10 Managing a Logical Standby Database
This chapter contains the following topics:
-
Controlling User Access to Tables in a Logical Standby Database
-
Views Related to Managing and Monitoring a Logical Standby Database
-
Managing Specific Workloads In the Context of a Logical Standby Database
-
Backup and Recovery in the Context of a Logical Standby Database
10.1 Overview of the SQL Apply Architecture
SQL Apply uses a collection of background processes to apply changes from the primary database to the logical standby database.
Figure 10-1 shows the flow of information and the role that each process performs.
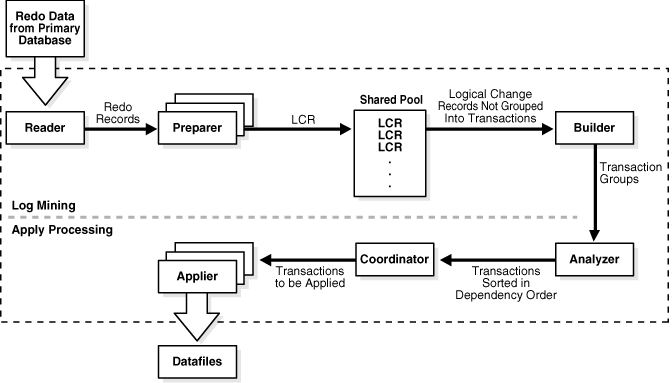
The different processes involved and their functions during log mining and apply processing are as follows:
During log mining:
-
The
READERprocess reads redo records from the archived redo log files or standby redo log files. -
The
PREPARERprocess converts block changes contained in redo records into logical change records (LCRs). MultiplePREPARERprocesses can be active for a given redo log file. The LCRs are staged in the system global area (SGA), known as the LCR cache. -
The
BUILDERprocess groups LCRs into transactions, and performs other tasks, such as memory management in the LCR cache, checkpointing related to SQL Apply restart and filtering out of uninteresting changes.
During apply processing:
-
The
ANALYZERprocess identifies dependencies between different transactions. -
The
COORDINATORprocess (LSP) assigns transactions to different appliers and coordinates among them to ensure that dependencies between transactions are honored. -
The
APPLIERprocesses applies transactions to the logical standby database under the supervision of the coordinator process.
You can query the V$LOGSTDBY_PROCESS view to examine the activity of the SQL Apply processes. Another view that provides information about current activity is the V$LOGSTDBY_STATS view that displays statistics, current state, and status information for the logical standby database during SQL Apply activities. These and other relevant views are discussed in more detail in Section 10.3, "Views Related to Managing and Monitoring a Logical Standby Database".
Note:
All SQL Apply processes (including the coordinator processlsp0) are true background processes. They are not regulated by resource manager. Therefore, creating resource groups at the logical standby database does not affect the SQL Apply processes.10.1.1 Various Considerations for SQL Apply
This section contains the following topics:
10.1.1.1 Transaction Size Considerations
SQL Apply categorizes transactions into two classes: small and large:
-
Small transactions—SQL Apply starts applying LCRs belonging to a small transaction once it has encountered the commit record for the transaction in the redo log files.
-
Large transactions—SQL Apply breaks large transactions into smaller pieces called transaction chunks, and starts applying the chunks before the commit record for the large transaction is seen in the redo log files. This is done to reduce memory pressure on the LCR cache and to reduce the overall failover time.
For example, without breaking into smaller pieces, a SQL*Loader load of ten million rows, each 100 bytes in size, would use more than 1 GB of memory in the LCR cache. If the memory allocated to the LCR cache was less than 1 GB, it would result in pageouts from the LCR cache.
Apart from the memory considerations, if SQL Apply did not start applying the changes related to the ten million row SQL*Loader load until it encountered the
COMMITrecord for the transaction, it could stall a role transition. A switchover or a failover that is initiated after the transaction commit cannot finish until SQL Apply has applied the transaction on the logical standby database.Despite the use of transaction chunks, SQL Apply performance may degrade when processing transactions that modify more than eight million rows. For transactions larger than 8 million rows, SQL Apply uses the temporary segment to stage some of the internal metadata required to process the transaction. You will need to allocate enough space in your temporary segment for SQL Apply to successfully process transactions larger than 8 million rows.
All transactions start out categorized as small transactions. Depending on the amount of memory available for the LCR cache and the amount of memory consumed by LCRs belonging to a transaction, SQL Apply determines when to recategorize a transaction as a large transaction.
10.1.1.2 Pageout Considerations
Pageouts occur in the context of SQL Apply when memory in the LCR cache is exhausted and space needs to be released for SQL Apply to make progress.
For example, assume the memory allocated to the LCR cache is 100 MB and SQL Apply encounters an INSERT transaction to a table with a LONG column of size 300 MB. In this case, the log-mining component will page out the first part of the LONG data to read the later part of the column modification. In a well-tuned logical standby database, pageout activities will occur occasionally and should not effect the overall throughput of the system.
See Also:
See Section 10.5, "Customizing a Logical Standby Database" for more information about how to identify problematic pageouts and perform corrective actions10.1.1.3 Restart Considerations
Modifications made to the logical standby database do not become persistent until the commit record of the transaction is mined from the redo log files and applied to the logical standby database. Thus, every time SQL Apply is stopped, whether as a result of a user directive or because of a system failure, SQL Apply must go back and mine the earliest uncommitted transaction again.
In cases where a transaction does little work but remains open for a long period of time, restarting SQL Apply from the start could be prohibitively costly because SQL Apply would have to mine a large number of archived redo log files again, just to read the redo data for a few uncommitted transactions. To mitigate this, SQL Apply periodically checkpoints old uncommitted data. The SCN at which the checkpoint is taken is reflected in the RESTART_SCN column of V$LOGSTDBY_PROGRESS view. Upon restarting, SQL Apply starts mining redo records that are generated at an SCN greater than value shown by the RESTART_SCN column. Archived redo log files that are not needed for restart are automatically deleted by SQL Apply.
Certain workloads, such as large DDL transactions, parallel DML statements (PDML), and direct-path loads, will prevent the RESTART_SCN from advancing for the duration of the workload.
10.1.1.4 DML Apply Considerations
SQL Apply has the following characteristics when applying DML transactions that affect the throughput and latency on the logical standby database:
-
Batch updates or deletes done on the primary database, where a single statement results in multiple rows being modified, are applied as individual row modifications on the logical standby database. Thus, it is imperative for each maintained table to have a unique index or a primary key. See Section 4.1.2, "Ensure Table Rows in the Primary Database Can Be Uniquely Identified" for more information.
-
Direct path inserts performed on the primary database are applied using a conventional
INSERTstatement on the logical standby database. -
Parallel DML (PDML) transactions are not executed in parallel on the logical standby database.
10.1.1.5 DDL Apply Considerations
SQL Apply has the following characteristics when applying DDL transactions that affect the throughput and latency on the logical standby database:
-
DDL transactions are applied serially on the logical standby database. Thus, DDL transactions applied concurrently on the primary database are applied one at a time on the logical standby database.
-
CREATE TABLE AS SELECT(CTAS) statements are executed such that the DML activities (that are part of the CTAS statement) are suppressed on the logical standby database. The rows inserted in the newly created table as part of the CTAS statement are mined from the redo log files and applied to the logical standby database usingINSERTstatements. -
SQL Apply reissues the DDL that was performed at the primary database, and ensures that DMLs that occur within the same transaction on the same object that is the target of the DDL operation are not replicated at the logical standby database. Thus, the following two cases will cause the primary and standby sites to diverge from each other:
-
The DDL contains a non-literal value that is derived from the state at the primary database. An example of such a DDL is:
ALTER TABLE hr.employees ADD (start_date date default sysdate);
Because SQL Apply will reissue the same DDL at the logical standby, the function
sysdate()will be reevaluated at the logical standby. Thus, the columnstart_datewill be created with a different default value than at the primary database. -
The DDL fires DML triggers defined on the target table. Since the triggered DMLs occur in the same transaction as the DDL, and operate on the table that is the target of the DDL, these triggered DMLs will not be replicated at the logical standby.
