23 SQL for Modeling
This chapter discusses using SQL modeling, and includes:
Overview of SQL Modeling
The MODEL clause brings a new level of power and flexibility to SQL calculations. With the MODEL clause, you can create a multidimensional array from query results and then apply formulas (called rules) to this array to calculate new values. The rules can range from basic arithmetic to simultaneous equations using recursion. For some applications, the MODEL clause can replace PC-based spreadsheets. Models in SQL leverage Oracle Database's strengths in scalability, manageability, collaboration, and security. The core query engine can work with unlimited quantities of data. By defining and executing models within the database, users avoid transferring large data sets to and from separate modeling environments. Models can be shared easily across workgroups, ensuring that calculations are consistent for all applications. Just as models can be shared, access can also be controlled precisely with Oracle's security features. With its rich functionality, the MODEL clause can enhance all types of applications.
The MODEL clause enables you to create a multidimensional array by mapping the columns of a query into three groups: partitioning, dimension, and measure columns. These elements perform the following tasks:
-
Partition columns define the logical blocks of the result set in a way similar to the partitions of the analytical functions described in Chapter 22, "SQL for Analysis and Reporting". Rules in the
MODELclause are applied to each partition independent of other partitions. Thus, partitions serve as a boundary point for parallelizing theMODELcomputation. -
Dimension columns define the multi-dimensional array and are used to identify cells within a partition. By default, a full combination of dimensions should identify just one cell in a partition. In default mode, they can be considered analogous to the key of a relational table.
-
Measures are equivalent to the measures of a fact table in a star schema. They typically contain numeric values such as sales units or cost. Each cell is accessed by specifying its full combination of dimensions. Note that each partition may have a cell that matches a given combination of dimensions.
The MODEL clause enables you to specify rules to manipulate the measure values of the cells in the multi-dimensional array defined by partition and dimension columns. Rules access and update measure column values by directly specifying dimension values. The references used in rules result in a highly readable model. Rules are concise and flexible, and can use wild cards and looping constructs for maximum expressiveness. Oracle Database evaluates the rules in an efficient way, parallelizes the model computation whenever possible, and provides a seamless integration of the MODEL clause with other SQL clauses. The MODEL clause, thus, is a scalable and manageable way of computing business models in the database.
Figure 23-1 offers a conceptual overview of the modeling feature of SQL. The figure has three parts. The top segment shows the concept of dividing a typical table into partition, dimension, and measure columns. The middle segment shows two rules that calculate the value of Prod1 and Prod2 for the year 2002. Finally, the third part shows the output of a query that applies the rules to such a table with hypothetical data. The unshaded output is the original data as it is retrieved from the database, while the shaded output shows the rows calculated by the rules. Note that results in partition A are calculated independently from results of partition B.
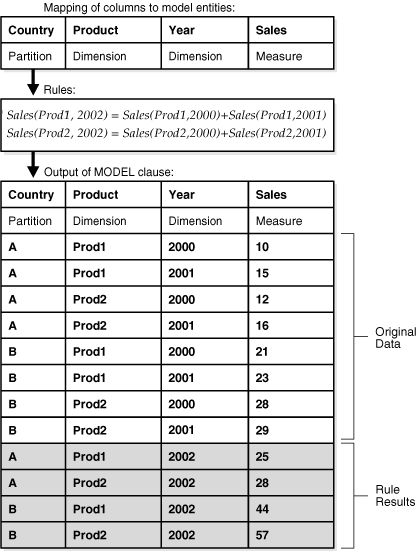
How Data is Processed in a SQL Model
Figure 23-2 shows the flow of processing within a simple MODEL clause. In this case, we will follow data through a MODEL clause that includes three rules. One of the rules updates an existing value, while the other two create new values for a forecast. The figure shows that the rows of data retrieved by a query are fed into the MODEL clause and rearranged into an array. Once the array is defined, rules are applied one by one to the data. The shaded cells in Figure 23-2 represent new data created by the rules and the cells enclosed by ovals represent the source data for the new values. Finally, the data, including both its updated values and newly created values, is rearranged into row form and presented as the results of the query. Note that no data is inserted into any table by this query.
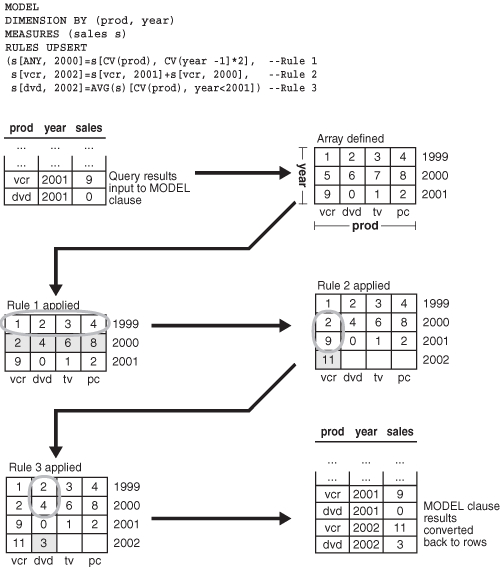
Why Use SQL Modeling?
Oracle modeling enables you to perform sophisticated calculations on your data. A typical case is when you want to apply business rules to data and then generate reports. Because Oracle Database integrates modeling calculations into the database, performance and manageability are enhanced significantly. Consider the following query:
SELECT SUBSTR(country, 1, 20) country,
SUBSTR(product, 1, 15) product, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL
PARTITION BY (country) DIMENSION BY (product, year)
MEASURES (sales sales)
RULES
(sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001],
sales['All_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002])
ORDER BY country, product, year;
This query partitions the data in sales_view (which is illustrated in "Base Schema") on country so that the model computation, as defined by the three rules, is performed on each country. This model calculates the sales of Bounce in 2002 as the sum of its sales in 2000 and 2001, and sets the sales for Y Box in 2002 to the same value as they were in 2001. Also, it introduces a new product category All_Products (sales_view does not have the product All_Products) for year 2002 to be the sum of sales of Bounce and Y Box for that year. The output of this query is as follows, where bold text indicates new values:
COUNTRY PRODUCT YEAR SALES -------------------- --------------- ---------- ---------- Italy Bounce 1999 2474.78 Italy Bounce 2000 4333.69 Italy Bounce 2001 4846.3 Italy Bounce 2002 9179.99 ... Italy Y Box 1999 15215.16 Italy Y Box 2000 29322.89 Italy Y Box 2001 81207.55 Italy Y Box 2002 81207.55 ... Italy All_Products 2002 90387.54 ... Japan Bounce 1999 2961.3 Japan Bounce 2000 5133.53 Japan Bounce 2001 6303.6 Japan Bounce 2002 11437.13 ... Japan Y Box 1999 22161.91 Japan Y Box 2000 45690.66 Japan Y Box 2001 89634.83 Japan Y Box 2002 89634.83 ... Japan All_Products 2002 101071.96 ...
Note that, while the sales values for Bounce and Y Box exist in the input, the values for All_Products are derived.
SQL Modeling Capabilities
Oracle Database provides the following capabilities with the MODEL clause:
-
Cell addressing using dimension values
Measure columns in individual rows are treated like cells in a multi-dimensional array and can be referenced and updated using dimension values. For example, in a fact table
ft(country, year, sales), you can designatecountryandyearto be dimension columns andsalesto be the measure and reference sales for a given country and year assales[country='Spain', year=1999]. This gives you the sales value for Spain in 1999. You can also use a shorthand formsales['Spain', 1999], which has the same meaning. There are a few semantic differences between these notations, though. See "Cell Referencing" for further details. -
Symbolic array computation
You can specify a series of formulas, called rules, to operate on the data. Rules can invoke functions on individual cells or on a set or range of cells. An example involving individual cells is the following:
sales[country='Spain',year=2001] = sales['Spain',2000]+ sales['Spain',1999]
This sets the sales in Spain for the year 2001 to the sum of sales in Spain for 1999 and 2000. An example involving a range of cells is the following:
sales[country='Spain',year=2001] = MAX(sales)['Spain',year BETWEEN 1997 AND 2000]
This sets the sales in Spain for the year 2001 equal to the maximum sales in Spain between 1997 and 2000.
-
UPSERT,UPSERTALL, andUPDATEoptionsUsing the
UPSERToption, which is the default, you can create cell values that do not exist in the input data. If the cell referenced exists in the data, it is updated. If the cell referenced does not exist in the data, and the rule uses appropriate notation, then the cell is inserted. TheUPSERTALLoption enables you to haveUPSERTbehavior for a wider variety of rules. TheUPDATEoption, on the other hand, would never insert any new cells.You can specify these options globally, in which case they apply to all rules, or per each rule. If you specify an option at the rule level, it overrides the global option. Consider the following rules:
UPDATE sales['Spain', 1999] = 3567.99, UPSERT sales['Spain', 2001] = sales['Spain', 2000]+ sales['Spain', 1999]
The first rule updates the cell for sales in Spain for 1999. The second rule updates the cell for sales in Spain for 2001 if it exists, otherwise, it creates a new cell.
-
Wildcard specification of dimensions
You can use
ANYandISANYto specify all values in a dimension. As an example, consider the following statement:sales[ANY, 2001] = sales['Japan', 2000]
This rule sets the 2001 sales of all countries equal to the sales value of Japan for the year 2000. All values for the dimension, including nulls, satisfy the
ANYspecification. You can also specify this using anISANYpredicate as in the following:sales[country IS ANY, 2001] = sales['Japan', 2000]
-
Accessing dimension values using the
CVfunctionYou can use the
CVfunction on the right side of a rule to access the value of a dimension column of the cell referenced on the left side of a rule. It enables you to combine multiple rules performing similar computation into a single rule, thus resulting in concise specification. For example, you can combine the following rules:sales[country='Spain', year=2002] = 1.2 * sales['Spain', 2001], sales[country='Italy', year=2002] = 1.2 * sales['Italy', 2001], sales[country='Japan', year=2002] = 1.2 * sales['Japan', 2001]
They can be combined into one single rule:
sales[country IN ('Spain', 'Italy', 'Japan'), year=2002] = 1.2 * sales[CV(country), 2001]Observe that the
CVfunction passes the value for thecountrydimension from the left to the right side of the rule. -
Ordered computation
For rules updating a set of cells, the result may depend on the ordering of dimension values. You can force a particular order for the dimension values by specifying an
ORDERBYin the rule. An example is the following rule:sales[country IS ANY, year BETWEEN 2000 AND 2003] ORDER BY year = 1.05 * sales[CV(country), CV(year)-1]
This ensures that the years are referenced in increasing chronological order.
-
Automatic rule ordering
Rules in the
MODELclause can be automatically ordered based on dependencies among the cells using theAUTOMATICORDERkeywords. For example, in the following assignments, the last two rules will be processed before the first rule because the first depends on the second and third:RULES AUTOMATIC ORDER {sales[c='Spain', y=2001] = sales[c='Spain', y=2000] + sales[c='Spain', y=1999] sales[c='Spain', y=2000] = 50000, sales[c='Spain', y=1999] = 40000} -
Iterative rule evaluation
You can specify iterative rule evaluation, in which case the rules are evaluated iteratively until the termination condition is satisfied. Consider the following specification:
MODEL DIMENSION BY (x) MEASURES (s) RULES ITERATE (4) (s[x=1] = s[x=1]/2)
This statement specifies that the formula
s[x=1] = s[x=1]/2evaluation be repeated four times. The number of iterations is specified in theITERATEoption of theMODELclause. It is also possible to specify a termination condition by using anUNTILclause.Iterative rule evaluation is an important tool for modeling recursive relationships between entities in a business application. For example, a loan amount might depend on the interest rate where the interest rate in turn depends on the amount of the loan.
-
Reference models
A model can include multiple ref models, which are read-only arrays. Rules can reference cells from different reference models. Rules can update or insert cells in only one multi-dimensional array, which is called the main model. The use of reference models enables you to relate models with different dimensionality. For example, assume that, in addition to the fact table
ft(country, year, sales), you have a table with currency conversion ratioscr(country, ratio)withcountryas the dimension column andratioas the measure. Each row in this table gives the conversion ratio of that country's currency to that of US dollar. These two tables could be used in rules such as the following:dollar_sales['Spain',2001] = sales['Spain',2000] * ratio['Spain']
-
Scalable computation
You can partition data and evaluate rules within each partition independent of other partitions. This enables parallelization of model computation based on partitions. For example, consider the following model:
MODEL PARTITION BY (country) DIMENSION BY (year) MEASURES (sales) (sales[year=2001] = AVG(sales)[year BETWEEN 1990 AND 2000]
The data is partitioned by country and, within each partition, you can compute the sales in 2001 to be the average of sales in the years between 1990 and 2000. Partitions can be processed in parallel and this results in a scalable execution of the model.
