6 Parallel Execution in Data Warehouses
This chapter introduces the idea of parallel execution, which enables you to achieve good performance with data warehouses, and includes:
What is Parallel Execution?
Databases today, irrespective of whether they are data warehouses, operational data stores, or OLTP systems, contain a large amount of information. However, finding and presenting the right information in a timely fashion can be a challenge because of the vast quantity of data involved.
Parallel execution is the capability that addresses this challenge. Using parallel execution (also called parallelism), terabytes of data can be processed in minutes, not hours or days, simply by using multiple processes to accomplish a single task. This dramatically reduces response time for data-intensive operations on large databases typically associated with decision support systems (DSS) and data warehouses. You can also implement parallel execution on OLTP system for batch processing or schema maintenance operations such as index creation. Parallelism is the idea of breaking down a task so that, instead of one process doing all of the work in a query, many processes do part of the work at the same time. An example of this is when four processes combine to calculate the total sales for a year, each process handles one quarter of the year instead of a single processing handling all four quarters by itself. The improvement in performance can be quite significant.
Parallel execution improves processing for:
-
Queries requiring large table scans, joins, or partitioned index scans
-
Creations of large indexes
-
Creation of large tables (including materialized views)
-
Bulk inserts, updates, merges, and deletes
You can also use parallel execution to access object types within an Oracle database. For example, you can use parallel execution to access large objects (LOBs).
Large data warehouses should always use parallel execution to achieve good performance. Specific operations in OLTP applications, such as batch operations, can also significantly benefit from parallel execution.
Why Use Parallel Execution?
Imagine that your task is to count the number of cars in a street. There are two ways to do this. One, you can go through the street by yourself and count the number of cars or you can enlist a friend and then the two of you can start on opposite ends of the street, count cars until you meet each other and add the results of both counts to complete the task.
Assuming your friend counts equally fast as you do, you expect to complete the task of counting all cars in a street in roughly half the time compared to when you perform the job all by yourself. If this is the case, then your operations scales linearly. That is, twice the number of resources halves the total processing time.
A database is not very different from the counting cars example. If you allocate twice the number of resources and achieve a processing time that is half of what it was with the original amount of resources, then the operation scales linearly. Scaling linearly is the ultimate goal of parallel processing, both in counting cars as well as in delivering answers from a database query.
See Also:
-
Oracle Database Concepts for a general introduction to parallelism concepts
-
Oracle Database VLDB and Partitioning Guide for more information about using parallel execution
When to Implement Parallel Execution
Parallel execution benefits systems with all of the following characteristics:
-
Symmetric multiprocessors (SMPs), clusters, or massively parallel systems
-
Sufficient I/O bandwidth
-
Underutilized or intermittently used CPUs (for example, systems where CPU usage is typically less than 30%)
-
Sufficient memory to support additional memory-intensive processes, such as sorts, hashing, and I/O buffers
If your system lacks any of these characteristics, parallel execution might not significantly improve performance. In fact, parallel execution may reduce system performance on overutilized systems or systems with small I/O bandwidth.
The benefits of parallel execution can be seen in DSS and data warehousing environments. OLTP systems can also benefit from parallel execution during batch processing and during schema maintenance operations such as creation of indexes. The average simple DML or SELECT statements that characterize OLTP applications would not see any benefit from being executed in parallel.
When Not to Implement Parallel Execution
Parallel execution is not normally useful for:
-
Environments in which the typical query or transaction is very short (a few seconds or less). This includes most online transaction systems. Parallel execution is not useful in these environments because there is a cost associated with coordinating the parallel execution servers; for short transactions, the cost of this coordination may outweigh the benefits of parallelism.
-
Environments in which the CPU, memory, or I/O resources are heavily utilized. Parallel execution is designed to exploit additional available hardware resources; if no such resources are available, then parallel execution does not yield any benefits and indeed may be detrimental to performance.
Automatic Degree of Parallelism and Statement Queuing
As the name implies, automatic degree of parallelism is where Oracle Database determines the degree of parallelism (DOP) with which to run a statement (DML, DDL, and queries) based on the fastest possible plan as determined by the optimizer. That means that the database parses a query, calculates the cost and then calculates a DOP to run with. The cheapest plan may be to run serially, which is also an option. Figure 6-1, "Optimizer Calculation: Serial or Parallel?" illustrates this decision making process.
Figure 6-1 Optimizer Calculation: Serial or Parallel?
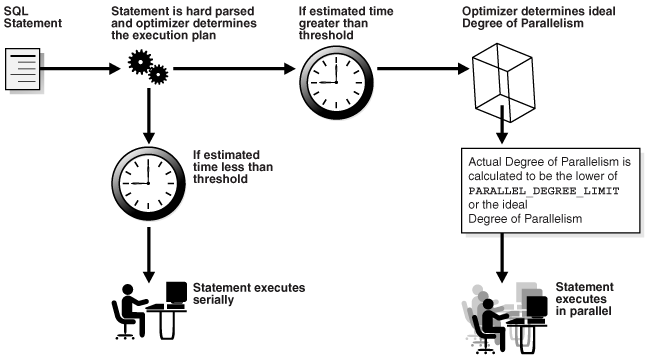
Description of "Figure 6-1 Optimizer Calculation: Serial or Parallel?"
Should you choose to use automatic DOP, you may see many more statements running in parallel, especially if the threshold is relatively low, where low is relative to the system and not an absolute quantifier.
Because of this expected behavior of more statements running in parallel with automatic DOP, it becomes more important to manage the utilization of the parallel processes available. That means that the system should be intelligent about when to run a statement and verify whether the requested numbers of parallel processes are available. The requested number of processes in this is the DOP for that statement.
The answer to this management question is parallel statement queuing with the Database Resource Manager. Parallel statement queuing runs a statement when its requested DOP is available. For example, when a statement requests a DOP of 64, it will not run if there are only 32 processes currently free to assist this customer, so the statement will be placed into a queue.
With Database Resource Manager, you can classify statements into workloads through consumer groups. Each consumer group can then be given the appropriate priority and the appropriate levels of parallel processes. Each consumer group also has its own queue to queue parallel statements based on the system load.
See Also:
-
Oracle Database VLDB and Partitioning Guide for more information about using automatic DOP with parallel execution
-
Oracle Database Administrator's Guide for more information about using the Database Resource Manager
In-Memory Parallel Execution
Traditionally, parallel processing by-passed the database buffer cache for most operations, reading data directly from disk (through direct path I/O) into the parallel execution server's private working space. Only objects smaller than about 2% of DB_CACHE_SIZE would be cached in the database buffer cache of an instance, and most objects accessed in parallel are larger than this limit. This behavior meant that parallel processing rarely took advantage of the available memory other than for its private processing. However, over the last decade, hardware systems have evolved quite dramatically; the memory capacity on a typical database server is now in the double or triple digit gigabyte range. This, together with Oracle's compression technologies and the capability of Oracle Database 11g Release 2 to exploit the aggregated database buffer cache of an Oracle Real Application Clusters environment now enables caching of objects in the terabyte range.
In-Memory parallel execution takes advantage of this large aggregated database buffer cache. By having parallel execution servers access objects using the database buffer cache, they can scan data at least ten times faster than they can on disk.
With In-Memory parallel execution, when a SQL statement is issued in parallel, a check is conducted to determine if the objects accessed by the statement should be cached in the aggregated buffer cache of the system. In this context, an object can either be a table, index, or, in the case of partitioned objects, one or multiple partitions.
See Also:
-
Oracle Database VLDB and Partitioning Guide for more information about using In-Memory parallel execution