For example, assume you create a table as follows:
create table HR.TEMP_EMPLOYEES ( emp_id number primary key, first_name varchar2(64), last_name varchar2(64), modify_date timestamp);
Assume you then create a trigger on the table such that any time the table is updated the
modify_dateis updated to reflect the time of change:CREATE OR REPLACE TRIGGER TRG_TEST_MOD_DT BEFORE UPDATE ON HR.TEST_EMPLOYEES REFERENCING NEW AS NEW_ROW FOR EACH ROW BEGIN :NEW_ROW.MODIFY_DATE:= SYSTIMESTAMP; END; /
This table will be maintained correctly under the usual DML/DDL workload. However if you add a column with the default value to the table, the
ADD COLUMNDDL fires this update trigger and changes theMODIFY_DATEcolumn of all rows in the table to a new timestamp. These changes to theMODIFY_DATEcolumn are not replicated at the logical standby database. Subsequent DMLs to the table will stop SQL Apply because theMODIFY_DATEcolumn data recorded in the redo stream will not match the data that exists at the logical standby database.
-
10.1.1.6 Password Verification Functions
Password verification functions that check for the complexity of passwords must be created in the SYS schema. Because SQL Apply does not replicate objects created in the SYS schema, such verification functions will not be replicated to the logical standby database. You must create the password verification function manually at the logical standby database, and associate it with the appropriate profiles.
10.2 Controlling User Access to Tables in a Logical Standby Database
The SQL ALTER DATABASE GUARD statement controls user access to tables in a logical standby database. The database guard is set to ALL by default on a logical standby database.
The ALTER DATABASE GUARD statement allows the following keywords:
-
ALLSpecify ALL to prevent all users, other than SYS, from making changes to any data in the logical standby database.
-
STANDBYSpecify STANDBY to prevent all users, other than SYS, from making DML and DDL changes to any table or sequence being maintained through SQL Apply.
-
NONESpecify NONE if you want typical security for all data in the database.
For example, use the following statement to enable users to modify tables not maintained by SQL Apply:
SQL> ALTER DATABASE GUARD STANDBY;
Privileged users can temporarily turn the database guard off and on for the current session using the ALTER SESSION DISABLE GUARD and ALTER SESSION ENABLE GUARD statements, respectively. This statement replaces the DBMS_LOGSTDBY.GUARD_BYPASS PL/SQL procedure that performed the same function in Oracle9i. The ALTER SESSION [ENABLE|DISABLE] GUARD statement is useful when you want to temporarily disable the database guard to make changes to the database, as described in Section 10.5.4.
Note:
Be careful not to let the primary and logical standby databases diverge while the database guard is disabled.10.3 Views Related to Managing and Monitoring a Logical Standby Database
The following performance views monitor the behavior of SQL Apply maintaining a logical standby database. The following sections describe the key views that can be used to monitor a logical standby database:
See Also:
Oracle Database Reference for complete reference information about views10.3.1 DBA_LOGSTDBY_EVENTS View
The DBA_LOGSTDBY_EVENTS view records interesting events that occurred during the operation of SQL Apply. By default, the view records the most recent 10,000 events. However, you can change the number of recorded events by calling DBMS_LOGSTDBY.APPLY_SET() PL/SQL procedure. If SQL Apply should stop unexpectedly, the reason for the problem is also recorded in this view.
Note:
Errors that cause SQL Apply to stop are recorded in the events table These events are put into theALERT.LOG file as well, with the LOGSTDBY keyword included in the text. When querying the view, select the columns in order by EVENT_TIME_STAMP, COMMIT_SCN, and CURRENT_SCN to ensure the desired ordering of events.The view can be customized to contain other information, such as which DDL transactions were applied and which were skipped. For example:
SQL> ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YY HH24:MI:SS'; Session altered. SQL> COLUMN STATUS FORMAT A60 SQL> SELECT EVENT_TIME, STATUS, EVENT FROM DBA_LOGSTDBY_EVENTS - > ORDER BY EVENT_TIMESTAMP, COMMIT_SCN, CURRENT_SCN; EVENT_TIME STATUS ------------------------------------------------------------------------------ EVENT ------------------------------------------------------------------------------- 23-JUL-02 18:20:12 ORA-16111: log mining and apply setting up 23-JUL-02 18:25:12 ORA-16128: User initiated shut down successfully completed 23-JUL-02 18:27:12 ORA-16112: log mining and apply stopping 23-JUL-02 18:55:12 ORA-16128: User initiated shut down successfully completed 23-JUL-02 18:57:09 ORA-16111: log mining and apply setting up 23-JUL-02 20:21:47 ORA-16204: DDL successfully applied create table hr.test_emp (empno number, ename varchar2(64)) 23-JUL-02 20:22:55 ORA-16205: DDL skipped due to skip setting create database link link_to_boston connect to system identified by change_on_inst 7 rows selected.
This query shows that SQL Apply was started and stopped a few times. It also shows what DDL was applied and skipped.
10.3.2 DBA_LOGSTDBY_LOG View
The DBA_LOGSTDBY_LOG view provides dynamic information about archived logs being processed by SQL Apply.
For example:
SQL> COLUMN DICT_BEGIN FORMAT A10; SQL> SET NUMF 99999999; SQL> SELECT FILE_NAME, SEQUENCE# AS SEQ#, FIRST_CHANGE# AS F_SCN#, - > NEXT_CHANGE# AS N_SCN#, TIMESTAMP, - > DICT_BEGIN AS BEG, DICT_END AS END, - > THREAD# AS THR#, APPLIED FROM DBA_LOGSTDBY_LOG - > ORDER BY SEQUENCE#; FILE_NAME SEQ# F_SCN N_SCN TIMESTAM BEG END THR# APPLIED ------------------------- ---- ------- ------- -------- --- --- --- --------- /oracle/dbs/hq_nyc_2.log 2 101579 101588 11:02:58 NO NO 1 YES /oracle/dbs/hq_nyc_3.log 3 101588 142065 11:02:02 NO NO 1 YES /oracle/dbs/hq_nyc_4.log 4 142065 142307 11:02:10 NO NO 1 YES /oracle/dbs/hq_nyc_5.log 5 142307 142739 11:02:48 YES YES 1 YES /oracle/dbs/hq_nyc_6.log 6 142739 143973 12:02:10 NO NO 1 YES /oracle/dbs/hq_nyc_7.log 7 143973 144042 01:02:11 NO NO 1 YES /oracle/dbs/hq_nyc_8.log 8 144042 144051 01:02:01 NO NO 1 YES /oracle/dbs/hq_nyc_9.log 9 144051 144054 01:02:16 NO NO 1 YES /oracle/dbs/hq_nyc_10.log 10 144054 144057 01:02:21 NO NO 1 YES /oracle/dbs/hq_nyc_11.log 11 144057 144060 01:02:26 NO NO 1 CURRENT /oracle/dbs/hq_nyc_12.log 12 144060 144089 01:02:30 NO NO 1 CURRENT /oracle/dbs/hq_nyc_13.log 13 144089 144147 01:02:41 NO NO 1 NO
The YES entries in the BEG and END columns indicate that a LogMiner dictionary build starts at log file sequence number 5. The most recent archived redo log file is sequence number 13, and it was received at the logical standby database at 01:02:41.The APPLIED column indicates that SQL Apply has applied all redo before SCN 144057. Since transactions can span multiple archived log files, multiple archived log files may show the value CURRENT in the APPLIED column.
10.3.3 V$DATAGUARD_STATS View
This view provides information related to the failover characteristics of the logical standby database, including:
-
The time to failover (
apply finish time) -
How current is the committed data in the logical standby database (
apply lag) -
What the potential data loss will be in the event of a disaster (
transport lag).
For example:
SQL> COL NAME FORMAT A20 SQL> COL VALUE FORMAT A12 SQL> COL UNIT FORMAT A30 SQL> SELECT NAME, VALUE, UNIT FROM V$DATAGUARD_STATS; NAME VALUE UNIT -------------------- ------------ ------------------------------ apply finish time +00 00:00:00 day(2) to second(1) interval apply lag +00 00:00:00 day(2) to second(0) interval transport lag +00 00:00:00 day(2) to second(0) interval
This output is from a logical standby database that has received and applied all redo generated from the primary database.
