1 Data Warehousing Concepts
This chapter provides an overview of the Oracle data warehousing implementation. It includes:
-
Extracting Information from a Data Warehouse
Note that this book is meant as a supplement to standard texts about data warehousing. This book focuses on Oracle-specific material and does not reproduce in detail material of a general nature. Two standard texts are:
-
The Data Warehouse Toolkit by Ralph Kimball (John Wiley and Sons, 1996)
-
Building the Data Warehouse by William Inmon (John Wiley and Sons, 1996)
What is a Data Warehouse?
A data warehouse is a relational database that is designed for query and analysis rather than for transaction processing. It usually contains historical data derived from transaction data, but can include data from other sources. Data warehouses separate analysis workload from transaction workload and enable an organization to consolidate data from several sources. This helps in:
-
Maintaining historical records
-
Analyzing the data to gain a better understanding of the business and to improve the business.
In addition to a relational database, a data warehouse environment can include an extraction, transportation, transformation, and loading (ETL) solution, statistical analysis, reporting, data mining capabilities, client analysis tools, and other applications that manage the process of gathering data, transforming it into useful, actionable information, and delivering it to business users.
A common way of introducing data warehousing is to refer to the characteristics of a data warehouse as set forth by William Inmon:
Subject Oriented
Data warehouses are designed to help you analyze data. For example, to learn more about your company's sales data, you can build a data warehouse that concentrates on sales. Using this data warehouse, you can answer questions such as "Who was our best customer for this item last year?" or "Who is likely to be our best customer next year?" This ability to define a data warehouse by subject matter, sales in this case, makes the data warehouse subject oriented.
Integrated
Integration is closely related to subject orientation. Data warehouses must put data from disparate sources into a consistent format. They must resolve such problems as naming conflicts and inconsistencies among units of measure. When they achieve this, they are said to be integrated.
Nonvolatile
Nonvolatile means that, once entered into the data warehouse, data should not change. This is logical because the purpose of a data warehouse is to enable you to analyze what has occurred.
Time Variant
A data warehouse's focus on change over time is what is meant by the term time variant. In order to discover trends and identify hidden patterns and relationships in business, analysts need large amounts of data. This is very much in contrast to online transaction processing (OLTP) systems, where performance requirements demand that historical data be moved to an archive.
Contrasting OLTP and Data Warehousing Environments
Figure 1-1 illustrates key differences between an OLTP system and a data warehouse.
Figure 1-1 Contrasting OLTP and Data Warehousing Environments
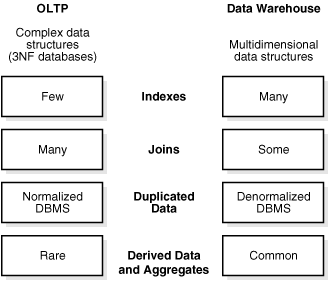
Description of "Figure 1-1 Contrasting OLTP and Data Warehousing Environments"
One major difference between the types of system is that data warehouses are not usually in third normal form (3NF), a type of data normalization common in OLTP environments.
Data warehouses and OLTP systems have very different requirements. Here are some examples of differences between typical data warehouses and OLTP systems:
-
Workload
Data warehouses are designed to accommodate ad hoc queries and data analysis. You might not know the workload of your data warehouse in advance, so a data warehouse should be optimized to perform well for a wide variety of possible query and analytical operations.
OLTP systems support only predefined operations. Your applications might be specifically tuned or designed to support only these operations.
-
Data modifications
A data warehouse is updated on a regular basis by the ETL process (run nightly or weekly) using bulk data modification techniques. The end users of a data warehouse do not directly update the data warehouse except when using analytical tools, such as data mining, to make predictions with associated probabilities, assign customers to market segments, and develop customer profiles.
In OLTP systems, end users routinely issue individual data modification statements to the database. The OLTP database is always up to date, and reflects the current state of each business transaction.
-
Schema design
Data warehouses often use denormalized or partially denormalized schemas (such as a star schema) to optimize query and analytical performance.
OLTP systems often use fully normalized schemas to optimize update/insert/delete performance, and to guarantee data consistency.
-
Typical operations
A typical data warehouse query scans thousands or millions of rows. For example, "Find the total sales for all customers last month."
A typical OLTP operation accesses only a handful of records. For example, "Retrieve the current order for this customer."
-
Historical data
Data warehouses usually store many months or years of data. This is to support historical analysis and reporting.
OLTP systems usually store data from only a few weeks or months. The OLTP system stores only historical data as needed to successfully meet the requirements of the current transaction.