Basic Topics in SQL Modeling
This section introduces some of the basic ideas and uses for models, and includes:
Base Schema
This chapter's examples are based on the following view sales_view, which is derived from the sh sample schema.
CREATE VIEW sales_view AS SELECT country_name country, prod_name product, calendar_year year, SUM(amount_sold) sales, COUNT(amount_sold) cnt, MAX(calendar_year) KEEP (DENSE_RANK FIRST ORDER BY SUM(amount_sold) DESC) OVER (PARTITION BY country_name, prod_name) best_year, MAX(calendar_year) KEEP (DENSE_RANK LAST ORDER BY SUM(amount_sold) DESC) OVER (PARTITION BY country_name, prod_name) worst_year FROM sales, times, customers, countries, products WHERE sales.time_id = times.time_id AND sales.prod_id = products.prod_id AND sales.cust_id =customers.cust_id AND customers.country_id=countries.country_id GROUP BY country_name, prod_name, calendar_year;
This query computes SUM and COUNT aggregates on the sales data grouped by country, product, and year. It will report for each product sold in a country, the year when the sales were the highest for that product in that country. This is called the best_year of the product. Similarly, worst_year gives the year when the sales were the lowest.
MODEL Clause Syntax
The MODEL clause enables you to define multi-dimensional calculations on the data in the SQL query block. In multi-dimensional applications, a fact table consists of columns that uniquely identify a row with the rest serving as dependent measures or attributes. The MODEL clause lets you specify the PARTITION, DIMENSION, and MEASURE columns that define the multi-dimensional array, the rules that operate on this multi-dimensional array, and the processing options.
The MODEL clause contains a list of updates representing array computation within a partition and is a part of a SQL query block. Its structure is as follows:
MODEL
[<global reference options>]
[<reference models>]
[MAIN <main-name>]
[PARTITION BY (<cols>)]
DIMENSION BY (<cols>)
MEASURES (<cols>)
[<reference options>]
[RULES] <rule options>
(<rule>, <rule>,.., <rule>)
<global reference options> ::= <reference options> <ret-opt>
<ret-opt> ::= RETURN {ALL|UPDATED} ROWS
<reference options> ::=
[IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]
<rule options> ::=
[UPDATE | UPSERT | UPSERT ALL]
[AUTOMATIC ORDER | SEQUENTIAL ORDER]
[ITERATE (<number>) [UNTIL <condition>]]
<reference models> ::= REFERENCE ON <ref-name> ON (<query>)
DIMENSION BY (<cols>) MEASURES (<cols>) <reference options>
Each rule represents an assignment. Its left side references a cell or a set of cells and the right side can contain expressions involving constants, host variables, individual cells or aggregates over ranges of cells. For example, consider Example 23-1.
Example 23-1 Simple Query with the MODEL Clause
SELECT SUBSTR(country,1,20) country, SUBSTR(product,1,15) product, year, sales
FROM sales_view
WHERE country in ('Italy', 'Japan')
MODEL
RETURN UPDATED ROWS
MAIN simple_model
PARTITION BY (country)
DIMENSION BY (product, year)
MEASURES (sales)
RULES
(sales['Bounce', 2001] = 1000,
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001])
ORDER BY country, product, year;
This query defines model computation on the rows from sales_view for the countries Italy and Japan. This model has been given the name simple_model. It partitions the data on country and defines, within each partition, a two-dimensional array on product and year. Each cell in this array holds the value of the sales measure. The first rule of this model sets the sales of Bounce in year 2001 to 1000. The next two rules define that the sales of Bounce in 2002 are the sum of its sales in years 2001 and 2000, and the sales of Y Box in 2002 are same as that of the previous year 2001.
Specifying RETURN UPDATED ROWS makes the preceding query return only those rows that are updated or inserted by the model computation. By default or if you use RETURN ALL ROWS, you would get all rows not just the ones updated or inserted by the MODEL clause. The query produces the following output:
COUNTRY PRODUCT YEAR SALES -------------------- --------------- ---------- ---------- Italy Bounce 2001 1000 Italy Bounce 2002 5333.69 Italy Y Box 2002 81207.55 Japan Bounce 2001 1000 Japan Bounce 2002 6133.53 Japan Y Box 2002 89634.83
Note that the MODEL clause does not update or insert rows into database tables. The following query illustrates this by showing that sales_view has not been altered:
SELECT SUBSTR(country,1,20) country, SUBSTR(product,1,15) product, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan');
COUNTRY PRODUCT YEAR SALES
-------------------- --------------- ---------- ----------
Italy Bounce 1999 2474.78
Italy Bounce 2000 4333.69
Italy Bounce 2001 4846.3
...
Observe that the update of the sales value for Bounce in the 2001 done by this MODEL clause is not reflected in the database. If you want to update or insert rows in the database tables, you should use the INSERT, UPDATE, or MERGE statements.
In the preceding example, columns are specified in the PARTITION BY, DIMENSION BY, and MEASURES list. You can also specify constants, host variables, single-row functions, aggregate functions, analytical functions, or expressions involving them as partition and dimension keys and measures. However, you must alias them in PARTITION BY, DIMENSION BY, and MEASURES lists. You must use aliases to refer these expressions in the rules, SELECT list, and the query ORDER BY. The following example shows how to use expressions and aliases:
SELECT country, p product, year, sales, profits
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL
RETURN UPDATED ROWS
PARTITION BY (SUBSTR(country,1,20) AS country)
DIMENSION BY (product AS p, year)
MEASURES (sales, 0 AS profits)
RULES
(profits['Bounce', 2001] = sales['Bounce', 2001] * 0.25,
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
profits['Bounce', 2002] = sales['Bounce', 2002] * 0.35)
ORDER BY country, year;
COUNTRY PRODUCT YEAR SALES PROFITS
------- --------- ---- -------- --------
Italy Bounce 2001 4846.3 1211.575
Italy Bounce 2002 9179.99 3212.9965
Japan Bounce 2001 6303.6 1575.9
Japan Bounce 2002 11437.13 4002.9955
Note that the alias "0 AS profits" initializes all cells of the profits measure to 0. See Oracle Database SQL Language Reference for more information regarding MODEL clause syntax.
Keywords in SQL Modeling
This section defines keywords used in SQL modeling.
Assigning Values and Null Handling
-
UPSERTThis updates the measure values of existing cells. If the cells do not exist, and the rule has appropriate notation, they are inserted. If any of the cell references are symbolic, no cells are inserted.
-
UPSERTALLThis is similar to
UPSERT, except it allows a broader set of rule notation to insert new cells. -
UPDATEThis updates existing cell values. If the cell values do not exist, no updates are done.
-
IGNORENAVFor numeric cells, this treats values that are not available as 0. This means that a cell not supplied to
MODELby the query result set will be treated as a zero for the calculation. This can be used at a global level for all measures in a model. -
KEEPNAVThis keeps cell values that are not available unchanged. It is useful for making exceptions when
IGNORENAVis specified at the global level. This is the default, and can be omitted.
Calculation Definition
-
MEASURESThe set of values that are modified or created by the model.
-
RULESThe expressions that assign values to measures.
-
AUTOMATICORDERThis causes all rules to be evaluated in an order based on their logical dependencies.
-
SEQUENTIALORDERThis causes rules to be evaluated in the order they are written. This is the default.
-
UNIQUEDIMENSIONThis is the default, and it means that the combination of
PARTITIONBYandDIMENSIONBYcolumns in theMODELclause must uniquely identify each and every cell in the model. This uniqueness is explicitly verified at query execution when necessary, in which case it may increase processing time. -
UNIQUESINGLEREFERENCEThe
PARTITIONBYandDIMENSIONBYclauses uniquely identify single point references on the right-hand side of the rules. This may reduce processing time by avoiding explicit checks for uniqueness at query execution. -
RETURN[ALL|UPDATED] ROWSThis enables you to specify whether to return all rows selected or only those rows updated by the rules. The default is
ALL, while the alternative isUPDATEDROWS.
Cell Referencing
In the MODEL clause, a relation is treated as a multi-dimensional array of cells. A cell of this multi-dimensional array contains the measure values and is indexed using DIMENSION BY keys, within each partition defined by the PARTITION BY keys. For example, consider the following:
SELECT country, product, year, sales, best_year, best_year FROM sales_view MODEL PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales, best_year) (<rules> ..) ORDER BY country, product, year;
This partitions the data by country and defines within each partition, a two-dimensional array on product and year. The cells of this array contain two measures: sales and best_year.
Accessing the measure value of a cell by specifying the DIMENSION BY keys constitutes a cell reference. An example of a cell reference is as follows:
sales[product= 'Bounce', year=2000]
Here, we are accessing the sales value of a cell referenced by product Bounce and the year 2000. In a cell reference, you can specify DIMENSION BY keys either symbolically as in the preceding cell reference or positionally as in sales['Bounce', 2000].
Symbolic Dimension References
A symbolic dimension reference (or symbolic reference) is one in which DIMENSION BY key values are specified with a boolean expression. For example, the cell reference sales[year >= 2001] has a symbolic reference on the DIMENSION BY key year and specifies all cells whose year value is greater than or equal to 2001. An example of symbolic references on product and year dimensions is sales[product = 'Bounce', year >= 2001].
Positional Dimension References
A positional dimension reference (or positional reference, in short) is a constant or a constant expression specified for a dimension. For example, the cell reference sales['Bounce'] has a positional reference on the product dimension and accesses sales value for the product Bounce. The constants (or constant expressions) in a cell reference are matched to the column order specified for DIMENSION BY keys. The following example shows the usage of positional references on dimensions:
sales['Bounce', 2001]
Assuming DIMENSION BY keys to be product and year in that order, it accesses the sales value for Bounce and 2001.
Based on how they are specified, cell references are either single cell or multi-cell reference.
Rules
Model computation is expressed in rules that manipulate the cells of the multi-dimensional array defined by PARTITION BY, DIMENSION BY, and MEASURES clauses. A rule is an assignment statement whose left side represents a cell or a range of cells and whose right side is an expression involving constants, bind variables, individual cells or an aggregate function on a range of cells. Rules can use wild cards and looping constructs for maximum expressiveness. An example of a rule is the following:
sales['Bounce', 2003] = 1.2 * sales['Bounce', 2002]
This rule says that, for the product Bounce, the sales for 2003 are 20% more than that of 2002.
Note that this rule refers to single cells on both the left and right side and is relatively simple. Complex rules can be written with multi-cell references, aggregates, and nested cell references. These are discussed in the following sections.
Single Cell References
This type of rule involves single cell reference on the left side with constants and single cell references on the right side. Some examples are the following:
sales[product='Finding Fido', year=2003] = 100000 sales['Bounce', 2003] = 1.2 * sales['Bounce', 2002] sales[product='Finding Fido', year=2004] = 0.8 * sales['Standard Mouse Pad', year=2003] + sales['Finding Fido', 2003]
Multi-Cell References on the Right Side
Multi-cell references can be used on the right side of rules, in which case an aggregate function needs to be applied on them to convert them to a single value. All existing aggregate functions including analytic aggregates (inverse percentile functions, hypothetical rank and distribution functions and so on) and statistical aggregates (correlation, regression slope and so on), and user-defined aggregate functions can be used. Windowing functions such as RANK and MOVING_AVG can be used as well. For example, the rule to compute the sales of Bounce for 2003 to be 100 more than the maximum sales in the period 1998 to 2002 would be:
sales['Bounce', 2003] = 100 + MAX(sales)['Bounce', year BETWEEN 1998 AND 2002]
The following example illustrates the usage of inverse percentile function PERCENTILE_DISC. It projects Finding Fido sales for year 2003 to be 30% more than the median sales for products Finding Fido, Standard Mouse Pad, and Boat for all years prior to 2003.
sales[product='Finding Fido', year=2003] = 1.3 *
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY sales) [product IN ('Finding
Fido','Standard Mouse Pad','Boat'), year < 2003]
Aggregate functions can appear only on the right side of rules. Arguments to the aggregate function can be constants, bind variables, measures of the MODEL clause, or expressions involving them. For example, the rule computes the sales of Bounce for 2003 to be the weighted average of its sales for years from 1998 to 2002 would be:
sales['Bounce', 2003] = AVG(sales * weight)['Bounce', year BETWEEN 1998 AND 2002]
Multi-Cell References on the Left Side
Rules can have multi-cell references on the left side as in the following:
sales['Standard Mouse Pad', year > 2000] = 0.2 * sales['Finding Fido', year=2000]
This rule accesses a range of cells on the left side (cells for product Standard Mouse Pad and year greater than 2000) and assigns sales measure of each such cell to the value computed by the right side expression. Computation by the preceding rule is described as "sales of Standard Mouse Pad for years after 2000 is 20% of the sales of Finding Fido for year 2000". This computation is simple in that the right side cell references and hence the right side expression are the same for all cells referenced on the left.