10.3.4 V$LOGSTDBY_PROCESS View
This view provides information about the current state of the various processes involved with SQL Apply, including;
-
Identifying information (
sid|serial#|spid) -
SQL Apply process:
COORDINATOR,READER,BUILDER,PREPARER,ANALYZER, orAPPLIER(type) -
Status of the process's current activity (
status_code|status) -
Highest redo record processed by this process (
high_scn)
For example:
SQL> COLUMN SERIAL# FORMAT 9999 SQL> COLUMN SID FORMAT 9999 SQL> SELECT SID, SERIAL#, SPID, TYPE, HIGH_SCN FROM V$LOGSTDBY_PROCESS; SID SERIAL# SPID TYPE HIGH_SCN ----- ------- ----------- ---------------- ---------- 48 6 11074 COORDINATOR 7178242899 56 56 10858 READER 7178243497 46 1 10860 BUILDER 7178242901 45 1 10862 PREPARER 7178243295 37 1 10864 ANALYZER 7178242900 36 1 10866 APPLIER 7178239467 35 3 10868 APPLIER 7178239463 34 7 10870 APPLIER 7178239461 33 1 10872 APPLIER 7178239472 9 rows selected.
The HIGH_SCN column shows that the reader process is ahead of all other processes, and the PREPARER and BUILDER process ahead of the rest.
SQL> COLUMN STATUS FORMAT A40 SQL> SELECT TYPE, STATUS_CODE, STATUS FROM V$LOGSTDBY_PROCESS; TYPE STATUS_CODE STATUS ---------------- ----------- ----------------------------------------- COORDINATOR 16117 ORA-16117: processing READER 16127 ORA-16127: stalled waiting for additional transactions to be applied BUILDER 16116 ORA-16116: no work available PREPARER 16116 ORA-16117: processing ANALYZER 16120 ORA-16120: dependencies being computed for transaction at SCN 0x0001.abdb440a APPLIER 16124 ORA-16124: transaction 1 13 1427 is waiting on another transaction APPLIER 16121 ORA-16121: applying transaction with commit SCN 0x0001.abdb4390 APPLIER 16123 ORA-16123: transaction 1 23 1231 is waiting for commit approval APPLIER 16116 ORA-16116: no work available
The output shows a snapshot of SQL Apply running. On the mining side, the READER process is waiting for additional memory to become available before it can read more, the PREPARER process is processing redo records, and the BUILDER process has no work available. On the apply side, the COORDINATOR is assigning more transactions to APPLIER processes, the ANALYZER is computing dependencies at SCN 7178241034, one APPLIER has no work available, while two have outstanding dependencies that are not yet satisfied.
See Also:
Section 10.4.1, "Monitoring SQL Apply Progress" for example output10.3.5 V$LOGSTDBY_PROGRESS View
This view provides detailed information regarding progress made by SQL Apply, including:
-
SCN and time at which all transactions that have been committed on the primary database have been applied to the logical standby database (
applied_scn,applied_time) -
SCN and time at which SQL Apply would begin reading redo records (
restart_scn,restart_time) on restart -
SCN and time of the latest redo record received on the logical standby database (
latest_scn,latest_time) -
SCN and time of the latest record processed by the
BUILDERprocess (mining_scn,mining_time)
For example:
SQL> SELECT APPLIED_SCN, LATEST_SCN, MINING_SCN, RESTART_SCN - > FROM V$LOGSTDBY_PROGRESS; APPLIED_SCN LATEST_SCN MINING_SCN RESTART_SCN ----------- ----------- ---------- ----------- 7178240496 7178240507 7178240507 7178219805
According to the output:
-
SQL Apply has applied all transactions committed on or before SCN of 7178240496
-
The latest redo record received at the logical standby database was generated at SCN 7178240507
-
The mining component has processed all redo records generate on or before SCN 7178240507
-
If SQL Apply stops and restarts for any reason, it will start mining redo records generated on or after SCN 7178219805
SQL> ALTER SESSION SET NLS_DATE_FORMAT='yy-mm-dd hh24:mi:ss'; Session altered SQL> SELECT APPLIED_TIME, LATEST_TIME, MINING_TIME, RESTART_TIME - > FROM V$LOGSTDBY_PROGRESS; APPLIED_TIME LATEST_TIME MINING_TIME RESTART_TIME ----------------- ----------------- ----------------- ----------------- 05-05-12 10:38:21 05-05-12 10:41:53 05-05-12 10:41:21 05-05-12 10:09:30
According to the output:
-
SQL Apply has applied all transactions committed on or before the time 05-05-12 10:38:21 (
APPLIED_TIME) -
The last redo was generated at time 05-05-12 10:41:53 at the primary database (
LATEST_TIME) -
The mining engine has processed all redo records generated on or before 05-05-12 10:41:21 (
MINING_TIME) -
In the event of a restart, SQL Apply will start mining redo records generated after the time 05-05-12 10:09:30
See Also:
Section 10.4.1, "Monitoring SQL Apply Progress" for example output10.3.6 V$LOGSTDBY_STATE View
This view provides a synopsis of the current state of SQL Apply, including:
-
The DBID of the primary database (
primary_dbid). -
The LogMiner session ID allocated to SQL Apply (
session_id). -
Whether or not SQL Apply is applying in real time (
realtime_apply).
For example:
SQL> COLUMN REALTIME_APPLY FORMAT a15 SQL> COLUMN STATE FORMAT a16 SQL> SELECT * FROM V$LOGSTDBY_STATE; PRIMARY_DBID SESSION_ID REALTIME_APPLY STATE ------------ ---------- --------------- ---------------- 1562626987 1 Y APPLYING
The output shows that SQL Apply is running in the real-time apply mode and is currently applying redo data received from the primary database, the primary database's DBID is 1562626987 and the LogMiner session identifier associated the SQL Apply session is 1.
See Also:
Section 10.4.1, "Monitoring SQL Apply Progress" for example output10.3.7 V$LOGSTDBY_STATS View
The V$LOGSTDBY_STATS view displays statistics, current state, and status information related to SQL Apply. No rows are returned from this view when SQL Apply is not running. This view is only meaningful in the context of a logical standby database.
For example:
SQL> ALTER SESSION SET NLS_DATE_FORMAT='dd-mm-yyyy hh24:mi:ss'; Session altered SQL> SELECT SUBSTR(name, 1, 40) AS NAME, SUBSTR(value,1,32) AS VALUE FROM V$LOGSTDBY_STATS; NAME VALUE ---------------------------------------- -------------------------------- logminer session id 1 number of preparers 1 number of appliers 5 server processes in use 9 maximum SGA for LCR cache (MB) 30 maximum events recorded 10000 preserve commit order TRUE transaction consistency FULL record skipped errors Y record skipped DDLs Y record applied DDLs N record unsupported operations N realtime apply Y apply delay (minutes) 0 coordinator state APPLYING coordinator startup time 19-06-2007 09:55:47 coordinator uptime (seconds) 3593 txns received from logminer 56 txns assigned to apply 23 txns applied 22 txns discarded during restart 33 large txns waiting to be assigned 2 rolled back txns mined 4 DDL txns mined 40 CTAS txns mined 0 bytes of redo mined 60164040 bytes paged out 0 pageout time (seconds) 0 bytes checkpointed 4845 checkpoint time (seconds) 0 system idle time (seconds) 2921 standby redo logs mined 0 archived logs mined 5 gap fetched logs mined 0 standby redo log reuse detected 1 logfile open failures 0 current logfile wait (seconds) 0 total logfile wait (seconds) 2910 thread enable mined 0 thread disable mined 0 . 40 rows selected.
10.4 Monitoring a Logical Standby Database
This section contains the following topics:
10.4.1 Monitoring SQL Apply Progress
SQL Apply can be in any of six states of progress: initializing SQL Apply, waiting for dictionary logs, loading the LogMiner dictionary, applying (redo data), waiting for an archive gap to be resolved, and idle. Figure 10-2 shows the flow of these states.
Figure 10-2 Progress States During SQL Apply Processing
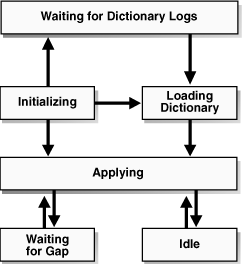
Description of "Figure 10-2 Progress States During SQL Apply Processing"
The following subsections describe each state in more detail.
When you start SQL Apply by issuing an ALTER DATABASE START LOGICAL STANDBY APPLY statement, it goes into the initializing state.
To determine the current state of SQL Apply, query the V$LOGSTDBY_STATE view. For example:
SQL> SELECT SESSION_ID, STATE FROM V$LOGSTDBY_STATE; SESSION_ID STATE ---------- ------------- 1 INITIALIZING
The SESSION_ID column identifies the persistent LogMiner session created by SQL Apply to mine the archived redo log files generated by the primary database.