Data Warehouse Architectures
Data warehouses and their architectures vary depending upon the specifics of an organization's situation. Three common architectures are:
Data Warehouse Architecture: Basic
Figure 1-2 shows a simple architecture for a data warehouse. End users directly access data derived from several source systems through the data warehouse.
Figure 1-2 Architecture of a Data Warehouse
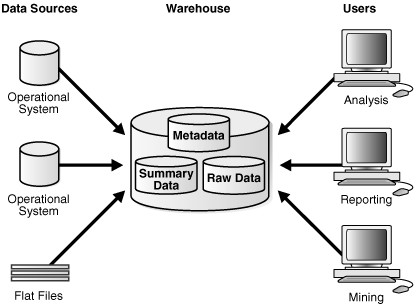
Description of "Figure 1-2 Architecture of a Data Warehouse"
In Figure 1-2, the metadata and raw data of a traditional OLTP system is present, as is an additional type of data, summary data. Summaries are very valuable in data warehouses because they pre-compute long operations in advance. For example, a typical data warehouse query is to retrieve something such as August sales. A summary in an Oracle database is called a materialized view.
Data Warehouse Architecture: with a Staging Area
You must clean and process your operational data before putting it into the warehouse, as shown in Figure 1-3. You can do this programmatically, although most data warehouses use a staging area instead. A staging area simplifies building summaries and general warehouse management. Figure 1-3 illustrates this typical architecture.
Figure 1-3 Architecture of a Data Warehouse with a Staging Area
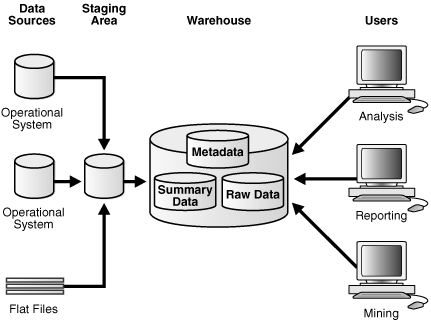
Description of "Figure 1-3 Architecture of a Data Warehouse with a Staging Area"
Data Warehouse Architecture: with a Staging Area and Data Marts
Although the architecture in Figure 1-3 is quite common, you may want to customize your warehouse's architecture for different groups within your organization. You can do this by adding data marts, which are systems designed for a particular line of business. Figure 1-4 illustrates an example where purchasing, sales, and inventories are separated. In this example, a financial analyst might want to analyze historical data for purchases and sales or mine historical data to make predictions about customer behavior.
Figure 1-4 Architecture of a Data Warehouse with a Staging Area and Data Marts
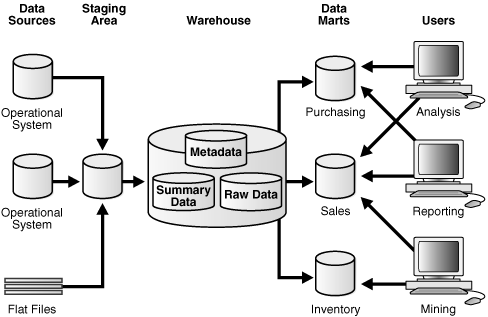
Description of "Figure 1-4 Architecture of a Data Warehouse with a Staging Area and Data Marts"
Note:
Data marts are an important part of many data warehouses, but they are not the focus of this book.Extracting Information from a Data Warehouse
You can extract information from the masses of data stored in a data warehouse by analyzing the data. The Oracle Database provides several ways to analyze data:
-
A wide array of statistical functions, including descriptive statistics, hypothesis testing, correlations analysis, test for distribution fit, cross tabs with Chi-square statistics, and analysis of variance (ANOVA); these functions are described in the Oracle Database SQL Language Reference.
OLAP
Oracle Database offers the industry's first and only embedded OLAP server. Oracle OLAP provides native multidimensional storage and speed-of-thought response times when analyzing data across multiple dimensions. The database provides rich support for analytics such as time series calculations, forecasting, advanced aggregation with additive and non additive operators, and allocation operators. These capabilities make the Oracle database a complete analytical platform, capable of supporting the entire spectrum of business intelligence and advanced analytical applications.
Oracle OLAP uses a multidimensional data model to perform complex statistical, mathematical, and financial analysis of historical data in real time. Oracle OLAP is fully integrated in the database, so that you can use standard SQL administrative, querying, and reporting tools.
For more information regarding OLAP, see Oracle OLAP User's Guide.