Use of the CV Function
The use of the CV function provides the capability of relative indexing where dimension values of the cell referenced on the left side are used on the right side cell references. The CV function takes a dimension key as its argument, so it provides the value of a DIMENSION BY key of the cell currently referenced on the left side. As an example, consider the following:
sales[product='Standard Mouse Pad', year>2000] = sales[CV(product), CV(year)] + 0.2 * sales['Finding Fido', 2000]
When the left side references the cell Standard Mouse Pad and 2001, the right side expression would be:
sales['Standard Mouse Pad', 2001] + 0.2 * sales['Finding Fido', 2000]
Similarly, when the left side references the cell Standard Mouse Pad and 2002, the right side expression we would evaluate is:
sales['Standard Mouse Pad', 2002] + 0.2 * sales['Finding Fido', 2000]
It is also possible to use CV without any argument as in CV() and in which case, positional referencing is implied. CV() may be used outside a cell reference, but when used in this way its argument must contain the name of the dimension desired. You can also write the preceding rule as:
sales[product='Standard Mouse Pad', year>2000] = sales[CV(), CV()] + 0.2 * sales['Finding Fido', 2000]
The first CV() reference corresponds to CV(product) and the latter corresponds to CV(year). The CV function can be used only in right side cell references. Another example of the usage of CV function is the following:
sales[product IN ('Finding Fido','Standard Mouse Pad','Bounce'), year
BETWEEN 2002 AND 2004] = 2 * sales[CV(product), CV(year)-10]
This rule says that, for products Finding Fido, Standard Mouse Pad, and Bounce, the sales for years between 2002 and 2004 will be twice of what their sales were 10 years ago.
Use of the ANY Wildcard
You can use the wild card ANY in cell references to match all dimension values including nulls. ANY may be used on both the left and right side of rules. For example, a rule for the computation "sales of all products for 2003 are 10% more than their sales for 2002" would be the following:
sales[product IS ANY, 2003] = 1.1 * sales[CV(product), 2002]
Using positional references, it can also be written as:
sales[ANY, 2003] = 1.1 * sales[CV(), 2002]
Note that ANY is treated as a symbolic reference even if it is specified positionally, because it really means that (dimension IS NOT NULL OR dimension IS NULL).
Nested Cell References
Cell references can be nested. In other words, cell references providing dimension values can be used within a cell reference. An example, assuming best_year is a measure, for nested cell reference is given as follows:
sales[product='Bounce', year = best_year['Bounce', 2003]]
Here, the nested cell reference best_year['Bounce', 2003] provides value for the dimension key year and is used in the symbolic reference for year. Measures best_year and worst_year give, for each year (y) and product (p) combination, the year for which sales of product p were highest or lowest. The following rule computes the sales of Standard Mouse Pad for 2003 to be the average of Standard Mouse Pad sales for the years in which Finding Fido sales were highest and lowest:
sales['Standard Mouse Pad', 2003] = (sales[CV(), best_year['Finding Fido', CV(year)]] + sales[CV(), worst_year['Finding Fido', CV(year)]]) / 2
Oracle Database allows only one level of nesting, and only single cell references can be used as nested cell references. Aggregates on multi-cell references cannot be used in nested cell references.
Order of Evaluation of Rules
By default, rules are evaluated in the order they appear in the MODEL clause. You can specify an optional keyword SEQUENTIAL ORDER in the MODEL clause to make such an evaluation order explicit. SQL models with sequential rule order of evaluation are called sequential order models. For example, the following RULES specification makes Oracle Database evaluate rules in the specified sequence:
RULES SEQUENTIAL ORDER
(sales['Bounce', 2001] =
sales['Bounce', 2000] + sales['Bounce', 1999], --Rule R1
sales['Bounce', 2000] = 50000, --Rule R2
sales['Bounce', 1999] = 40000) --Rule R3
Alternatively, the option AUTOMATIC ORDER enables Oracle Database to determine the order of evaluation of rules automatically. Oracle examines the cell references within rules and finds dependencies among rules. If cells referenced on the left side of rule R1 are referenced on the right side of another rule R2, then R2 is considered to depend on R1. In other words, rule R1 should be evaluated before rule R2. If you specify AUTOMATIC ORDER in the preceding example as in:
RULES AUTOMATIC ORDER (sales['Bounce', 2001] = sales['Bounce', 2000] + sales['Bounce', 1999], sales['Bounce', 2000] = 50000, sales['Bounce', 1999] = 40000)
Rules 2 and 3 are evaluated, in some arbitrary order, before rule 1. This is because rule 1 depends on rules 2 and 3 and hence need to be evaluated after rules 2 and 3. The order of evaluation among second and third rules can be arbitrary as they do not depend on one another. The order of evaluation among rules independent of one another can be arbitrary. SQL models with an automatic order of evaluation, as in the preceding fragment, are called automatic order models.
In an automatic order model, multiple assignments to the same cell are not allowed. In other words, measure of a cell can be assigned only once. Oracle Database will return an error in such cases as results would be non-deterministic. For example, the following rule specification will generate an error as sales['Bounce', 2001] is assigned more than once:
RULES AUTOMATIC ORDER (sales['Bounce', 2001] = sales['Bounce', 2000] + sales['Bounce', 1999], sales['Bounce', 2001] = 50000, sales['Bounce', 2001] = 40000)
The rules assigning the sales of product Bounce for 2001 do not depend on one another and hence, no particular evaluation order can be fixed among them. This leads to non-deterministic results as the evaluation order is arbitrary - sales['Bounce', 2001] can be 40000 or 50000 or sum of Bounce sales for years 1999 and 2000. Oracle Database prevents this by disallowing multiple assignments when AUTOMATIC ORDER is specified. However, multiple assignments are fine in sequential order models. If SEQUENTIAL ORDER was specified instead of AUTOMATIC ORDER in the preceding example, the result of sales['Bounce', 2001] would be 40000.
Global and Local Keywords for Rules
You can specify an UPDATE, UPSERT, UPSERT ALL, IGNORE NAV, and KEEP NAV option at the global level in the RULES clause in which case all rules operate in the respective mode. These options can be specified at a local level with each rule and in which case, they override the global behavior. For example, in the following specification:
RULES UPDATE (UPDATE s['Bounce',2001] = sales['Bounce',2000] + sales['Bounce',1999], UPSERT s['Y Box', 2001] = sales['Y Box', 2000] + sales['Y Box', 1999], sales['Mouse Pad', 2001] = sales['Mouse Pad', 2000] + sales['Mouse Pad',1999])
The UPDATE option is specified at the global level so, the first and third rules operate in update mode. The second rule operates in upsert mode as an UPSERT keyword is specified with that rule. Note that no option was specified for the third rule and hence it inherits the update behavior from the global option.
UPDATE, UPSERT, and UPSERT ALL Behavior
You can determine how cells in rules behave by choosing whether to have UPDATE, UPSERT, or UPSERT ALL semantics. By default, rules in the MODEL clause have UPSERT semantics, though you can specify an optional UPSERT keyword to make the upsert semantic explicit.
The following sections discuss these three types of behavior:
UPDATE Behavior
The UPDATE option forces strict update mode. In this mode, the rule is ignored if the cell it references on the left side does not exist. If the cell referenced on the left side of a rule exists, then its measure is updated with the value of the right side expression. Otherwise, if a cell reference is positional, a new cell is created (that is, inserted into the multi-dimensional array) with the measure value equal to the value of the right side expression. If a cell reference is not positional, it will not insert cells. Note that if there are any symbolic references in a cell's specification, inserts are not possible in an upsert rule. For example, consider the following rule:
sales['Bounce', 2003] = sales['Bounce', 2001] + sales ['Bounce', 2002]
The cell for product Bounce and year 2003, if it exists, gets updated with the sum of Bounce sales for years 2001 and 2002, otherwise, it gets created. If you had created the same rule using any symbolic references, no updates would be performed, as in the following:
sales[prod= 'Bounce', year= 2003] = sales['Bounce', 2001] + sales ['Bounce', 2002]
UPSERT Behavior
Using UPSERT creates a new cell corresponding to the one referenced on the left side of the rule when the cell is missing, and the cell reference contains only positional references qualified by constants. Note that cell references created with FOR loops (described in "Advanced Topics in SQL Modeling") are treated as positional references, so the values FOR loops create will be used to insert new cells. Assuming you do not have cells for years greater than 2003, consider the following rule:
UPSERT sales['Bounce', year = 2004] = 1.1 * sales['Bounce', 2002]
This would not create any new cell because of the symbolic reference year = 2004. However, consider the following:
UPSERT sales['Bounce', 2004] = 1.1 * sales['Bounce', 2002]
This would create a new cell for product Bounce for year 2004. On a related note, new cells will not be created if any of the references is ANY. This is because ANY is a predicate that qualifies all dimensional values including NULL. If there is a reference ANY for a dimension d, then it means the same thing as the predicate (d IS NOT NULL OR d IS NULL).
If an UPSERT rule uses FOR loops in its left side cell references, the list of upsert cells is generated by performing a cross product of all the distinct values for each dimension. Although UPSERT with FOR loops can be used to densify dimensions (see "Data Densification for Reporting"), it is generally preferable to densify using the partition outer join operation.
UPSERT ALL Behavior
UPSERT ALL behavior allows model rules with existential predicates (comparisons, IN, ANY, and so on) in their left side to have UPSERT behavior. As an example, the following uses ANY and creates Bay Area as the combination of San Francisco, San Jose, and Oakland:
SELECT product, time, city, s sales
FROM cube_subquery
MODEL PARTITION BY (product)
DIMENSION BY (time, city) MEASURES(sales s
RULES UPSERT ALL
(s[ANY, 'Bay Area'] =
s[CV(), 'San Francisco'] + s[CV(), 'San Jose'] + s[CV(), 'Oakland']
s['2004', ANY] = s['2002', CV()] + s['2003', CV()]);
In this example, the first rule simply inserts a Bay Area cell for each distinct time value, and the second rule inserts a 2004 cell for each distinct city value including Bay Area. This example is relatively simple as the existential predicates used on the left side are ANY predicates, but you can also use UPSERT ALL with more complex calculations.
It is important to understand exactly what the UPSERT ALL operation does, especially in cases where there is more than one symbolic dimension reference. Note that the behavior is different than the behavior of an UPSERT rule that uses FOR loops. When evaluating an UPSERT ALL rule, Oracle Database performs the following steps to create a list of cell references to be upserted.
- Step 1 Find Cells
-
Find the existing cells that satisfy all the symbolic predicates of the cell reference.
- Step 2 Find Distinct Dimension Values
-
Using just the dimensions that have symbolic references, find the distinct dimension value combinations of these cells.
- Step 3 Perform a Cross Product
-
Perform a cross product of these value combinations with the dimension values specified through positional references.
- Step 4 Upsert New Cells
-
The results of Step 3 are then used to upsert new cells into the array.
To illustrate these four steps, here is a brief example using abstracted data and a model with three dimensions. Consider a model dimensioned by (
product,time,city) with a measure calledsales. We wish to upsert new sales values for the city ofz, and these sales values are copied from those of the city ofy.
UPSERT ALL sales[ANY, ANY, 'z']= sales[CV(product),CV(time),'y']
Our source data set has these four rows:
PROD TIME CITY SALES 1 2002 x 10 1 2003 x 15 2 2002 y 21 2 2003 y 24
The following explains the details of the four steps, applied to this data:
-
Because the symbolic predicates of the rule are
ANY, any of the rows shown in this example is acceptable. -
The distinct dimension combinations of cells with symbolic predicates that match the condition are: (1, 2002), (1, 2003), (2, 2002), and (2, 2003).
-
We find the cross product of these dimension combinations with the cells specified with positional references. In this case, it is simply a cross product with the value
z, and the resulting cell references are: (1, 2002, z), (1, 2003, z), (2, 2002, z), and (2, 2003, z). -
The cells listed in Step 3 will be upserted, with sales calculated based on the city
y. Because there are no values for product 1 in cityy, those cells created for product 1 will haveNULLas their sales value. Of course, a different rule might have generated non-NULLresults for all the new cells. Our result set includes the four original rows plus four new rows:
PROD TIME CITY SALES 1 2002 x 10 1 2003 x 15 2 2002 y 21 2 2003 y 24 1 2002 z NULL 1 2003 z NULL 2 2002 z 21 2 2003 z 24
It is important to note that these results are not a cross product using all values of all dimensions. If that were the case, we would have cells such as (1,2002, y) and (2,2003, x). Instead, the results here are created using dimension combinations found in existing rows.
Treatment of NULLs and Missing Cells
Applications using models would not only have to deal with non-deterministic values for a cell measure in the form of NULL, but also with non-determinism in the form of missing cells. A cell, referenced by a single cell reference, that is missing in the data is called a missing cell. The MODEL clause provides a default treatment for nulls and missing cells that is consistent with the ANSI SQL standard and also provides options to treat them in other useful ways according to business logic, for example, to treat nulls as zero for arithmetic operations.