The first time the SQL Apply is started, it needs to load the LogMiner dictionary captured in the redo log files. SQL Apply will stay in the WAITING FOR DICTIONARY LOGS state until it has received all redo data required to load the LogMiner dictionary.
This loading dictionary state can persist for a while. Loading the LogMiner dictionary on a large database can take a long time. Querying the V$LOGSTDBY_STATE view returns the following output when loading the dictionary:
SQL> SELECT SESSION_ID, STATE FROM V$LOGSTDBY_STATE; SESSION_ID STATE ---------- ------------------ 1 LOADING DICTIONARY
Only the COORDINATOR process and the mining processes are spawned until the LogMiner dictionary is fully loaded. Therefore, if you query the V$LOGSTDBY_PROCESS at this point, you will not see any of the APPLIER processes. For example:
SQL> SELECT SID, SERIAL#, SPID, TYPE FROM V$LOGSTDBY_PROCESS; SID SERIAL# SPID TYPE ------ --------- --------- --------------------- 47 3 11438 COORDINATOR 50 7 11334 READER 45 1 11336 BUILDER 44 2 11338 PREPARER 43 2 11340 PREPARER
You can get more detailed information about the progress in loading the dictionary by querying the V$LOGMNR_DICTIONARY_LOAD view. The dictionary load happens in three phases:
-
The relevant archived redo log files or standby redo logs files are mined to gather the redo changes relevant to load the LogMiner dictionary.
-
The changes are processed and loaded in staging tables inside the database.
-
The LogMiner dictionary tables are loaded by issuing a series of DDL statements.
For example:
SQL> SELECT PERCENT_DONE, COMMAND -
> FROM V$LOGMNR_DICTIONARY_LOAD -
> WHERE SESSION_ID = (SELECT SESSION_ID FROM V$LOGSTDBY_STATE);
PERCENT_DONE COMMAND
------------- -------------------------------
40 alter table SYSTEM.LOGMNR_CCOL$ exchange partition
P101 with table SYS.LOGMNRLT_101_CCOL$ excluding
indexes without validation
If the PERCENT_DONE or the COMMAND column does not change for a long time, query the V$SESSION_LONGOPS view to monitor the progress of the DDL transaction in question.
In this state, SQL Apply has successfully loaded the initial snapshot of the LogMiner dictionary, and is currently applying redo data to the logical standby database.
For detailed information about the SQL Apply progress, query the V$LOGSTDBY_PROGRESS view:
SQL> ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY HH24:MI:SS'; SQL> SELECT APPLIED_TIME, APPLIED_SCN, MINING_TIME, MINING_SCN - > FROM V$LOGSTDBY_PROGRESS; APPLIED_TIME APPLIED_SCN MINING_TIME MINING_SCN -------------------- ----------- -------------------- ----------- 10-JAN-2005 12:00:05 346791023 10-JAN-2005 12:10:05 3468810134
All committed transactions seen at or before APPLIED_SCN (or APPLIED_TIME) on the primary database have been applied to the logical standby database. The mining engine has processed all redo records generated at or before MINING_SCN (and MINING_TIME) on the primary database. At steady state, the value of MINING_SCN (and MINING_TIME) will always be ahead of APPLIED_SCN (and APPLIED_TIME).
This state occurs when SQL Apply has mined and applied all available redo records, and is waiting for a new log file (or a missing log file) to be archived by the RFS process.
SQL> SELECT STATUS FROM V$LOGSTDBY_PROCESS WHERE TYPE = 'READER'; STATUS ------------------------------------------------------------------------ ORA-16240: waiting for log file (thread# 1, sequence# 99)
SQL Apply enters this state once it has applied all redo generated by the primary database.
10.4.2 Automatic Deletion of Log Files
Foreign archived logs contain redo that was shipped from the primary database. There are two ways to store foreign archive logs:
-
In the fast recovery area
-
In a directory outside of the fast recovery area
Foreign archived logs stored in the fast recovery area are always managed by SQL Apply. After all redo records contained in the log have been applied at the logical standby database, they are retained for the time period specified by the DB_FLASHBACK_RETENTION_TARGET parameter (or for 1440 minutes if DB_FLASHBACK_RETENTION_TARGET is not specified). You cannot override automatic management of foreign archived logs that are stored in the fast recovery area.
Foreign archived logs that are not stored in fast recovery area are by default managed by SQL Apply. Under automatic management, foreign archived logs that are not stored in the fast recovery area are retained for the time period specified by the LOG_AUTO_DEL_RETENTION_TARGET parameter once all redo records contained in the log have been applied at the logical standby database. You can override automatic management of foreign archived logs not stored in fast recovery area by executing the following PL/SQL procedure:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('LOG_AUTO_DELETE', 'FALSE');
Note:
Use theDBMS_LOGTSDBY.APPLY_SET procedure to set this parameter. If you do not specify LOG_AUTO_DEL_RETENTION_TARGET explicitly, it defaults to DB_FLASHBACK_RETENTION_TARGET set in the logical standby database, or to 1440 minutes in case DB_FLASHBACK_RETENTION_TARGET is not set.If you are overriding the default automatic log deletion capability, periodically perform the following steps to identify and delete archived redo log files that are no longer needed by SQL Apply:
-
To purge the logical standby session of metadata that is no longer needed, enter the following PL/SQL statement:
SQL> EXECUTE DBMS_LOGSTDBY.PURGE_SESSION;
This statement also updates the
DBA_LOGMNR_PURGED_LOGview that displays the archived redo log files that are no longer needed. -
Query the
DBA_LOGMNR_PURGED_LOGview to list the archived redo log files that can be removed:SQL> SELECT * FROM DBA_LOGMNR_PURGED_LOG; FILE_NAME ------------------------------------ /boston/arc_dest/arc_1_40_509538672.log /boston/arc_dest/arc_1_41_509538672.log /boston/arc_dest/arc_1_42_509538672.log /boston/arc_dest/arc_1_43_509538672.log /boston/arc_dest/arc_1_44_509538672.log /boston/arc_dest/arc_1_45_509538672.log /boston/arc_dest/arc_1_46_509538672.log /boston/arc_dest/arc_1_47_509538672.log
-
Use an operating system-specific command to delete the archived redo log files listed by the query.
10.5 Customizing a Logical Standby Database
This section contains the following topics:
-
Customizing Logging of Events in the DBA_LOGSTDBY_EVENTS View
-
Using DBMS_LOGSTDBY.SKIP to Prevent Changes to Specific Schema Objects
10.5.1 Customizing Logging of Events in the DBA_LOGSTDBY_EVENTS View
The DBA_LOGSTDBY_EVENTS view can be thought of as a circular log containing the most recent interesting events that occurred in the context of SQL Apply. By default the last 10,000 events are remembered in the event view. You can change the number of events logged by invoking the DBMS_LOGSTDBY.APPLY_SET procedure. For example, to ensure that the last 100,000 events are recorded, you can issue the following statement:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET ('MAX_EVENTS_RECORDED', '100000');
Errors that cause SQL Apply to stop are always recorded in the DBA_LOGSTDBY_EVENTS view (unless there is insufficient space in the SYSTEM tablespace). These events are always put into the alert file as well, with the keyword LOGSTDBY included in the text. When querying the view, select the columns in order by EVENT_TIME, COMMIT_SCN, and CURRENT_SCN. This ordering ensures a shutdown failure appears last in the view.
The following examples show DBMS_LOGSTDBY subprograms that specify events to be recorded in the view.
- Example 1 Determining If DDL Statements Have Been Applied
-
For example, to record applied DDL transactions to the
DBA_LOGSTDBY_EVENTSview, issue the following statement:SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET ('RECORD_APPLIED_DDL', 'TRUE'); - Example 2 Checking the DBA_LOGSTDBY_EVENTS View for Unsupported Operations
-
To capture information about transactions running on the primary database that will not be supported by a logical standby database, issue the following statements:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;SQL> EXEC DBMS_LOGSTDBY.APPLY_SET('RECORD_UNSUPPORTED_OPERATIONS', 'TRUE');SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;Then, check the
DBA_LOGSTDBY_EVENTSview for any unsupported operations. Usually, an operation on an unsupported table is silently ignored by SQL Apply. However, during rolling upgrade (while the standby database is at a higher version and mining redo generated by a lower versioned primary database), if you performed an unsupported operation on the primary database, the logical standby database may not be the one to which you want to perform a switchover. Data Guard will log at least one unsupported operation per table in theDBA_LOGSTDBY_EVENTSview. Chapter 12, "Using SQL Apply to Upgrade the Oracle Database" provides detailed information about rolling upgrades.