Full Integration of Multidimensional Technology
By integrating multidimensional objects and analytics into the database, Oracle provides the best of both worlds: the power of multidimensional analysis along with the reliability, availability, security, and scalability of the Oracle database.
Oracle OLAP is fully integrated into Oracle Database. At a technical level, this means:
-
The OLAP engine runs within the kernel of Oracle Database.
-
Dimensional objects are stored in Oracle Database in their native multidimensional format.
-
Cubes and other dimensional objects are first class data objects represented in the Oracle data dictionary.
-
Data security is administered in the standard way, by granting and revoking privileges to Oracle Database users and roles.
-
Applications can query dimensional objects using SQL.
The benefits to your organization are significant. Oracle OLAP offers the power of simplicity. One database, standard administration and security, standard interfaces and development tools.
Ease of Application Development
Oracle OLAP makes it easy to enrich your database and your applications with interesting analytic content. Native SQL access to Oracle multidimensional objects and calculations greatly eases the task of developing dashboards, reports, business intelligence (BI) and analytical applications of any type compared to systems that offer proprietary interfaces. Moreover, SQL access means that the power of Oracle OLAP analytics can be used by any database application, not just by the traditional limited collection of OLAP applications.
Ease of Administration
Because Oracle OLAP is completely embedded in the Oracle database, there is no administration learning curve as is typically associated with standalone OLAP servers. You can leverage your existing DBA staff, rather than invest in specialized administration skills.
One major administrative advantage of Oracle's embedded OLAP technology is automated cube maintenance. With standalone OLAP servers, the burden of refreshing the cube is left entirely to the administrator. This can be a complex and potentially error-prone job. The administrator must create procedures to extract the changed data from the relational source, move the data from the source system to the system running the standalone OLAP server, load and rebuild the cube. The DBA must take responsibility for the security of the deltas (changed values) during this process as well.
With Oracle OLAP, in contrast, cube refresh is handled entirely by the Oracle database. The database tracks the staleness of the dimensional objects, automatically keeps track of the deltas in the source tables, and automatically applies only the changed values during the refresh process. The DBA simply schedules the refresh at appropriate intervals, and Oracle Database takes care of everything else.
Security
With Oracle OLAP, standard Oracle Database security features are used to secure your multidimensional data.
In contrast, with a standalone OLAP server, administrators must manage security twice: once on the relational source system and again on the OLAP server system. Additionally, they must manage the security of data in transit from the relational system to the standalone OLAP system.
Unmatched Performance and Scalability
Business intelligence and analytical applications are dominated by actions such as drilling up and down hierarchies and comparing aggregate values such as period-over-period, share of parent, projections onto future time periods, and a myriad of similar calculations. Often these actions are essentially random across the entire space of potential hierarchical aggregations. Because Oracle OLAP pre-computes or efficiently computes on the fly all aggregates in the defined multidimensional space, it delivers unmatched performance for typical business intelligence applications.
Oracle OLAP queries take advantage of Oracle shared cursors, dramatically reducing memory requirements and increasing performance.
When Oracle Database is installed with Real Application Clusters (Oracle RAC), OLAP applications receive the same benefits in performance, scalability, fail over, and load balancing as any other application.
Reduced Costs
All these features add up to reduced costs. Administrative costs are reduced because existing personnel skills can be leveraged. Moreover, the Oracle database can manage the refresh of dimensional objects, a complex task left to administrators in other systems. Standard security reduces administration costs as well. Application development costs are reduced because the availability of a large pool of application developers who are SQL knowledgeable, and a large collection of SQL-based development tools means applications can be developed and deployed more quickly. Any SQL-based development tool can take advantage of Oracle OLAP. Hardware costs are reduced by Oracle OLAP's efficient management of aggregations, use of shared cursors, and Oracle RAC, which enables highly scalable systems to be built from low-cost commodity components.
Querying Dimensional Objects
Oracle OLAP adds power to your SQL applications by providing extensive analytic content and fast query response times. A SQL query interface enables any application to query cubes and dimensions without any knowledge of OLAP.
The OLAP option automatically generates a set of relational views on cubes, dimensions, and hierarchies. SQL applications query these views to display the information-rich contents of these objects to analysts and decision makers. You can also create custom views that comply with the structure expected by your applications, using the system-generated views like base tables.
Analysts can choose any SQL query and analysis tool for selecting, viewing, and analyzing the data You can use your favorite tool or application, or use one of the tools supplied with Oracle Database, such as Oracle Application Express and Business Intelligence Publisher.