By default, NULL cell measure values are treated the same way as nulls are treated elsewhere in SQL. For example, in the following rule:
sales['Bounce', 2001] = sales['Bounce', 1999] + sales['Bounce', 2000]
The right side expression would evaluate to NULL if Bounce sales for one of the years 1999 and 2000 is NULL. Similarly, aggregate functions in rules would treat NULL values in the same way as their regular behavior where NULL values are ignored during aggregation.
Missing cells are treated as cells with NULL measure values. For example, in the preceding rule, if the cell for Bounce and 2000 is missing, then it is treated as a NULL value and the right side expression would evaluate to NULL.
Distinguishing Missing Cells from NULLs
The functions PRESENTV and PRESENTNNV enable you to identify missing cells and distinguish them from NULL values. These functions take a single cell reference and two expressions as arguments as in PRESENTV(cell, expr1, expr2). PRESENTV returns the first expression expr1 if the cell cell is existent in the data input to the MODEL clause. Otherwise, it returns the second expression expr2. For example, consider the following:
PRESENTV(sales['Bounce', 2000], 1.1*sales['Bounce', 2000], 100)
If the cell for product Bounce and year 2000 exists, it returns the corresponding sales multiplied by 1.1, otherwise, it returns 100. Note that if sales for the product Bounce for year 2000 is NULL, the preceding specification would return NULL.
The PRESENTNNV function not only checks for the presence of a cell but also whether it is NULL or not. It returns the first expression expr1 if the cell exists and is not NULL, otherwise, it returns the second expression expr2. For example, consider the following:
PRESENTNNV(sales['Bounce', 2000], 1.1*sales['Bounce', 2000], 100)
This would return 1.1*sales['Bounce', 2000] if sales['Bounce', 2000] exists and is not NULL. Otherwise, it returns 100.
Applications can use the IS PRESENT predicate in their model to check the presence of a cell in an explicit fashion.This predicate returns TRUE if cell exists and FALSE otherwise. The preceding example using PRESENTNNV can be written using IS PRESENT as:
CASE WHEN sales['Bounce', 2000] IS PRESENT AND sales['Bounce', 2000] IS NOT NULL THEN 1.1 * sales['Bounce', 2000] ELSE 100 END
The IS PRESENT predicate, like the PRESENTV and PRESENTNNV functions, checks for cell existence in the input data, that is, the data as existed before the execution of the MODEL clause. This enables you to initialize multiple measures of a cell newly inserted by an UPSERT rule. For example, if you want to initialize sales and profit values of a cell, if it does not exist in the data, for product Bounce and year 2003 to 1000 and 500 respectively, you can do so by the following:
RULES
(UPSERT sales['Bounce', 2003] =
PRESENTV(sales['Bounce', 2003], sales['Bounce', 2003], 1000),
UPSERT profit['Bounce', 2003] =
PRESENTV(profit['Bounce', 2003], profit['Bounce', 2003], 500))
The PRESENTV functions used in this formulation return TRUE or FALSE based on the existence of the cell in the input data. If the cell for Bounce and 2003 gets inserted by one of the rules, based on their evaluation order, PRESENTV function in the other rule would still evaluate to FALSE. You can consider this behavior as a preprocessing step to rule evaluation that evaluates and replaces all PRESENTV and PRESENTNNV functions and IS PRESENT predicate by their respective values.
Use Defaults for Missing Cells and NULLs
The MODEL clause, by default, treats missing cells as cells with NULL measure values. An optional KEEP NAV keyword can be specified in the MODEL clause to get this behavior.If your application wants to default missing cells and nulls to some values, you can do so by using IS PRESENT, IS NULL predicates and PRESENTV, PRESENTNNV functions. But it may become cumbersome if you have lot of single cell references and rules. You can use IGNORE NAV option instead of the default KEEP NAV option to default nulls and missing cells to:
-
0 for numeric data
-
Empty string for character/string data
-
01-JAN-2001 for data type data
-
NULLfor all other data types
Consider the following query:
SELECT product, year, sales FROM sales_view WHERE country = 'Poland' MODEL DIMENSION BY (product, year) MEASURES (sales sales) IGNORE NAV RULES UPSERT (sales['Bounce', 2003] = sales['Bounce', 2002] + sales['Bounce', 2001]);
In this, the input to the MODEL clause does not have a cell for product Bounce and year 2002. Because of IGNORE NAV option, sales['Bounce', 2002] value would default to 0 (as sales is of numeric type) instead of NULL. Thus, sales['Bounce', 2003] value would be same as that of sales['Bounce', 2001].
Using NULLs in a Cell Reference
To use NULL values in a cell reference, you must use one of the following:
-
Positional reference using wild card
ANYas insales[ANY]. -
Symbolic reference using the
ISANYpredicate as insales[product IS ANY]. -
Positional reference of
NULLas insales[NULL]. -
Symbolic reference using
ISNULLpredicate as insales[product IS NULL].
Note that symbolic reference sales[product = NULL] would not test for nulls in the product dimension. This behavior conforms with the standard handling of nulls by SQL.
Reference Models
In addition to the multi-dimensional array on which rules operate, which is called the main model, one or more read-only multi-dimensional arrays, called reference models, can be created and referenced in the MODEL clause to act as look-up tables for the main model. Like the main model, a reference model is defined over a query block and has DIMENSION BY and MEASURES clauses to indicate its dimensions and measures respectively. A reference model is created by the following subclause:
REFERENCE model_name ON (query) DIMENSION BY (cols) MEASURES (cols) [reference options]
Like the main model, a multi-dimensional array for the reference model is built before evaluating the rules. But, unlike the main model, reference models are read-only in that their cells cannot be updated and no new cells can be inserted after they are built. Thus, the rules in the main model can access cells of a reference model, but they cannot update or insert new cells into the reference model. The following is an example using a currency conversion table as a reference model:
CREATE TABLE dollar_conv_tbl(country VARCHAR2(30), exchange_rate NUMBER);
INSERT INTO dollar_conv_tbl VALUES('Poland', 0.25);
INSERT INTO dollar_conv_tbl VALUES('France', 0.14);
...
Now, to convert the projected sales of Poland and France for 2003 to the US dollar, you can use the dollar conversion table as a reference model as in the following:
SELECT country, year, sales, dollar_sales
FROM sales_view
GROUP BY country, year
MODEL
REFERENCE conv_ref ON (SELECT country, exchange_rate FROM dollar_conv_tbl)
DIMENSION BY (country) MEASURES (exchange_rate) IGNORE NAV
MAIN conversion
DIMENSION BY (country, year)
MEASURES (SUM(sales) sales, SUM(sales) dollar_sales) IGNORE NAV
RULES
(dollar_sales['France', 2003] = sales[CV(country), 2002] * 1.02 *
conv_ref.exchange_rate['France'],
dollar_sales['Poland', 2003] =
sales['Poland', 2002] * 1.05 * exchange_rate['Poland']);
Observe in this example that:
-
A one dimensional reference model named
conv_refis created on rows from the tabledollar_conv_tbland that its measureexchange_ratehas been referenced in the rules of the main model. -
The main model (called
conversion) has two dimensions, country and year, whereas the reference modelconv_refhas one dimension, country. -
Different styles of accessing the
exchange_ratemeasure of the reference model. For France, it is rather explicit withmodel_name.measure_namenotationconv_ref.exchange_rate, whereas for Poland, it is a simplemeasure_namereferenceexchange_rate. The former notation needs to be used to resolve any ambiguities in column names across main and reference models.
Growth rates, in this example, are hard coded in the rules. The growth rate for France is 2% and that of Poland is 5%. But they could come from a separate table and you can have a reference model defined on top of that. Assume that you have a growth_rate(country, year, rate) table defined as the following:
CREATE TABLE growth_rate_tbl(country VARCHAR2(30),
year NUMBER, growth_rate NUMBER);
INSERT INTO growth_rate_tbl VALUES('Poland', 2002, 2.5);
INSERT INTO growth_rate_tbl VALUES('Poland', 2003, 5);
...
INSERT INTO growth_rate_tbl VALUES('France', 2002, 3);
INSERT INTO growth_rate_tbl VALUES('France', 2003, 2.5);
Then the following query computes the projected sales in dollars for 2003 for all countries:
SELECT country, year, sales, dollar_sales
FROM sales_view
GROUP BY country, year
MODEL
REFERENCE conv_ref ON
(SELECT country, exchange_rate FROM dollar_conv_tbl)
DIMENSION BY (country c) MEASURES (exchange_rate) IGNORE NAV
REFERENCE growth_ref ON
(SELECT country, year, growth_rate FROM growth_rate_tbl)
DIMENSION BY (country c, year y) MEASURES (growth_rate) IGNORE NAV
MAIN projection
DIMENSION BY (country, year) MEASURES (SUM(sales) sales, 0 dollar_sales)
IGNORE NAV
RULES
(dollar_sales[ANY, 2003] = sales[CV(country), 2002] *
growth_rate[CV(country), CV(year)] *
exchange_rate[CV(country)]);
This query shows the capability of the MODEL clause in dealing with and relating objects of different dimensionality. Reference model conv_ref has one dimension while the reference model growth_ref and the main model have two dimensions. Dimensions in the single cell references on reference models are specified using the CV function thus relating the cells in main model with the reference model. This specification, in effect, is performing a relational join between main and reference models.
Reference models also help you convert keys to sequence numbers, perform computations using sequence numbers (for example, where a prior period would be used in a subtraction operation), and then convert sequence numbers back to keys. For example, consider a view that assigns sequence numbers to years:
CREATE or REPLACE VIEW year_2_seq (i, year) AS SELECT ROW_NUMBER() OVER (ORDER BY calendar_year), calendar_year FROM (SELECT DISTINCT calendar_year FROM TIMES);
This view can define two lookup tables: integer-to-year i2y, which maps sequence numbers to integers, and year-to-integer y2i, which performs the reverse mapping. The references y2i.i[year] and y2i.i[year] - 1 return sequence numbers of the current and previous years respectively and the reference i2y.y[y2i.i[year]-1] returns the year key value of the previous year. The following query demonstrates such a usage of reference models:
SELECT country, product, year, sales, prior_period FROM sales_view MODEL REFERENCE y2i ON (SELECT year, i FROM year_2_seq) DIMENSION BY (year y) MEASURES (i) REFERENCE i2y ON (SELECT year, i FROM year_2_seq) DIMENSION BY (i) MEASURES (year y) MAIN projection2 PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales, CAST(NULL AS NUMBER) prior_period) (prior_period[ANY, ANY] = sales[CV(product), i2y.y[y2i.i[CV(year)]-1]]) ORDER BY country, product, year;
Nesting of reference model cell references is evident in the preceding example. Cell reference on the reference model y2i is nested inside the cell reference on i2y which, in turn, is nested in the cell reference on the main SQL model. There is no limitation on the levels of nesting you can have on reference model cell references. However, you can only have two levels of nesting on the main SQL model cell references.
Finally, the following are restrictions on the specification and usage of reference models:
-
Reference models cannot have a
PARTITIONBYclause. -
The query block on which the reference model is defined cannot be correlated to an outer query.
-
Reference models must be named and their names should be unique.
-
All references to the cells of a reference model should be single cell references.