10.5.2 Using DBMS_LOGSTDBY.SKIP to Prevent Changes to Specific Schema Objects
By default, all supported tables in the primary database are replicated in the logical standby database. You can change the default behavior by specifying rules to skip applying modifications to specific tables. For example, to omit changes to the HR.EMPLOYEES table, you can specify rules to prevent application of DML and DDL changes to the specific table. For example:
-
Stop SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
-
Register the
SKIPrules:SQL> EXECUTE DBMS_LOGSTDBY.SKIP (stmt => 'DML', schema_name => 'HR', - > object_name => 'EMPLOYEES'); SQL> EXECUTE DBMS_LOGSTDBY.SKIP (stmt => 'SCHEMA_DDL', schema_name => 'HR', - > object_name => 'EMPLOYEES');
-
Start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
10.5.3 Setting up a Skip Handler for a DDL Statement
You can create a procedure to intercept certain DDL statements and replace the original DDL statement with a different one. For example, if the file system organization in the logical standby database is different than that in the primary database, you can write a DBMS_LOGSTDBY.SKIP procedure to transparently handle DDL transactions with file specifications.
The following procedure can handle different file system organization between the primary database and standby database, as long as you use a specific naming convention for your file-specification string.
-
Create the skip procedure to handle tablespace DDL transactions:
CREATE OR REPLACE PROCEDURE SYS.HANDLE_TBS_DDL ( OLD_STMT IN VARCHAR2, STMT_TYP IN VARCHAR2, SCHEMA IN VARCHAR2, NAME IN VARCHAR2, XIDUSN IN NUMBER, XIDSLT IN NUMBER, XIDSQN IN NUMBER, ACTION OUT NUMBER, NEW_STMT OUT VARCHAR2 ) AS BEGIN -- All primary file specification that contains a directory -- /usr/orcl/primary/dbs -- should go to /usr/orcl/stdby directory specification NEW_STMT := REPLACE(OLD_STMT, '/usr/orcl/primary/dbs', '/usr/orcl/stdby'); ACTION := DBMS_LOGSTDBY.SKIP_ACTION_REPLACE; EXCEPTION WHEN OTHERS THEN ACTION := DBMS_LOGSTDBY.SKIP_ACTION_ERROR; NEW_STMT := NULL; END HANDLE_TBS_DDL; -
Stop SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
-
Register the skip procedure with SQL Apply:
SQL> EXECUTE DBMS_LOGSTDBY.SKIP (stmt => 'TABLESPACE', - > proc_name => 'sys.handle_tbs_ddl');
-
Start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
10.5.4 Modifying a Logical Standby Database
Logical standby databases can be used for reporting activities, even while SQL statements are being applied. The database guard controls user access to tables in a logical standby database, and the ALTER SESSION DISABLE GUARD statement is used to bypass the database guard and allow modifications to the tables in the logical standby database.
Note:
To use a logical standby database to host other applications that process data being replicated from the primary database while creating other tables of their own, the database guard must be set toSTANDBY. For such applications to work seamlessly, make sure that you are running with PRESERVE_COMMIT_ORDER set to TRUE (the default setting for SQL Apply). (See Oracle Database PL/SQL Packages and Types Reference for information about the PRESERVE_COMMIT_ORDER parameter in the DBMS_LOGSTDBY PL/SQL package.)
Issue the following SQL statement to set the database guard to STANDBY:
SQL> ALTER DATABASE GUARD STANDBY;
Under this guard setting, tables being replicated from the primary database are protected from user modifications, but tables created on the standby database can be modified by the applications running on the logical standby.
By default, a logical standby database operates with the database guard set to ALL, which is its most restrictive setting, and does not allow any user changes to be performed to the database. You can override the database guard to allow changes to the logical standby database by executing the ALTER SESSION DISABLE GUARD statement. Privileged users can issue this statement to turn the database guard off for the current session.
The following sections provide some examples. The discussions in these sections assume that the database guard is set to ALL or STANDBY.
10.5.4.1 Performing DDL on a Logical Standby Database
This section describes how to add a constraint to a table maintained through SQL Apply.
By default, only accounts with SYS privileges can modify the database while the database guard is set to ALL or STANDBY. If you are logged in as SYSTEM or another privileged account, you will not be able to issue DDL statements on the logical standby database without first bypassing the database guard for the session.
The following example shows how to stop SQL Apply, bypass the database guard, execute SQL statements on the logical standby database, and then reenable the guard. In this example, a soundex index is added to the surname column of SCOTT.EMP in order to speed up partial match queries. A soundex index could be prohibitive to maintain on the primary server.
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
Database altered.
SQL> ALTER SESSION DISABLE GUARD;
PL/SQL procedure successfully completed.
SQL> CREATE INDEX EMP_SOUNDEX ON SCOTT.EMP(SOUNDEX(ENAME));
Table altered.
SQL> ALTER SESSION ENABLE GUARD;
PL/SQL procedure successfully completed.
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
Database altered.
SQL> SELECT ENAME,MGR FROM SCOTT.EMP WHERE SOUNDEX(ENAME) = SOUNDEX('CLARKE');
ENAME MGR
---------- ----------
CLARK 7839
Oracle recommends that you do not perform DML operations on tables maintained by SQL Apply while the database guard bypass is enabled. This will introduce deviations between the primary and standby databases that will make it impossible for the logical standby database to be maintained.
10.5.4.2 Modifying Tables That Are Not Maintained by SQL Apply
Sometimes, a reporting application must collect summary results and store them temporarily or track the number of times a report was run. Although the main purpose of the application is to perform reporting activities, the application might need to issue DML (insert, update, and delete) operations on a logical standby database. It might even need to create or drop tables.
You can set up the database guard to allow reporting operations to modify data as long as the data is not being maintained through SQL Apply. To do this, you must:
-
Specify the set of tables on the logical standby database to which an application can write data by executing the
DBMS_LOGSTDBY.SKIPprocedure. Skipped tables are not maintained through SQL Apply. -
Set the database guard to protect only standby tables.
In the following example, it is assumed that the tables to which the report is writing are also on the primary database.
The example stops SQL Apply, skips the tables, and then restarts SQL Apply. The reporting application will be able to write to TESTEMP% in HR. They will no longer be maintained through SQL Apply.
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
Database altered.
SQL> EXECUTE DBMS_LOGSTDBY.SKIP(stmt => 'SCHEMA_DDL',-
schema_name => 'HR', -
object_name => 'TESTEMP%');
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGSTDBY.SKIP('DML','HR','TESTEMP%');
PL/SQL procedure successfully completed.
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
Database altered.
Once SQL Apply starts, it needs to update metadata on the standby database for the newly specified tables added in the skip rules. Attempts to modify the newly skipped table until SQL Apply has had a chance to update the metadata will fail. You can find out if SQL Apply has successfully taken into account the SKIP rule you just added by issuing the following query:
SQL> SELECT VALUE FROM SYSTEM.LOGSTDBY$PARAMETERS WHERE NAME = 'GUARD_STANDBY'; VALUE --------------- Ready
When the VALUE column displays Ready, SQL Apply has successfully updated all relevant metadata for the skipped table, and it is safe to modify the table.
10.5.5 Adding or Re-Creating Tables On a Logical Standby Database
Typically, you use the DBMS_LOGSTDBY.INSTANTIATE_TABLE procedure to re-create a table after an unrecoverable operation. You can also use this procedure to enable SQL Apply on a table that was formerly skipped.
Before you can create a table, it must meet the requirements described in Section 4.1.2, "Ensure Table Rows in the Primary Database Can Be Uniquely Identified". Then, you can use the following steps to re-create a table named HR.EMPLOYEES and resume SQL Apply. The directions assume that there is already a database link BOSTON defined to access the primary database.