Efficient Storage and Uniform Availability of Summary Data
Cube materialized views bring the fast update and fast query capabilities of the OLAP option to applications that query detail relational tables, as well as to applications that query cubes directly.
A single cube materialized view can replace many of the relational materialized views of summaries on a fact table, providing uniform response time to all summary data through query rewrite. Applications experience excellent query performance.
Cube materialized views are cubes that have been enhanced to use the automatic refresh and query rewrite features of Oracle Database. Summary data is generated and stored in a cube, and query rewrite automatically redirects queries to the cube materialized views.
Many of the same data dictionary views and PL/SQL packages that support relational materialized views also support cube materialized views. Moreover, a group of PL/SQL subprograms in DBMS_CUBE supports the rapid deployment of cube materialized views from existing relational materialized views.
Tools for Creating and Managing Dimensional Objects
Analytic Workspace Manager is the primary tool for creating, developing, and managing dimensional objects in Oracle Database.
Oracle OLAP is contained in the database and its resources are managed using the same tools, such as Oracle Enterprise Manager Database Control, Automatic Workload Repository, and Automatic Database Diagnostic Monitor.
Data Mining
Data mining uses large quantities of data to create models. These models can provide insights that are revealing, significant, and valuable. For example, you can use data mining to:
-
Predict those customers likely to change service providers.
-
Discover the factors involved with a disease.
-
Identify fraudulent behavior.
Data mining solves many kinds of business problems. For example, data mining can be used to predict customers likely to attrite.
Oracle Data Mining performs data mining in the Oracle Database. Oracle Data Mining does not require data movement between the database and an external mining server, thereby eliminating redundancy, improving efficient data storage and processing, ensuring that up-to-date data is used, and maintaining data security.
For detailed information about Oracle Data Mining, see Oracle Data Mining Concepts.
Oracle Data Mining Functionality
Oracle Data Mining supports the major data mining functions. There is at least one algorithm for each data mining function.
Oracle Data Mining supports the following data mining functions:
-
Classification: Grouping items into discrete classes and predicting which class an item belongs to; classification algorithms are Decision Tree, Naive Bayes, Generalized Linear Models (Binary Logistic Regression), and Support Vector Machines.
-
Regression: Approximating and predicting continuous numeric values; the algorithms for regression are Support Vector Machines and Generalized Linear Models (Multivariate Linear Regression).
-
Anomaly Detection: Detecting anomalous cases, such as fraud and intrusions; the algorithm for anomaly detection is one-class Support Vector Machines.
-
Attribute Importance: Identifying the attributes that have the strongest relationships with the target attribute (for example, customers likely to churn); the algorithm for attribute importance is Minimum Descriptor Length.
-
Clustering: Finding natural groupings in the data that are often used for identifying customer segments; the algorithms for clustering are k-Means and O-Cluster.
-
Associations: Analyzing "market baskets", items that are likely to be purchased together; the algorithm for associations is a priori.
-
Feature Extraction: Creating new attributes (features) as a combination of the original attributes; the algorithm for feature extraction is Non-Negative Matrix Factorization.
In addition to mining structured data, Oracle Data Mining permits mining of text data (such as police reports, customer comments, or physician's notes) or spatial data.
Oracle Data Mining Interfaces
Oracle Data Mining APIs provide extensive support for building applications that automate the extraction and dissemination of data mining insights.
Data mining activities such as model building, testing, and scoring are accomplished through a PL/SQL API, a Java API, and SQL Data Mining functions. The Java API is compliant with the data mining standard JSR 73. The Java API and the PL/SQL API are fully interoperable.
Oracle Data Mining allows the creation of a supermodel, that is, a model that contains the instructions for its own data preparation. The embedded data preparation can be implemented automatically and/or manually. Embedded Data Preparation supports user-specified data transformations; Automatic Data Preparation supports algorithm-required data preparation, such as binning, normalization, and outlier treatment.
SQL Data Mining functions support the scoring of classification, regression, clustering, and feature extraction models. Within the context of standard SQL statements, pre-created models can be applied to new data and the results returned for further processing, just like any other SQL query.
Predictive Analytics automates the process of data mining. Without user intervention, Predictive Analytics routines manage data preparation, algorithm selection, model building, and model scoring so that the user can benefit from data mining without having to be a data mining expert.
Oracle Data Miner is the graphical user interface for Oracle Data Mining. Oracle Data Miner guides you through the data preparation, data mining, model evaluation, and model scoring process. For more information about the Oracle Data Mining interfaces, see Oracle Data Mining Concepts.