Advanced Topics in SQL Modeling
This section discusses more advanced topics in SQL modeling, and includes:
FOR Loops
The MODEL clause provides a FOR construct that can be used inside rules to express computations more compactly. It can be used on both the left and right side of a rule. FOR loops are treated as positional references when on the left side of a rule. For example, consider the following computation, which estimates the sales of several products for 2004 to be 10% higher than their sales for 2003:
RULES UPSERT (sales['Bounce', 2004] = 1.1 * sales['Bounce', 2003], sales['Standard Mouse Pad', 2004] = 1.1 * sales['Standard Mouse Pad', 2003], ... sales['Y Box', 2004] = 1.1 * sales['Y Box', 2003])
The UPSERT option is used in this computation so that cells for these products and 2004 will be inserted if they are not previously present in the multi-dimensional array. This is rather bulky as you have to have as many rules as there are products. Using the FOR construct, this computation can be represented compactly and with exactly the same semantics as in:
RULES UPSERT
(sales[FOR product IN ('Bounce', 'Standard Mouse Pad', ..., 'Y Box'), 2004] =
1.1 * sales[CV(product), 2003])
If you write a specification similar to this, but without the FOR keyword as in the following:
RULES UPSERT
(sales[product IN ('Bounce', 'Standard Mouse Pad', ..., 'Y Box'), 2004] =
1.1 * sales[CV(product), 2003])
You would get UPDATE semantics even though you have specified UPSERT. In other words, existing cells will be updated but no new cells will be created by this specification. This is because the multi-cell reference on product is a symbolic reference and symbolic references do not permit insertion of new cells. You can view a FOR construct as a macro that generates multiple rules with positional references from a single rule, thus preserving the UPSERT semantics. Conceptually, the following rule:
sales[FOR product IN ('Bounce', 'Standard Mouse Pad', ..., 'Y Box'),
FOR year IN (2004, 2005)] = 1.1 * sales[CV(product), CV(year)-1]
Can be treated as an ordered collection of the following rules:
sales['Bounce', 2004] = 1.1 * sales[CV(product), CV(year)-1], sales['Bounce', 2005] = 1.1 * sales[CV(product), CV(year)-1], sales['Standard Mouse Pad', 2004] = 1.1 * sales[CV(product), CV(year)-1], sales['Standard Mouse Pad', 2005] = 1.1 * sales[CV(product), CV(year)-1], ... sales['Y Box', 2004] = 1.1 * sales[CV(product), CV(year)-1], sales['Y Box', 2005] = 1.1 * sales[CV(product), CV(year)-1]
The FOR construct in the preceding examples is of type FOR dimension IN (list of values). Values in the list should be single-value expressions such as expressions of constants, single-cell references, and so on. In the last example, there are separate FOR constructs on product and year. It is also possible to specify all dimensions using one FOR construct and specify the values using multi-column IN lists. Consider for example, if we want only to estimate sales for Bounce in 2004, Standard Mouse Pad in 2005 and Y Box in 2004 and 2005. This can be formulated as the following:
sales[FOR (product, year) IN (('Bounce', 2004), ('Standard Mouse Pad', 2005),
('Y Box', 2004), ('Y Box', 2005))] =
1.1 * sales[CV(product), CV(year)-1]
This FOR construct should be of the form FOR (d1, ..., dn) IN ((d1_val1, ..., dn_val1), ..., (d1_valm, ..., dn_valm)] when there are n dimensions d1, ..., dn and m values in the list.
In some cases, the list of values for a dimension in FOR can be retrieved from a table or a subquery. Oracle Database provides a type of FOR construct as in FOR dimension IN (subquery) to handle these cases. For example, assume that the products of interest are stored in a table interesting_products, then the following rule estimates their sales in 2004 and 2005:
sales[FOR product IN (SELECT product_name FROM interesting_products)
FOR year IN (2004, 2005)] = 1.1 * sales[CV(product), CV(year)-1]
As another example, consider the scenario where you want to introduce a new country, called new_country, with sales that mimic those of Poland for all products and years where there are sales in Poland. This is accomplished by issuing the following statement:
SELECT country, product, year, s
FROM sales_view
MODEL
DIMENSION BY (country, product, year)
MEASURES (sales s) IGNORE NAV
RULES UPSERT
(s[FOR (country, product, year) IN
(SELECT DISTINCT 'new_country', product, year
FROM sales_view
WHERE country = 'Poland')] = s['Poland',CV(),CV()])
ORDER BY country, year, product;
Note the multi-column IN-list produced by evaluating the subquery in this specification. The subquery used to obtain the IN-list cannot be correlated to outer query blocks.
Note that the upsert list created by the rule is a cross-product of the distinct values for each dimension. For example, if there are 10 values for country, 5 values for year, and 3 values for product, we will generate an upsert list containing 150 cells.
If you know that the values of interest come from a discrete domain, you can use FOR construct FOR dimension FROM value1 TO value2 [INCREMENT | DECREMENT] value3. This specification results in values between value1 and value2 by starting from value1 and incrementing (or decrementing) by value3. The values value1, value2, and value3 should be single-value expressions. For example, the following rule:
sales['Bounce', FOR year FROM 2001 TO 2005 INCREMENT 1] = sales['Bounce', year=CV(year)-1] * 1.2
This is semantically equivalent to the following rules in order:
sales['Bounce', 2001] = sales['Bounce', 2000] * 1.2, sales['Bounce', 2002] = sales['Bounce', 2001] * 1.2, ... sales['Bounce', 2005] = sales['Bounce', 2004] * 1.2
This kind of FOR construct can be used for dimensions of numeric, date and datetime data types. The type for increment/decrement expression value3 should be numeric for numeric dimensions and can be numeric or interval for dimensions of date or datetime types. Also, value3 should be positive. Oracle Database returns an error if you use FOR year FROM 2005 TO 2001 INCREMENT -1. You should use either FOR year FROM 2005 TO 2001 DECREMENT 1 or FOR year FROM 2001 TO 2005 INCREMENT 1.
To generate string values, you can use the FOR construct FOR dimension LIKE string FROM value1 TO value2 [INCREMENT | DECREMENT] value3. The string string should contain only one % character. This specification results in string by replacing % with values between value1 and value2 with appropriate increment/decrement value value3. For example, consider the following rule:
sales[FOR product LIKE 'product-%' FROM 1 TO 3 INCREMENT 1, 2003] = sales[CV(product), 2002] * 1.2
This is equivalent to the following:
sales['product-1', 2003] = sales['product-1', 2002] * 1.2, sales['product-2', 2003] = sales['product-2', 2002] * 1.2, sales['product-3', 2003] = sales['product-3', 2002] * 1.2
In SEQUENTIAL ORDER models, rules represented by a FOR construct are evaluated in the order they are generated. On the contrary, rule evaluation order would be dependency based if AUTOMATIC ORDER is specified. For example, the evaluation order for the rules represented by the rule:
sales['Bounce', FOR year FROM 2004 TO 2001 DECREMENT 1] = 1.1 * sales['Bounce', CV(year)-1]
For SEQUENTIAL ORDER models, the rules would be generated in this order:
sales['Bounce', 2004] = 1.1 * sales['Bounce', 2003], sales['Bounce', 2003] = 1.1 * sales['Bounce', 2002], sales['Bounce', 2002] = 1.1 * sales['Bounce', 2001], sales['Bounce', 2001] = 1.1 * sales['Bounce', 2000]
While for AUTOMATIC ORDER models, the order would be equivalent to:
sales['Bounce', 2001] = 1.1 * sales['Bounce', 2000], sales['Bounce', 2002] = 1.1 * sales['Bounce', 2001], sales['Bounce', 2003] = 1.1 * sales['Bounce', 2002], sales['Bounce', 2004] = 1.1 * sales['Bounce', 2003]
Evaluation of Formulas with FOR Loops
The FOR loop construct provides an iterative mechanism to generate single-value references for a dimension or for all dimensions (in the case of multi-column for IN lists). The evaluation of a formula with FOR loops on its left side basically consists of evaluation of the right side of the formula for each single-value reference generated by these FOR loops and assigning the result to the specified cell with this single-value reference. The generation of these single reference values is called "unfolding the FOR loop". These unfolded cells are evaluated in the order they are generated during the unfolding process.
How unfolding is performed depends on the UPSERT, UPDATE, and UPDATE ALL behavior specified for the rule and the specific characteristics of the rule. To understand this, we need to discuss two stages of query processing: query plan creation and query execution. Query plan creation is a stage where certain rule references are resolved in order to create an efficient query execution plan. Query execution is the stage where all remaining unresolved references must be determined. FOR loops may be unfolded at either query plan generation or at query execution. Below we discuss the details of the unfolding decision.
Unfolding For UPDATE and UPSERT Rules
When using UPDATE or UPSERT rules, if unfolding the left side of a rule is guaranteed to generate single cell references, the unfolding is done at query execution. If the unfolding process cannot generate single cell references, unfolding is performed at query plan creation and a copy of the same formula for each generated reference by the unfolding process is created. For example, the unfolding of the following formula occurs at query execution as unfolding generates single cell references:
sales[FOR product IN ('prod1', 'prod2'), 2003] = sales[CV(product), 2002] * 1.2
However, consider the following formula, where unfolding reference values do not produce single value references due to the existence of a predicate on another dimension:
sales[FOR product in ('prod1', 'prod2'), year >= 2003]
= sales[CV(product), 2002] * 1.2
There is no single-value reference on the year dimension, so even when the FOR loop is unfolded on the product dimension, there will be no single-value references on the left side of this formula. This means that the unfolding occurs at query plan creation and physically replace the original formula with the following formulas:
sales['prod1', year >= 2003] = sales[CV(product), 2002] * 1.2, sales['prod2', year >= 2003] = sales[CV(product), 2002] * 1.2
The analysis and optimizations performed within the MODEL clause are done after unfolding at query plan creation (if that is what occurs), so, from that point on, everything is as if the multiple rules are specified explicitly in the MODEL clause. By performing unfolding at query plan creation in these cases, more accurate analysis and better optimization of formula evaluation is achieved. One thing to note is that there may be an increase in the number of formulas and, if this increase pushes the total number of formulas beyond the maximum limit, Oracle Database signals an error.
Unfolding For UPSERT ALL Rules
Rules with UPSERT ALL behavior have a very different approach to unfolding FOR loops. No matter what predicates are used, an UPSERT ALL rule will unfold FOR loops at query execution. This behavior avoids certain FOR loop restrictions discussed in the next section. However, there is a trade-off of fewer restrictions versus more optimized query plans. An UPSERT ALL rule tends toward slower performance than a similar UPSERT or UPDATE rule, and this should be considered when designing models.
Restrictions on Using FOR Loop Expressions on the Left Side of Formulas
Restrictions on the use of FOR loop constructs are determined based on whether the unfolding takes place at query plan creation or at query execution. If a formula with FOR loops on its left side is unfolded at query plan creation (due to the reasons explained in the previous section), the expressions that need to be evaluated for unfolding must be expressions of constants whose values are available at query plan creation. For example, consider the following statement:
sales[For product like 'prod%' from ITERATION_NUMBER to ITERATION_NUMBER+1, year >= 2003] = sales[CV(product), 2002]*1.2
If this rule does not have UPSERT ALL specified for its behavior, it is unfolded at query plan creation. Because the value of the ITERATION_NUMBER is not known at query plan creation, and the value is needed to evaluate start and end expressions, Oracle Database signals an error unless that rule is unfolded at query execution. However, the following rule would be unfolded at query plan creation without any errors: the value of ITERATION_NUMBER is not needed for unfolding in this case, even though it appears as an expression in the FOR loop:
sales[For product in ('prod'||ITERATION_NUMBER, 'prod'||(ITERATION_NUMBER+1)),
year >= 2003] = sales[CV(product), 2002]*1.2
Expressions that have any of the following conditions cannot be evaluated at query plan creation:
-
nested cell references
-
reference model look-ups
-
ITERATION_NUMBERreferences
Rules with FOR loops that require the results of such expressions causes an error if unfolded at query plan creation. However, these expressions will not cause any error if unfolding is done at query execution.
If a formula has subqueries in its FOR loop constructs and this formula requires compile-time unfolding, these subqueries are evaluated at query plan creation so that unfolding can happen. Evaluating a subquery at query plan creation can render a cursor non-sharable, which means the same query may need to be recompiled every time it is issued. If unfolding of such a formula is deferred to query execution, no compile-time evaluation is necessary and the formula has no impact on the sharability of the cursor.
Subqueries in the FOR loops of a formula can reference tables in the WITH clause if the formula is to be unfolded at query execution. If the formula has to be unfolded at query plan creation, Oracle Database signals an error.
Iterative Models
Using the ITERATE option of the MODEL clause, you can evaluate rules iteratively for a certain number of times, which you can specify as an argument to the ITERATE clause. ITERATE can be specified only for SEQUENTIAL ORDER models and such models are referred to as iterative models. For example, consider the following:
SELECT x, s FROM DUAL MODEL DIMENSION BY (1 AS x) MEASURES (1024 AS s) RULES UPDATE ITERATE (4) (s[1] = s[1]/2);
In Oracle, the table DUAL has only one row. Hence this model defines a 1-dimensional array, dimensioned by x with a measure s, with a single element s[1] = 1024. The rule s[1] = s[1]/2 evaluation will be repeated four times. The result of this query is a single row with values 1 and 64 for columns x and s respectively. The number of iterations arguments for the ITERATE clause should be a positive integer constant. Optionally, you can specify an early termination condition to stop rule evaluation before reaching the maximum iteration. This condition is specified in the UNTIL subclause of ITERATE and is checked at the end of an iteration. So, you will have at least one iteration when ITERATE is specified. The syntax of the ITERATE clause is:
ITERATE (number_of_iterations) [ UNTIL (condition) ]
Iterative evaluation stops either after finishing the specified number of iterations or when the termination condition evaluates to TRUE, whichever comes first.
In some cases, you may want the termination condition to be based on the change, across iterations, in value of a cell. Oracle Database provides a mechanism to specify such conditions in that it enables you to access cell values as they existed before and after the current iteration in the UNTIL condition. Oracle's PREVIOUS function takes a single cell reference as an argument and returns the measure value of the cell as it existed after the previous iteration. You can also access the current iteration number by using the system variable ITERATION_NUMBER, which starts at value 0 and is incremented after each iteration. By using PREVIOUS and ITERATION_NUMBER, you can construct complex termination conditions.