The following list shows how to re-create a table and restart SQL Apply on that table:
-
Stop SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
-
Ensure no operations are being skipped for the table in question by querying the
DBA_LOGSTDBY_SKIPview:SQL> SELECT * FROM DBA_LOGSTDBY_SKIP; ERROR STATEMENT_OPT OWNER NAME PROC ----- ------------------- ------------- ---------------- ----- N SCHEMA_DDL HR EMPLOYEES N DML HR EMPLOYEES N SCHEMA_DDL OE TEST_ORDER N DML OE TEST_ORDER
Because you already have skip rules associated with the table that you want to re-create on the logical standby database, you must first delete those rules. You can accomplish that by calling the
DBMS_LOGSTDBY.UNSKIPprocedure. For example:SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP(stmt => 'DML', - > schema_name => 'HR', - > object_name => 'EMPLOYEES');
SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP(stmt => 'SCHEMA_DDL', - > schema_name => 'HR', - > object_name => 'EMPLOYEES');
-
Re-create the table
HR.EMPLOYEESwith all its data in the logical standby database by using theDBMS_LOGSTDBY.INSTANTIATE_TABLEprocedure. For example:SQL> EXECUTE DBMS_LOGSTDBY.INSTANTIATE_TABLE(schema_name => 'HR', - > table_name => 'EMPLOYEES', - > dblink => 'BOSTON');
-
Start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
See Also:
Oracle Database PL/SQL Packages and Types Reference for information about theDBMS_LOGSTDBY.UNSKIPand theDBMS_LOGSTDBY.INSTANTIATE_TABLEprocedures
To ensure a consistent view across the newly instantiated table and the rest of the database, wait for SQL Apply to catch up with the primary database before querying this table. You can do this by performing the following steps:
-
On the primary database, determine the current SCN by querying the
V$DATABASEview:SQL> SELECT CURRENT_SCN FROM V$DATABASE@BOSTON; CURRENT_SCN --------------------- 345162788
-
Make sure SQL Apply has applied all transactions committed before the
CURRENT_SCNreturned in the previous query:SQL> SELECT APPLIED_SCN FROM V$LOGSTDBY_PROGRESS; APPLIED_SCN -------------------------- 345161345
When the
APPLIED_SCNreturned in this query is greater than theCURRENT_SCNreturned in the first query, it is safe to query the newly re-created table.
10.6 Managing Specific Workloads In the Context of a Logical Standby Database
This section contains the following topics:
-
Importing a Transportable Tablespace to the Primary Database
-
How Triggers and Constraints Are Handled on a Logical Standby Database
-
Recovering Through the Point-in-Time Recovery Performed at the Primary
-
Running an Oracle Streams Capture Process on a Logical Standby Database
10.6.1 Importing a Transportable Tablespace to the Primary Database
Perform the following steps to import a tablespace to the primary database.
-
Disable the guard setting so that you can modify the logical standby database:
SQL> ALTER DATABASE GUARD STANDBY;
-
Import the tablespace at the logical standby database.
-
Enable the database guard setting:
SQL> ALTER DATABASE GUARD ALL;
-
Import the tablespace at the primary database.
10.6.2 Using Materialized Views
Logical Standby automatically skips DDL statements related to materialized views:
-
CREATE,ALTER, orDROP MATERIALIZED VIEW -
CREATE,ALTERorDROP MATERIALIZED VIEW LOG
New materialized views that are created, altered, or dropped on the primary database after the logical standby database has been created will not be created on the logical standby database. However, materialized views created on the primary database prior to the logical standby database being created will be present on the logical standby database.
Logical Standby supports the creation and maintenance of new materialized views locally on the logical standby database in addition to other kinds of auxiliary data structure. For example, online transaction processing (OLTP) systems frequently use highly normalized tables for update performance but these can lead to slower response times for complex decision support queries. Materialized views that denormalize the replicated data for more efficient query support on the logical standby database can be created, as follows (connect as user SYS before issuing these statements):
SQL> ALTER SESSION DISABLE GUARD; SQL> CREATE MATERIALIZED VIEW LOG ON SCOTT.EMP - > WITH ROWID (EMPNO, ENAME, MGR, DEPTNO) INCLUDING NEW VALUES; SQL> CREATE MATERIALIZED VIEW LOG ON SCOTT.DEPT - > WITH ROWID (DEPTNO, DNAME) INCLUDING NEW VALUES; SQL> CREATE MATERIALIZED VIEW SCOTT.MANAGED_BY - > REFRESH ON DEMAND - > ENABLE QUERY REWRITE - > AS SELECT E.ENAME, M.ENAME AS MANAGER - > FROM SCOTT.EMP E, SCOTT.EMP M WHERE E.MGR=M.EMPNO; SQL> CREATE MATERIALIZED VIEW SCOTT.IN_DEPT - > REFRESH FAST ON COMMIT - > ENABLE QUERY REWRITE - > AS SELECT E.ROWID AS ERID, D.ROWID AS DRID, E.ENAME, D.DNAME - > FROM SCOTT.EMP E, SCOTT.DEPT D WHERE E.DEPTNO=D.DEPTNO;
On a logical standby database:
-
An ON-COMMIT materialized view is refreshed automatically on the logical standby database when the transaction commit occurs.
-
An ON-DEMAND materialized view is not automatically refreshed: the
DBMS_MVIEW.REFRESHprocedure must be executed to refresh it.
For example, issuing the following command would refresh the ON-DEMAND materialized view created in the previous example:
SQL> ALTER SESSION DISABLE GUARD; SQL> EXECUTE DBMS_MVIEW.REFRESH (LIST => 'SCOTT.MANAGED_BY', METHOD => 'C');
If DBMS_SCHEDULER jobs are being used to periodically refresh on-demand materialized views, the database guard must be set to STANDBY. (It is not possible to use the ALTER SESSION DISABLE GUARD statement inside a PL/SQL block and have it take effect.)
10.6.3 How Triggers and Constraints Are Handled on a Logical Standby Database
By default, triggers and constraints are automatically enabled and handled on logical standby databases.
For triggers and constraints on tables maintained by SQL Apply:
-
Constraints — Check constraints are evaluated on the primary database and do not need to be re-evaluated on the logical standby database.
-
Triggers — The effects of the triggers executed on the primary database are logged and applied on the standby database.
For triggers and constraints on tables not maintained by SQL Apply:
-
Constraints are evaluated
-
Triggers are fired
10.6.4 Using Triggers to Replicate Unsupported Tables
DML triggers created on a table have their DBMS_DDL.SET_TRIGGER_FIRING_PROPERTY fire_once parameter set to TRUE by default. The triggers fire only when the table is modified by a user process. They are automatically disabled inside SQL Apply processes, and thus do not fire when a SQL Apply process modifies the table. There are two ways to fire a trigger as a result of SQL Apply process making a change to a maintained table:
-
Set the
fire_onceparameter of a trigger toFALSE, which allows it to fire in either the context of a user process or a SQL Apply process -
Set the
apply_server_onlyparameter toTRUEwhich results in the trigger firing only in the context of a SQL Apply process and not in the context of a user process
| fire_once | apply_server_only | description |
|---|---|---|
TRUE |
FALSE |
This is the default property setting for a DML trigger. The trigger fires only when a user process modifies the base table. |
FALSE |
FALSE |
The trigger will fire both in the context of a user process and in the context of a SQL Apply process modifying the base table.You can distinguish the two contexts by using the DBMS_LOGSTDBY.IS_APPLY_SERVER function. |
TRUE/FALSE |
TRUE |
The trigger only fires when a SQL Apply process modifies the base table. The trigger does not fire when a user process modifies the base table.Thus, the apply_server_only property overrides the fire_once parameter of a trigger. |
Tables that are unsupported due to simple object type columns can be replicated by creating triggers that will fire in the context of a SQL Apply process (either by setting the fire_once parameter of such a trigger to FALSE or by setting the apply_server_only parameter of such a trigger to TRUE). A regular DML trigger can be used on the primary database to flatten the object type into a table that can be supported. The trigger that will fire in the context of SQL Apply process on the logical standby will reconstitute the object type and update the unsupported table in a transactional manner.
See Also:
-
Oracle Database PL/SQL Packages and Types Reference for descriptions of the
DBMS_DDL.SET_TRIGGER_FIRING_PROPERTYprocedure and theDBMS_LOGSTDBY.IS_APPLY_SERVERfunction
The following example shows how a table with a simple object type could be replicated using triggers. This example shows how to handle inserts; the same principle can be applied to updating and deleting. Nested tables and VARRAYs can also be replicated using this technique with the additional step of a loop to normalize the nested data.
