW sales_mon_city_prod_mv
PARTITION BY RANGE (mon)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_month_desc mon, cust_city, prod_name, SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id
AND s.time_id = t.time_id
GROUP BY calendar_month_desc, cust_city, prod_name;
CREATE MATERIALIZED VIEW sales_qtr_city_prod_mv
PARTITION BY RANGE (qtr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_quarter_desc qtr, cust_city, prod_name,SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_quarter_desc, cust_city, prod_name;
CREATE MATERIALIZED VIEW sales_yr_city_prod_mv
PARTITION BY RANGE (yr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, cust_city, prod_name, SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year, cust_city, prod_name;
CREATE MATERIALIZED VIEW sales_mon_city_scat_mv
PARTITION BY RANGE (mon)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_month_desc mon, cust_city, prod_subcategory,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id =t.time_id
GROUP BY calendar_month_desc, cust_city, prod_subcategory;
CREATE MATERIALIZED VIEW sales_qtr_city_cat_mv
PARTITION BY RANGE (qtr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_quarter_desc qtr, cust_city, prod_category cat,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id =t.time_id
GROUP BY calendar_quarter_desc, cust_city, prod_category;
CREATE MATERIALIZED VIEW sales_yr_city_all_mv
PARTITION BY RANGE (yr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, cust_city, SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year, cust_city;
These materialized views can be created as BUILD DEFERRED and then, you can execute DBMS_MVIEW.REFRESH_DEPENDENT(number_of_failures, 'SALES', 'C' ...) so that the complete refresh of each of the materialized views defined on the detail table sales is scheduled in the most efficient order. See "Scheduling Refresh" for more information.
Because each of these materialized views is partitioned on the time level (month, quarter, or year) present in the SELECT list, PCT is enabled on sales table for each one of them, thus providing an opportunity to apply PCT refresh method in addition to FAST and COMPLETE refresh methods.