Consider the following iterative model that specifies iteration over rules till the change in the value of s[1] across successive iterations falls below 1, up to a maximum of 1000 times:
SELECT x, s, iterations FROM DUAL MODEL DIMENSION BY (1 AS x) MEASURES (1024 AS s, 0 AS iterations) RULES ITERATE (1000) UNTIL ABS(PREVIOUS(s[1]) - s[1]) < 1 (s[1] = s[1]/2, iterations[1] = ITERATION_NUMBER);
The absolute value function (ABS) can be helpful for termination conditions because you may not know if the most recent value is positive or negative. Rules in this model will be iterated over 11 times as after 11th iteration the value of s[1] would be 0.5. This query results in a single row with values 1, 0.5, 10 for x, s and iterations respectively.
You can use the PREVIOUS function only in the UNTIL condition. However, ITERATION_NUMBER can be anywhere in the main model. In the following example, ITERATION_NUMBER is used in cell references:
SELECT country, product, year, sales FROM sales_view MODEL PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales sales) IGNORE NAV RULES ITERATE(3) (sales['Bounce', 2002 + ITERATION_NUMBER] = sales['Bounce', 1999 + ITERATION_NUMBER]);
This statement achieves an array copy of sales of Bounce from cells in the array 1999-2001 to 2002-2005.
Rule Dependency in AUTOMATIC ORDER Models
Oracle Database determines the order of evaluation of rules in an AUTOMATIC ORDER model based on their dependencies. A rule is evaluated only after the rules it depends on are evaluated. The algorithm chosen to evaluate the rules is based on the dependency analysis and whether rules in your model have circular (or cyclical) dependencies. A cyclic dependency can be of the form "rule A depends on B and rule B depends on A" or of the self-cyclic "rule depending on itself" form. An example of the former is:
sales['Bounce', 2002] = 1.5 * sales['Y Box', 2002], sales['Y Box', 2002] = 100000 / sales['Bounce', 2002
An example of the latter is:
sales['Bounce', 2002] = 25000 / sales['Bounce', 2002]
However, there is no self-cycle in the following rule as different measures are being accessed on the left and right side:
projected_sales['Bounce', 2002] = 25000 / sales['Bounce', 2002]
When the analysis of an AUTOMATIC ORDER model finds that the rules have no circular dependencies, Oracle Database evaluates the rules in their dependency order. For example, in the following AUTOMATIC ORDER model:
MODEL DIMENSION BY (prod, year) MEASURES (sale sales) IGNORE NAV
RULES AUTOMATIC ORDER
(sales['SUV', 2001] = 10000,
sales['Standard Mouse Pad', 2001] = sales['Finding Fido', 2001]
* 0.10 + sales['Boat', 2001] * 0.50,
sales['Boat', 2001] = sales['Finding Fido', 2001]
* 0.25 + sales['SUV', 2001]* 0.75,
sales['Finding Fido', 2001] = 20000)
Rule 2 depends on rules 3 and 4, while rule 3 depends on rules 1 and 4, and rules 1 and 4 do not depend on any rule. Oracle, in this case, will find that the rule dependencies are acyclic and evaluate rules in one of the possible evaluation orders (1, 4, 3, 2) or (4, 1, 3, 2). This type of rule evaluation is called an ACYCLIC algorithm.
In some cases, Oracle Database may not be able to ascertain that your model is acyclic even though there is no cyclical dependency among the rules. This can happen if you have complex expressions in your cell references. Oracle Database assumes that the rules are cyclic and employs a CYCLIC algorithm that evaluates the model iteratively based on the rules and data. Iteration stops as soon as convergence is reached and the results are returned. Convergence is defined as the state in which further executions of the model will not change values of any of the cell in the model. Convergence is certain to be reached when there are no cyclical dependencies.
If your AUTOMATIC ORDER model has rules with cyclical dependencies, Oracle Database employs the earlier mentioned CYCLIC algorithm. Results are produced if convergence can be reached within the number of iterations Oracle is going to try the algorithm. Otherwise, Oracle reports a cycle detection error. You can circumvent this problem by manually ordering the rules and specifying SEQUENTIAL ORDER.
Ordered Rules
An ordered rule is one that has ORDER BY specified on the left side. It accesses cells in the order prescribed by ORDER BY and applies the right side computation. When you have ANY or symbolic references on the left side of a rule but without the ORDER BY clause, Oracle might return an error saying that the rule's results depend on the order in which cells are accessed and hence are non-deterministic. Consider the following SEQUENTIAL ORDER model:
SELECT t, s FROM sales, times WHERE sales.time_id = times.time_id GROUP BY calendar_year MODEL DIMENSION BY (calendar_year t) MEASURES (SUM(amount_sold) s) RULES SEQUENTIAL ORDER (s[ANY] = s[CV(t)-1]);
This query attempts to set, for all years t, sales s value for a year to the sales value of the prior year. Unfortunately, the result of this rule depends on the order in which the cells are accessed. If cells are accessed in the ascending order of year, the result would be that of column 3 in Table 23-1. If they are accessed in descending order, the result would be that of column 4.
| t | s | If ascending | If descending |
|---|---|---|---|
|
1998 |
1210000982 |
null |
null |
|
1999 |
1473757581 |
null |
1210000982 |
|
2000 |
2376222384 |
null |
1473757581 |
|
2001 |
1267107764 |
null |
2376222384 |
If you want the cells to be considered in descending order and get the result given in column 4, you should specify:
SELECT t, s FROM sales, times WHERE sales.time_id = times.time_id GROUP BY calendar_year MODEL DIMENSION BY (calendar_year t) MEASURES (SUM(amount_sold) s) RULES SEQUENTIAL ORDER (s[ANY] ORDER BY t DESC = s[CV(t)-1]);
In general, you can use any ORDER BY specification as long as it produces a unique order among cells that match the left side cell reference. Expressions in the ORDER BY of a rule can involve constants, measures and dimension keys and you can specify the ordering options [ASC | DESC] [NULLS FIRST | NULLS LAST] to get the order you want.
You can also specify ORDER BY for rules in an AUTOMATIC ORDER model to make Oracle consider cells in a particular order during rule evaluation. Rules are never considered self-cyclic if they have ORDER BY. For example, to make the following AUTOMATIC ORDER model with a self-cyclic formula acyclic:
MODEL DIMENSION BY (calendar_year t) MEASURES (SUM(amount_sold) s) RULES AUTOMATIC ORDER (s[ANY] = s[CV(t)-1])
You must provide the order in which cells need to be accessed for evaluation using ORDER BY. For example, you can say:
s[ANY] ORDER BY t = s[CV(t) - 1]
Then Oracle picks an ACYCLIC algorithm (which is certain to produce the result) for formula evaluation.
Analytic Functions
Analytic functions (also known as window functions) can be used in the right side of rules. The ability to use analytic functions adds expressive power and flexibility to the MODEL clause.The following example combines an analytic function with the MODEL clause. First, we create a view sales_rollup_time that uses the GROUPING_ID function to calculate an identifier for different levels of aggregations. We then use the view in a query that calculates the cumulative sum of sales at both the quarter and year levels.
CREATE OR REPLACE VIEW sales_rollup_time
AS
SELECT country_name country, calendar_year year, calendar_quarter_desc quarter,
GROUPING_ID(calendar_year, calendar_quarter_desc) gid, SUM(amount_sold) sale,
COUNT(amount_sold) cnt
FROM sales, times, customers, countries
WHERE sales.time_id = times.time_id AND sales.cust_id = customers.cust_id
AND customers.country_id = countries.country_id
GROUP BY country_name, calendar_year, ROLLUP(calendar_quarter_desc)
ORDER BY gid, country, year, quarter;
SELECT country, year, quarter, sale, csum
FROM sales_rollup_time
WHERE country IN ('United States of America', 'United Kingdom')
MODEL DIMENSION BY (country, year, quarter)
MEASURES (sale, gid, 0 csum)
(
csum[any, any, any] =
SUM(sale) OVER (PARTITION BY country, DECODE(gid,0,year,null)
ORDER BY year, quarter
ROWS UNBOUNDED PRECEDING)
)
ORDER BY country, gid, year, quarter;
COUNTRY YEAR QUARTER SALE CSUM
------------------------------ ---------- ------- ---------- ----------
United Kingdom 1998 1998-01 484733.96 484733.96
United Kingdom 1998 1998-02 386899.15 871633.11
United Kingdom 1998 1998-03 402296.49 1273929.6
United Kingdom 1998 1998-04 384747.94 1658677.54
United Kingdom 1999 1999-01 394911.91 394911.91
United Kingdom 1999 1999-02 331068.38 725980.29
United Kingdom 1999 1999-03 383982.61 1109962.9
United Kingdom 1999 1999-04 398147.59 1508110.49
United Kingdom 2000 2000-01 424771.96 424771.96
United Kingdom 2000 2000-02 351400.62 776172.58
United Kingdom 2000 2000-03 385137.68 1161310.26
United Kingdom 2000 2000-04 390912.8 1552223.06
United Kingdom 2001 2001-01 343468.77 343468.77
United Kingdom 2001 2001-02 415168.32 758637.09
United Kingdom 2001 2001-03 478237.29 1236874.38
United Kingdom 2001 2001-04 437877.47 1674751.85
United Kingdom 1998 1658677.54 1658677.54
United Kingdom 1999 1508110.49 3166788.03
United Kingdom 2000 1552223.06 4719011.09
United Kingdom 2001 1674751.85 6393762.94
... /*and similar output for the US*/
There are some specific restrictions when using analytic functions. See "Rules and Restrictions when Using SQL for Modeling" for more information.
Unique Dimensions Versus Unique Single References
The MODEL clause, in its default behavior, requires the PARTITION BY and DIMENSION BY keys to uniquely identify each row in the input to the model. Oracle verifies that and returns an error if the data is not unique. Uniqueness of the input rowset on the PARTITION BY and DIMENSION BY keys guarantees that any single cell reference accesses one and only one cell in the model. You can specify an optional UNIQUE DIMENSION keyword in the MODEL clause to make this behavior explicit. For example, the following query:
SELECT country, product, sales
FROM sales_view
WHERE country IN ('France', 'Poland')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (product) MEASURES (sales sales)
IGNORE NAV RULES UPSERT
(sales['Bounce'] = sales['All Products'] * 0.24);
This would return a uniqueness violation error as the rowset input to model is not unique on country and product because year is also needed:
ERROR at line 2:ORA-32638: Non unique addressing in MODEL dimensions
However, the following query does not return such an error:
SELECT country, product, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales sales)
RULES UPSERT
(sales['Bounce', 2003] = sales['All Products', 2002] * 0.24);
Input to the MODEL clause in this case is unique on country, product, and year as shown in:
COUNTRY PRODUCT YEAR SALES ------- ----------------------------- ---- -------- Italy 1.44MB External 3.5" Diskette 1998 3141.84 Italy 1.44MB External 3.5" Diskette 1999 3086.87 Italy 1.44MB External 3.5" Diskette 2000 3440.37 Italy 1.44MB External 3.5" Diskette 2001 855.23 ...
If you want to relax this uniqueness checking, you can specify UNIQUE SINGLE REFERENCE keyword. This can save processing time. In this case, the MODEL clause checks the uniqueness of only the single cell references appearing on the right side of rules. So the query that returned the uniqueness violation error would be successful if you specify UNIQUE SINGLE REFERENCE instead of UNIQUE DIMENSION.
Another difference between UNIQUE DIMENSION and UNIQUE SINGLE REFERENCE semantics is the number of cells that can be updated by a rule with a single cell reference on left side. In the case of UNIQUE DIMENSION, such a rule can update at most one row as only one cell would match the single cell reference on the left side. This is because the input rowset would be unique on PARTITION BY and DIMENSION BY keys. With UNIQUE SINGLE REFERENCE, all cells that match the left side single cell reference would be updated by the rule.
Rules and Restrictions when Using SQL for Modeling
The following general rules and restrictions apply when using the MODEL clause:
-
The only columns that can be updated are the columns specified in the
MEASURESsubclause of the main SQL model. Measures of reference models cannot be updated. -
The
MODELclause is evaluated after all clauses in the query block exceptSELECTDISTINCT, andORDERBYclause are evaluated. These clauses and expressions in theSELECTlist are evaluated after theMODELclause. -
If your query has a
MODELclause, then the query'sSELECTandORDERBYlists cannot contain aggregates or analytic functions. If needed, these can be specified inPARTITIONBY,DIMENSIONBY, andMEASURESlists and need to be aliased. Aliases can then be used in theSELECTorORDERBYclauses. In the following example, the analytic functionRANKis specified and aliased in theMEASURESlist of theMODELclause, and its alias is used in theSELECTlist so that the outer query can order resulting rows based on their ranks.SELECT country, product, year, s, RNK FROM (SELECT country, product, year, s, rnk FROM sales_view MODEL PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales s, year y, RANK() OVER (ORDER BY sales) rnk) RULES UPSERT (s['Bounce Increase 90-99', 2001] = REGR_SLOPE(s, y) ['Bounce', year BETWEEN 1990 AND 2000], s['Bounce', 2001] = s['Bounce', 2000] * (1+s['Bounce increase 90-99', 2001]))) WHERE product <> 'Bounce Increase 90-99' ORDER BY country, year, rnk, product; -
When there is a multi-cell reference on the right hand side of a rule, you need to apply a function to aggregate the measure values of multiple cells referenced into a single value. You can use any kind of aggregate function for this purpose: regular, analytic aggregate (inverse percentile, hypothetical rank and distribution), or user-defined aggregate.