-- simple object type
create or replace type Person as object
(
FirstName varchar2(50),
LastName varchar2(50),
BirthDate Date
)
-- unsupported object table
create table employees
(
IdNumber varchar2(10) ,
Department varchar2(50),
Info Person
)
-- supported table populated via trigger
create table employees_transfer
(
t_IdNumber varchar2(10),
t_Department varchar2(50),
t_FirstName varchar2(50),
t_LastName varchar2(50),
t_BirthDate Date
)
--
-- create this trigger to flatten object table on the primary
-- this trigger will not fire on the standby
--
create or replace trigger flatten_employees
after insert on employees for each row
declare
begin
insert into employees_transfer
(t_IdNumber, t_Department, t_FirstName, t_LastName, t_BirthDate)
values
(:new.IdNumber, :new.Department,
:new.Info.FirstName,:new.Info.LastName, :new.Info.BirthDate);
end
--
-- Option#1 (Better Option: Create a trigger and
-- set its apply-server-only property to TRUE)
-- create this trigger at the logical standby database
-- to populate object table on the standby
-- this trigger only fires when apply replicates rows
-- to the standby
--
create or replace trigger reconstruct_employees_aso
after insert on employees_transfer for each row
begin
insert into employees (IdNumber, Department, Info)
values (:new.t_IdNumber, :new.t_Department,
Person(:new.t_FirstName, :new.t_LastName, :new.t_BirthDate));
end
-- set this trigger to fire from the apply server
execute dbms_ddl.set_trigger_firing_property( -
trig_owner => 'scott', -
trig_name => 'reconstruct_employees_aso',
property => dbms_ddl.apply_server_only,
setting => TRUE);
--
-- Option#2 (Create a trigger and set
-- its fire-once property to FALSE)
-- create this trigger at the logical standby database
-- to populate object table on the standby
-- this trigger will fire when apply replicates rows to -- the standby, but we will need to make sure we are
-- are executing inside a SQL Apply process by invoking
-- dbms_logstdby.is_apply_server function
--
create or replace trigger reconstruct_employees_nfo
after insert on employees_transfer for each row
begin
if dbms_logstdby.is_apply_server() then
insert into employees (IdNumber, Department, Info)
values (:new.t_IdNumber, :new.t_Department,
Person(:new.t_FirstName, :new.t_LastName, :new.t_BirthDate));
end if;
end
-- set this trigger to fire from the apply server
execute dbms_ddl.set_trigger_firing_property( -
trig_owner => 'scott', -
trig_name => 'reconstruct_employees_nfo',
property => dbms_ddl.fire_once,
setting => FALSE);
10.6.5 Recovering Through the Point-in-Time Recovery Performed at the Primary
When a logical standby database receives a new branch of redo data, SQL Apply automatically takes the new branch of redo data. For logical standby databases, no manual intervention is required if the standby database did not apply redo data past the new resetlogs SCN (past the start of the new branch of redo data)
The following table describes how to resynchronize the standby database with the primary database branch.
| If the standby database. . . | Then. . . | Perform these steps. . . |
|---|---|---|
| Has not applied redo data past the new resetlogs SCN (past the start of the new branch of redo data) | SQL Apply automatically takes the new branch of redo data. | No manual intervention is necessary. SQL Apply automatically resynchronizes the standby database with the new branch of redo data. |
| Has applied redo data past the new resetlogs SCN (past the start of the new branch of redo data) and Flashback Database is enabled on the standby database | The standby database is recovered in the future of the new branch of redo data. |
SQL Apply automatically resynchronizes the standby database with the new branch. |
| Has applied redo data past the new resetlogs SCN (past the start of the new branch of redo data) and Flashback Database is not enabled on the standby database | The primary database has diverged from the standby on the indicated primary database branch. | Re-create the logical standby database following the procedures in Chapter 4, "Creating a Logical Standby Database". |
| Is missing archived redo log files from the end of the previous branch of redo data | SQL Apply cannot continue until the missing log files are retrieved. | Locate and register missing archived redo log files from the previous branch. |
See Oracle Database Backup and Recovery User's Guide for more information about database incarnations, recovering through an OPEN RESETLOGS operation, and Flashback Database.
10.6.6 Running an Oracle Streams Capture Process on a Logical Standby Database
You can run an Oracle Streams capture process on a logical standby database to capture changes from any table that exists on the logical standby database (whether it is a local table or a maintained table that is being replicated from the primary database). When capturing changes to a maintained table, there will be additional latency as compared to running an Oracle Streams capture process at the primary database. The additional latency is because of the fact that when you are running at a logical standby, the Oracle Streams capture process must wait for the changes to be shipped from the primary to the logical standby and applied by SQL Apply. In most cases, if you are running real time apply, this will be no more than a few seconds.
It is important to note that the Oracle Streams capture process is associated with the database where it was created; the role of the database is irrelevant. For example, suppose you have a primary database named Boston and a logical standby named London. You cannot move the Oracle Streams capture process from one database to the other as you go through role transitions. For instance, if you created an Oracle Streams capture process on London when it was a logical standby, it will remain on London even when London becomes the primary as a result of a role transition operation such as a switchover or failover. For the Oracle Streams capture process to continue working after a role transition, you must write a role transition trigger such as the following:
create or replace trigger streams_aq_job_role_change1
after DB_ROLE_CHANGE on database
declare
cursor capture_aq_jobs is
select job_name, database_role
from dba_scheduler_job_roles
where job_name like 'AQ_JOB%';
u capture_aq_jobs%ROWTYPE;
my_db_role varchar2(16);
begin
if (dbms_logstdby.db_is_logstdby() = 1) then my_db_role := 'LOGICAL STANDBY';
else my_db_role := 'PRIMARY';
end if;
open capture_aq_jobs;
loop
fetch capture_aq_jobs into u;
exit when capture_aq_jobs%NOTFOUND;
if (u.database_role != my_db_role) then
dbms_scheduler.set_attribute(u.job_name,
'database_role',
my_db_role);
end if;
end loop;
close capture_aq_jobs;
exception
when others then
begin
raise;
end;
end;
10.7 Tuning a Logical Standby Database
This section contains the following topics:
10.7.1 Create a Primary Key RELY Constraint
On the primary database, if a table does not have a primary key or a unique index and you are certain the rows are unique, then create a primary key RELY constraint. On the logical standby database, create an index on the columns that make up the primary key. The following query generates a list of tables with no index information that can be used by a logical standby database to apply to uniquely identify rows. By creating an index on the following tables, performance can be improved significantly.
SQL> SELECT OWNER, TABLE_NAME FROM DBA_TABLES -
> WHERE OWNER NOT IN (SELECT OWNER FROM DBA_LOGSTDBY_SKIP -
> WHERE STATEMENT_OPT = 'INTERNAL SCHEMA') -
> MINUS -
> SELECT DISTINCT TABLE_OWNER, TABLE_NAME FROM DBA_INDEXES -
> WHERE INDEX_TYPE NOT LIKE ('FUNCTION-BASED%') -
> MINUS -
> SELECT OWNER, TABLE_NAME FROM DBA_LOGSTDBY_UNSUPPORTED;
You can add a rely primary key constraint to a table on the primary database, as follows:
-
Add the primary key rely constraint at the primary database:
SQL> ALTER TABLE HR.TEST_EMPLOYEES ADD PRIMARY KEY (EMPNO) RELY DISABLE;
This will ensure that the
EMPNOcolumn, which can be used to uniquely identify the rows inHR.TEST_EMPLOYEEStable, will be supplementally logged as part of any updates done on that table.Note that the
HR.TEST_EMPLOYEEStable still does not have any unique index specified on the logical standby database. This may causeUPDATEstatements to do full table scans on the logical standby database. You can remedy that by adding a unique index on theEMPNOcolumn on the logical standby database.See Section 4.1.2, "Ensure Table Rows in the Primary Database Can Be Uniquely Identified" and Oracle Database SQL Language Reference for more information aboutRELYconstraints.Perform the remaining steps on the logical standby database.