-
Only rules with positional single cell references on the left side have
UPSERTsemantics. All other rules haveUPDATEsemantics, even when you specify theUPSERToption for them. -
Negative increments are not allowed in
FORloops. Also, no emptyFORloops are allowed.FOR d FROM 2005 TO 2001 INCREMENT -1is illegal. You should useFOR d FROM 2005 TO 2001 DECREMENT 1instead.FOR d FROM 2005 TO 2001 INCREMENT 1is illegal as it designates an empty loop. -
You cannot use nested query expressions (subqueries) in rules except in the
FORconstruct. For example, it would be illegal to issue the following:SELECT * FROM sales_view WHERE country = 'Poland' MODEL DIMENSION BY (product, year) MEASURES (sales sales) RULES UPSERT (sales['Bounce', 2003] = sales['Bounce', 2002] + (SELECT SUM(sales) FROM sales_view));
This is because the rule has a subquery on its right side. Instead, you can rewrite the preceding query in the following legal way:
SELECT * FROM sales_view WHERE country = 'Poland' MODEL DIMENSION BY (product, year) MEASURES (sales sales, (SELECT SUM(sales) FROM sales_view) AS grand_total) RULES UPSERT (sales['Bounce', 2003] =sales['Bounce', 2002] + grand_total['Bounce', 2002]);
-
You can also use subqueries in the
FORconstruct specified on the left side of a rule. However, they:-
Cannot be correlated
-
Must return fewer than 10,000 rows
-
Cannot be a query defined in the
WITHclause -
Will make the cursor unsharable
-
Nested cell references have the following restrictions:
-
Nested cell references must be single cell references. Aggregates on nested cell references are not supported. So, it would be illegal to say
s['Bounce', MAX(best_year)['Bounce', ANY]]. -
Only one level of nesting is supported for nested cell references on the main model. So, for example,
s['Bounce', best_year['Bounce', 2001]]is legal, buts['Bounce', best_year['Bounce', best_year['Bounce', 2001]]]is not. -
Nested cell references appearing on the left side of rules in an
AUTOMATICORDERmodel should not be updated in any rule of the model. This restriction ensures that the rule dependency relationships do not arbitrarily change (and hence cause non-deterministic results) due to updates to reference measures.There is no such restriction on nested cell references in a
SEQUENTIALORDERmodel. Also, this restriction is not applicable on nested references appearing on the right side of rules in bothSEQUENTIALorAUTOMATICORDERmodels.
Reference models have the following restrictions:
-
The query defining the reference model cannot be correlated to any outer query. It can, however, be a query with subqueries, views, and so on.
-
Reference models cannot have a
PARTITIONBYclause. -
Reference models cannot be updated.
Window functions have the following restrictions:
-
The expressions in the
OVERclause can be expressions of constants, measures, keys fromPARTITIONBYandDIMENSIONBYof theMODELclause, and single cell expressions. Aggregates are not permitted inside theOVERclause. Therefore, the following is okay:rnk[ANY, ANY, ANY] = RANK() (PARTITION BY prod, country ORDER BY sale)
While the following is not:
rnk[ANY, ANY, ANY] = RANK() (PARTITION BY prod, country ORDER BY SUM(sale))
-
Rules with window functions on their right side cannot have an
ORDERBYclause on their left side. -
Window functions and aggregate functions cannot both be on the right side of a rule.
-
Window functions can only be used on the right side of an
UPDATErule. -
If a rule has a
FORloop on its left side, a window function cannot be used on the right side of the rule.
Performance Considerations with SQL Modeling
The following sections describe topics that affect performance when using the MODEL clause:
Parallel Execution
MODEL clause computation is scalable in terms of the number of processors you have. Scalability is achieved by performing the MODEL computation in parallel across the partitions defined by the PARTITION BY clause. Data is distributed among processing elements (also called parallel query slaves) based on the PARTITION BY key values such that all rows with the same values for the PARTITION BY keys will go to the same slave. Note that the internal processing of partitions will not create a one-to-one match of logical and internally processed partitions. This way, each slave can finish MODEL clause computation independent of other slaves. The data partitioning can be hash based or range based. Consider the following MODEL clause:
MODEL PARTITION BY (country) DIMENSION BY (product, time) MEASURES (sales) RULES UPDATE (sales['Bounce', 2002] = 1.2 * sales['Bounce', 2001], sales['Car', 2002] = 0.8 * sales['Car', 2001])
Here input data will be partitioned among slaves based on the PARTITION BY key country and this partitioning can be hash or range based. Each slave will evaluate the rules on the data it receives.
Parallelism of the model computation is governed or limited by the way you specify the MODEL clause. If your MODEL clause has no PARTITION BY keys, then the computation cannot be parallelized (with exceptions mentioned in the following). If PARTITION BY keys have very low cardinality, then the degree of parallelism will be limited. In such cases, Oracle identifies the DIMENSION BY keys that can used for partitioning. For example, consider a MODEL clause equivalent to the preceding one, but without PARTITION BY keys as in the following:
MODEL DIMENSION BY (country, product, time) MEASURES (sales) RULES UPDATE (sales[ANY, 'Bounce', 2002] = 1.2 * sales[CV(country), 'Bounce', 2001], sales[ANY, 'Car', 2002] = 0.8 * sales[CV(country), 'Car', 2001])
In this case, Oracle Database identifies that it can use the DIMENSION BY key country for partitioning and uses region as the basis of internal partitioning. It partitions the data among slaves on country and thus effects parallel execution.
Aggregate Computation
The MODEL clause processes aggregates in two different ways: first, the regular fashion in which data in the partition is scanned and aggregated and second, an efficient window style aggregation. The first type as illustrated in the following introduces a new dimension member ALL_2002_products and computes its value to be the sum of year 2002 sales for all products:
MODEL PARTITION BY (country) DIMENSION BY (product, time) MEASURES (sale sales) RULES UPSERT (sales['ALL_2002_products', 2002] = SUM(sales)[ANY, 2002])
To evaluate the aggregate sum in this case, each partition will be scanned to find the cells for 2002 for all products and they will be aggregated. If the left side of the rule were to reference multiple cells, then Oracle will have to compute the right side aggregate by scanning the partition for each cell referenced on the left. For example, consider the following example:
MODEL PARTITION BY (country) DIMENSION BY (product, time) MEASURES (sale sales, 0 avg_exclusive) RULES UPDATE (avg_exclusive[ANY, 2002] = AVG(sales)[product <> CV(product), CV(time)])
This rule calculates a measure called avg_exclusive for every product in 2002. The measure avg_exclusive is defined as the average sales of all products excluding the current product. In this case, Oracle scans the data in a partition for every product in 2002 to calculate the aggregate, and this may be expensive.
Oracle Database optimizes the evaluation of such aggregates in some scenarios with window-style computation as used in analytic functions. These scenarios involve rules with multi-cell references on their left side and computing window computations such as moving averages, cumulative sums and so on. Consider the following example:
MODEL PARTITION BY (country) DIMENSION BY (product, time)
MEASURES (sale sales, 0 mavg)
RULES UPDATE
(mavg[product IN ('Bounce', 'Y Box', 'Mouse Pad'), ANY] =
AVG(sales)[CV(product), time BETWEEN CV(time)
AND CV(time) - 2])
It computes the moving average of sales for products Bounce, Y Box, and Mouse Pad over a three year period. It would be very inefficient to evaluate the aggregate by scanning the partition for every cell referenced on the left side. Oracle identifies the computation as being in window-style and evaluates it efficiently. It sorts the input on product, time and then scans the data once to compute the moving average. You can view this rule as an analytic function being applied on the sales data for products Bounce, Y Box, and Mouse Pad:
AVG(sales) OVER (PARTITION BY product ORDER BY time RANGE BETWEEN 2 PRECEDING AND CURRENT ROW)
This computation style is called WINDOW (IN MODEL) SORT. This style of aggregation is applicable when the rule has a multi-cell reference on its left side with no ORDER BY, has a simple aggregate (SUM, COUNT, MIN, MAX, STDEV, and VAR) on its right side, only one dimension on the right side has a boolean predicate (<, <=, >, >=, BETWEEN), and all other dimensions on the right are qualified with CV.
Using EXPLAIN PLAN to Understand Model Queries
Oracle's explain plan facility is fully aware of models. You will see a line in your query's main explain plan output showing the model and the algorithm used. Reference models are tagged with the keyword REFERENCE in the plan output. Also, Oracle annotates the plan with WINDOW (IN MODEL) SORT if any of the rules qualify for window-style aggregate computation.
By examining an explain plan, you can find out the algorithm chosen to evaluate your model. If your model has SEQUENTIAL ORDER semantics, then ORDERED is displayed. For AUTOMATIC ORDER models, Oracle displays ACYCLIC or CYCLIC based on whether it chooses ACYCLIC or CYCLIC algorithm for evaluation. In addition, the plan output will have an annotation FAST in case of ORDERED and ACYCLIC algorithms if all left side cell references are single cell references and aggregates, if any, on the right side of rules are simple arithmetic non-distinct aggregates like SUM, COUNT, AVG, and so on. Rule evaluation in this case would be highly efficient and hence the annotation FAST. Thus, the output you will see in the explain plan would be MODEL {ORDERED [FAST] | ACYCLIC [FAST] | CYCLIC}.
Using ORDERED FAST: Example
This model has only single cell references on the left side of rules and the aggregate AVG on the right side of first rule is a simple non-distinct aggregate:
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT
(sales['Bounce', 2003] = AVG(sales)[ANY, 2002] * 1.24,
sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25);
Using ORDERED: Example
Because the left side of the second rule is a multi-cell reference, the FAST method will not be chosen in the following:
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT
(sales['Bounce', 2003] = AVG(sales)[ANY, 2002] * 1.24,
sales[prod <> 'Bounce', 2003] = sales['Bounce', 2003] * 0.25);
Using ACYCLIC FAST: Example
Rules in this model are not cyclic and the explain plan will show ACYCLIC. The FAST method is chosen in this case as well.
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT AUTOMATIC ORDER
(sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25,
sales['Bounce', 2003] = sales['Bounce', 2002] / SUM(sales)[ANY, 2002] * 2 *
sales['All Products', 2003],
sales['All Products', 2003] = 200000);
Using ACYCLIC: Example
Rules in this model are not cyclic. The PERCENTILE_DISC aggregate that gives the median sales for year 2002, in the second rule is not a simple aggregate function. Therefore, Oracle will not choose the FAST method, and the explain plan will just show ACYCLIC.
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
RULES UPSERT AUTOMATIC ORDER
(sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25,
sales['Bounce',2003] = PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY
sales)[ANY,2002] / SUM(sales)[ANY, 2002] * 2 * sales['All Products', 2003],
sales['All Products', 2003] = 200000);
Using CYCLIC: Example
Oracle chooses CYCLIC algorithm for this model as there is a cycle among second and third rules.
EXPLAIN PLAN FOR
SELECT country, prod, year, sales
FROM sales_view
WHERE country IN ('Italy', 'Japan')
MODEL UNIQUE DIMENSION
PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales)
IGNORE NAV RULES UPSERT AUTOMATIC ORDER
(sales['All Products', 2003] = 200000,
sales['Y Box', 2003] = sales['Bounce', 2003] * 0.25,
sales['Bounce', 2003] = sales['Y Box', 2003] +
(sales['Bounce', 2002] / SUM(sales)[ANY, 2002] * 2 *
sales['All Products', 2003]));
Examples of SQL Modeling
The examples in this section assume that in addition to sales_view, you have the following view defined. It finds monthly totals of sales and quantities by product and country.
CREATE VIEW sales_view2 AS
SELECT country_name country, prod_name product, calendar_year year,
calendar_month_name month, SUM(amount_sold) sale, COUNT(amount_sold) cnt
FROM sales, times, customers, countries, products
WHERE sales.time_id = times.time_id AND
sales.prod_id = products.prod_id AND
sales.cust_id = customers.cust_id AND
customers.country_id = countries.country_id
GROUP BY country_name, prod_name, calendar_year, calendar_month_name;
- Example 1 Calculating Sales Differences
-
Show the sales for Italy and Spain and the difference between the two for each product. The difference should be placed in a new row with
country = 'Diff Italy-Spain'.SELECT product, country, sales FROM sales_view WHERE country IN ('Italy', 'Spain') GROUP BY product, country MODEL PARTITION BY (product) DIMENSION BY (country) MEASURES (SUM(sales) AS sales) RULES UPSERT (sales['DIFF ITALY-SPAIN'] = sales['Italy'] - sales['Spain']); - Example 2 Calculating Percentage Change
-
If sales for each product in each country grew (or declined) at the same monthly rate from November 2000 to December 2000 as they did from October 2000 to November 2000, what would the fourth quarter's sales be for the whole company and for each country?
SELECT country, SUM(sales) FROM (SELECT product, country, month, sales FROM sales_view2 WHERE year=2000 AND month IN ('October','November') MODEL PARTITION BY (product, country) DIMENSION BY (month) MEASURES (sale sales) RULES (sales['December']=(sales['November'] /sales['October']) *sales['November'])) GROUP BY GROUPING SETS ((),(country)); - Example 3 Calculating Net Present Value
-
You want to calculate the net present value (NPV) of a series of periodic cash flows. Your scenario involves two projects, each of which starts with an initial investment at time 0, represented as a negative cash flow. The initial investment is followed by three years of positive cash flow. First, create a table (
cash_flow) and populate it with some data, as in the following statements:CREATE TABLE cash_flow (year DATE, i INTEGER, prod VARCHAR2(3), amount NUMBER); INSERT INTO cash_flow VALUES (TO_DATE('1999', 'YYYY'), 0, 'vcr', -100.00); INSERT INTO cash_flow VALUES (TO_DATE('2000', 'YYYY'), 1, 'vcr', 12.00); INSERT INTO cash_flow VALUES (TO_DATE('2001', 'YYYY'), 2, 'vcr', 10.00); INSERT INTO cash_flow VALUES (TO_DATE('2002', 'YYYY'), 3, 'vcr', 20.00); INSERT INTO cash_flow VALUES (TO_DATE('1999', 'YYYY'), 0, 'dvd', -200.00); INSERT INTO cash_flow VALUES (TO_DATE('2000', 'YYYY'), 1, 'dvd', 22.00); INSERT INTO cash_flow VALUES (TO_DATE('2001', 'YYYY'), 2, 'dvd', 12.00); INSERT INTO cash_flow VALUES (TO_DATE('2002', 'YYYY'), 3, 'dvd', 14.00);To calculate the NPV using a discount rate of 0.14, issue the following statement:
SELECT year, i, prod, amount, npv FROM cash_flow MODEL PARTITION BY (prod) DIMENSION BY (i) MEASURES (amount, 0 npv, year) RULES (npv[0] = amount[0], npv[i !=0] ORDER BY i = amount[CV()]/ POWER(1.14,CV(i)) + npv[CV(i)-1]); YEAR I PRO AMOUNT NPV --------- ---------- --- ---------- ---------- 01-AUG-99 0 dvd -200 -200 01-AUG-00 1 dvd 22 -180.70175 01-AUG-01 2 dvd 12 -171.46814 01-AUG-02 3 dvd 14 -162.01854 01-AUG-99 0 vcr -100 -100 01-AUG-00 1 vcr 12 -89.473684 01-AUG-01 2 vcr 10 -81.779009 01-AUG-02 3 vcr 20 -68.279579 - Example 4 Calculating Using Simultaneous Equations
-
You want your interest expenses to equal 30% of your net income (net=pay minus tax minus interest). Interest is tax deductible from gross, and taxes are 38% of salary and 28% capital gains. You have salary of $100,000 and capital gains of $15,000. Net income, taxes, and interest expenses are unknown. Observe that this is a simultaneous equation (net depends on interest, which depends on net), thus the
ITERATEclause is included.First, create a table called
ledger:CREATE TABLE ledger (account VARCHAR2(20), balance NUMBER(10,2) );
Then, insert the following five rows:
INSERT INTO ledger VALUES ('Salary', 100000); INSERT INTO ledger VALUES ('Capital_gains', 15000); INSERT INTO ledger VALUES ('Net', 0); INSERT INTO ledger VALUES ('Tax', 0); INSERT INTO ledger VALUES ('Interest', 0);Next, issue the following statement:
SELECT s, account FROM ledger MODEL DIMENSION BY (account) MEASURES (balance s) RULES ITERATE (100) (s['Net']=s['Salary']-s['Interest']-s['Tax'], s['Tax']=(s['Salary']-s['Interest'])*0.38 + s['Capital_gains']*0.28, s['Interest']=s['Net']*0.30);
The output (with numbers rounded) is:
S ACCOUNT ---------- -------------------- 100000 Salary 15000 Capital_gains 48735.2445 Net 36644.1821 Tax 14620.5734 Interest - Example 5 Calculating Using Regression
-
The sales of Bounce in 2001 will increase in comparison to 2000 as they did in the last three years (between 1998 and 2000). To calculate the increase, use the regression function
REGR_SLOPEas follows. Because we are calculating the next period's value, it is sufficient to add the slope to the 2000 value.SELECT * FROM (SELECT country, product, year, projected_sale, sales FROM sales_view WHERE country IN ('Italy', 'Japan') AND product IN ('Bounce') MODEL PARTITION BY (country) DIMENSION BY (product, year) MEASURES (sales sales, year y, CAST(NULL AS NUMBER) projected_sale) IGNORE NAV RULES UPSERT (projected_sale[FOR product IN ('Bounce'), 2001] = sales[CV(), 2000] + REGR_SLOPE(sales, y)[CV(), year BETWEEN 1998 AND 2000])) ORDER BY country, product, year;The output is as follows:
COUNTRY PRODUCT YEAR PROJECTED_SALE SALES ------- ------- ---- -------------- ------- Italy Bounce 1999 2474.78 Italy Bounce 2000 4333.69 Italy Bounce 2001 6192.6 4846.3 Japan Bounce 1999 2961.3 Japan Bounce 2000 5133.53 Japan Bounce 2001 7305.76 6303.6
- Example 6 Calculating Mortgage Amortization
-
This example creates mortgage amortization tables for any number of customers, using information about mortgage loans selected from a table of mortgage facts. First, create two tables and insert needed data:
-
mortgage_factsHolds information about individual customer loans, including the name of the customer, the fact about the loan that is stored in that row, and the value of that fact. The facts stored for this example are loan (
Loan), annual interest rate (Annual_Interest), and number of payments (Payments) for the loan. Also, the values for two customers, Smith and Jones, are inserted.CREATE TABLE mortgage_facts (customer VARCHAR2(20), fact VARCHAR2(20), amount NUMBER(10,2)); INSERT INTO mortgage_facts VALUES ('Smith', 'Loan', 100000); INSERT INTO mortgage_facts VALUES ('Smith', 'Annual_Interest', 12); INSERT INTO mortgage_facts VALUES ('Smith', 'Payments', 360); INSERT INTO mortgage_facts VALUES ('Smith', 'Payment', 0); INSERT INTO mortgage_facts VALUES ('Jones', 'Loan', 200000); INSERT INTO mortgage_facts VALUES ('Jones', 'Annual_Interest', 12); INSERT INTO mortgage_facts VALUES ('Jones', 'Payments', 180); INSERT INTO mortgage_facts VALUES ('Jones', 'Payment', 0); -
mortgageHolds output information for the calculations. The columns are customer, payment number (
pmt_num), principal applied in that payment (principalp), interest applied in that payment (interestp), and remaining loan balance (mort_balance). In order to upsert new cells into a partition, you need to have at least one row pre-existing per partition. Therefore, we seed the mortgage table with the values for the two customers before they have made any payments. This seed information could be easily generated using a SQLINSERTstatement based on themortgage_factstable.
CREATE TABLE mortgage_facts (customer VARCHAR2(20), fact VARCHAR2(20), amount NUMBER(10,2)); INSERT INTO mortgage_facts VALUES ('Smith', 'Loan', 100000); INSERT INTO mortgage_facts VALUES ('Smith', 'Annual_Interest', 12); INSERT INTO mortgage_facts VALUES ('Smith', 'Payments', 360); INSERT INTO mortgage_facts VALUES ('Smith', 'Payment', 0); INSERT INTO mortgage_facts VALUES ('Jones', 'Loan', 200000); INSERT INTO mortgage_facts VALUES ('Jones', 'Annual_Interest', 12); INSERT INTO mortgage_facts VALUES ('Jones', 'Payments', 180); INSERT INTO mortgage_facts VALUES ('Jones', 'Payment', 0); CREATE TABLE mortgage (customer VARCHAR2(20), pmt_num NUMBER(4), principalp NUMBER(10,2), interestp NUMBER(10,2), mort_balance NUMBER(10,2)); INSERT INTO mortgage VALUES ('Jones',0, 0, 0, 200000); INSERT INTO mortgage VALUES ('Smith',0, 0, 0, 100000);The following SQL statement is complex, so individual lines have been annotated as needed. These lines are explained in more detail later.
SELECT c, p, m, pp, ip FROM MORTGAGE MODEL --See 1 REFERENCE R ON (SELECT customer, fact, amt --See 2 FROM mortgage_facts MODEL DIMENSION BY (customer, fact) MEASURES (amount amt) --See 3 RULES (amt[any, 'PaymentAmt']= (amt[CV(),'Loan']* Power(1+ (amt[CV(),'Annual_Interest']/100/12), amt[CV(),'Payments']) * (amt[CV(),'Annual_Interest']/100/12)) / (Power(1+(amt[CV(),'Annual_Interest']/100/12), amt[CV(),'Payments']) - 1) ) ) DIMENSION BY (customer cust, fact) measures (amt) --See 4 MAIN amortization PARTITION BY (customer c) --See 5 DIMENSION BY (0 p) --See 6 MEASURES (principalp pp, interestp ip, mort_balance m, customer mc) --See 7 RULES ITERATE(1000) UNTIL (ITERATION_NUMBER+1 = r.amt[mc[0],'Payments']) --See 8 (ip[ITERATION_NUMBER+1] = m[CV()-1] * r.amt[mc[0], 'Annual_Interest']/1200, --See 9 pp[ITERATION_NUMBER+1] = r.amt[mc[0], 'PaymentAmt'] - ip[CV()], --See 10 m[ITERATION_NUMBER+1] = m[CV()-1] - pp[CV()] --See 11 ) ORDER BY c, p;The following numbers refer to the numbers listed in the example:
1: This is the start of the main model definition.
2 through 4: These lines mark the start and end of the reference model labeled
R. This model defines aSELECTstatement that calculates the monthly payment amount for each customer's loan. TheSELECTstatement uses its ownMODELclause starting at the line labeled 3 with a single rule that defines theamtvalue based on information from themortgage_factstable. The measure returned by reference modelRisamt, dimensioned by customer namecustand fact valuefactas defined in the line labeled 4.The reference model is computed once and the values are then used in the main model for computing other calculations. Reference model
Rwill return a row for each existing row ofmortgage_facts, and it will return the newly calculated rows for each customer where the fact type isPaymentand theamtis the monthly payment amount. If we wish to use a specific amount from theRoutput, we address it with the expressionr.amt[<customer_name>,<fact_name>].5: This is the continuation of the main model definition. We will partition the output by customer, aliased as
c.6: The main model is dimensioned with a constant value of 0, aliased as
p. This represents the payment number of a row.7: Four measures are defined:
principalp (pp)is the principal amount applied to the loan in the month,interestp (ip)is the interest paid that month,mort_balance (m)is the remaining mortgage value after the payment of the loan, andcustomer (mc)is used to support the partitioning.8: This begins the rules block. It will perform the rule calculations up to 1000 times. Because the calculations are performed once for each month for each customer, the maximum number of months that can be specified for a loan is 1000. Iteration is stopped when the
ITERATION_NUMBER+1equals the amount of payments derived from referenceR. Note that the value from referenceRis theamt(amount) measure defined in the reference clause. This reference value is addressed asr.amt[<customer_name>,<fact>]. The expression used in the iterate line,"r.amt[mc[0], 'Payments']"is resolved to be the amount from referenceR, where the customer name is the value resolved bymc[0]. Since each partition contains only one customer,mc[0]can have only one value. Thus"r.amt[mc[0], 'Payments']"yields the reference clause's value for the number of payments for the current customer. This means that the rules will be performed as many times as there are payments for that customer.9 through 11: The first two rules in this block use the same type of
r.amtreference that was explained in 8. The difference is that the ip rule defines the fact value asAnnual_Interest. Note that each rule refers to the value of one of the other measures. The expression used on the left side of each rule,"[ITERATION_NUMBER+1]"will create a new dimension value, so the measure will be upserted into the result set. Thus the result will include a monthly amortization row for all payments for each customer.The final line of the example sorts the results by customer and loan payment number.
-