-
Stop SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
-
Disable the guard so that you can modify a maintained table on the logical standby database:
SQL> ALTER SESSION DISABLE GUARD;
-
Add a unique index on
EMPNOcolumn:SQL> CREATE UNIQUE INDEX UI_TEST_EMP ON HR.TEST_EMPLOYEES (EMPNO);
-
Enable the guard:
SQL> ALTER SESSION ENABLE GUARD;
-
Start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
10.7.2 Gather Statistics for the Cost-Based Optimizer
Statistics should be gathered on the standby database because the cost-based optimizer (CBO) uses them to determine the optimal query execution path. New statistics should be gathered after the data or structure of a schema object is modified in ways that make the previous statistics inaccurate. For example, after inserting or deleting a significant number of rows into a table, collect new statistics on the number of rows.
Statistics should be gathered on the standby database because DML and DDL operations on the primary database are executed as a function of the workload. While the standby database is logically equivalent to the primary database, SQL Apply might execute the workload in a different way. This is why using the STATS pack on the logical standby database and the V$SYSSTAT view can be useful in determining which tables are consuming the most resources and table scans.
See Also:
-
Section 4.1.2, "Ensure Table Rows in the Primary Database Can Be Uniquely Identified"
-
Oracle Database SQL Language Reference for more information about
RELYconstraints
10.7.3 Adjust the Number of Processes
The following sections describe:
There are three parameters that can be modified to control the number of processes allocated to SQL Apply: MAX_SERVERS, APPLY_SERVERS, and PREPARE_SERVERS. The following relationships must always hold true:
-
APPLY_SERVERS + PREPARE_SERVERS =MAX_SERVERS - 3This is because SQL Apply always allocates one process for the
READER,BUILDER, andANALYZERroles. -
By default,
MAX_SERVERSis set to 9,PREPARE_SERVERSis set to 1, andAPPLY_SERVERSis set to 5. -
Oracle recommends that you only change the
MAX_SERVERSparameter through theDBMS_LOGSTDBY.APPLY_SETprocedure, and allow SQL Apply to distribute the server processes appropriately between prepare and apply processes. -
SQL Apply uses a process allocation algorithm that allocates 1
PREPARE_SERVERfor every 20 server processes allocated to SQL Apply as specified byMAX_SERVERand limits the number ofPREPARE_SERVERSto 5. Thus, if you setMAX_SERVERSto any value between 1 and 20, SQL Apply allocates 1 server process to act as aPREPARER, and allocates the rest of the processes asAPPLIERSwhile satisfying the relationship previously described. Similarly, if you setMAX_SERVERSto a value between 21 and 40, SQL Apply allocates 2 server processes to act asPREPARERSand the rest asAPPLIERS, while satisfying the relationship previously described. You can override this internal process allocation algorithm by settingAPPLY_SERVERSandPREPARE_SERVERSdirectly, provided that the previously described relationship is satisfied.
10.7.3.1 Adjusting the Number of APPLIER Processes
Perform the following steps to find out whether adjusting the number of APPLIER processes will help you achieve greater throughput:
-
Determine if
APPLIERprocesses are busy by issuing the following query:SQL> SELECT COUNT(*) AS IDLE_APPLIER - > FROM V$LOGSTDBY_PROCESS - > WHERE TYPE = 'APPLIER' and status_code = 16116; IDLE_APPLIER ------------------------- 0
-
Once you are sure there are no idle
APPLIERprocesses, issue the following query to ensure there is enough work available for additionalAPPLIERprocesses if you choose to adjust the number ofAPPLIERS:SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME = 'txns applied' OR NAME = 'distinct txns in queue';
These two statistics keep a cumulative total of transactions that are ready to be applied by the
APPLIERprocesses and the number of transactions that have already been applied.If the number (
distinct txns in queue - txns applied) is higher than twice the number ofAPPLIERprocesses available, an improvement in throughput is possible if you increase the number ofAPPLIERprocesses.Note:
The number is a rough measure of ready work. The workload may be such that an interdependency between ready transactions will prevent additional availableAPPLIERprocesses from applying them. For instance, if the majority of the transactions that are ready to be applied are DDL transactions, adding moreAPPLIERprocesses will not result in a higher throughput.Suppose you want to adjust the number of
APPLIERprocesses to 20 from the default value of 5, while keeping the number ofPREPARERprocesses to 1. Because you have to satisfy the following equation:APPLY_SERVERS + PREPARE_SERVERS = MAX_SERVERS - 3
you will first need to set
MAX_SERVERSto 24. Once you have done that, you can then set the number ofAPPLY_SERVERSto 20, as follows:SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('MAX_SERVERS', 24); SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('APPLY_SERVERS', 20);
10.7.3.2 Adjusting the Number of PREPARER Processes
In only rare cases do you need to adjust the number of PREPARER processes. Before you decide to increase the number of PREPARER processes, ensure the following conditions are true:
-
All
PREPARERprocesses are busy -
The number of transactions ready to be applied is less than the number of
APPLIERprocesses available -
There are idle
APPLIERprocesses
The following steps show how to determine these conditions are true:
-
Ensure all
PREPARERprocesses are busy:SQL> SELECT COUNT(*) AS IDLE_PREPARER - > FROM V$LOGSTDBY_PROCESS - > WHERE TYPE = 'PREPARER' and status_code = 16116; IDLE_PREPARER ------------- 0
-
Ensure the number of transactions ready to be applied is less than the number of
APPLIERprocesses:SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME = 'txns applied' OR - > NAME = 'distinct txns in queue'; NAME VALUE --------------------- ------- txns applied 27892 distinct txns in queue 12896
SQL> SELECT COUNT(*) AS APPLIER_COUNT - > FROM V$LOGSTDBY_PROCESS WHERE TYPE = 'APPLIER'; APPLIER_COUNT ------------- 20
Note: Issue this query several times to ensure this is not a transient event.
-
Ensure there are idle
APPLIERprocesses:SQL> SELECT COUNT(*) AS IDLE_APPLIER - > FROM V$LOGSTDBY_PROCESS - > WHERE TYPE = 'APPLIER' and status_code = 16116; IDLE_APPLIER ------------------------- 19
In the example, all three conditions necessary for increasing the number of PREPARER processes have been satisfied. Suppose you want to keep the number of APPLIER processes set to 20, and increase the number of PREPARER processes from 1 to 3. Because you always have to satisfy the following equation:
APPLY_SERVERS + PREPARE_SERVERS = MAX_SERVERS - 3
you will first need to increase the number MAX_SERVERS from 24 to 26 to accommodate the increased number of preparers. You can then increase the number of PREPARER processes, as follows:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('MAX_SERVERS', 26);
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('PREPARE_SERVERS', 3);
10.7.4 Adjust the Memory Used for LCR Cache
For some workloads, SQL Apply may use a large number of pageout operations, thereby reducing the overall throughput of the system. To find out whether increasing memory allocated to LCR cache will be beneficial, perform the following steps:
-
Issue the following query to obtain a snapshot of pageout activity:
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME LIKE '%page%' - > OR NAME LIKE '%uptime%' OR NAME LIKE '%idle%';
NAME VALUE ---------------------------- -------------- coordinator uptime (seconds) 894856 bytes paged out 20000 pageout time (seconds) 2 system idle time (seconds) 1000
-
Issue the query again in 5 minutes:
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME LIKE '%page%' - > OR NAME LIKE '%uptime%' OR NAME LIKE '%idle%';
NAME VALUE ---------------------------- -------------- coordinator uptime (seconds) 895156 bytes paged out 1020000 pageout time (seconds) 100 system idle time (seconds) 1000
-
Compute the normalized pageout activity. For example:
Change in coordinator uptime (C)= (895156 – 894856) = 300 secs Amount of additional idle time (I)= (1000 – 1000) = 0 Change in time spent in pageout (P) = (100 – 2) = 98 secs Pageout time in comparison to uptime = P/(C-I) = 98/300 ~ 32.67%
Ideally, the pageout activity should not consume more than 5 percent of the total uptime. If you continue to take snapshots over an extended interval and you find the pageout activities continue to consume a significant portion of the apply time, increasing the memory size may provide some benefits. You can increase the memory allocated to SQL Apply by setting the memory allocated to LCR cache (for this example, the SGA is set to 1 GB):
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('MAX_SGA', 1024);
PL/SQL procedure successfully completed
10.7.5 Adjust How Transactions are Applied On the Logical Standby Database
By default transactions are applied on the logical standby database in the exact order in which they were committed on the primary database. The strict default order of committing transactions allow any application to run transparently on the logical standby database.
However, many applications do not require such strict ordering among all transactions. Such applications do not require transactions containing non-overlapping sets of rows to be committed in the same order that they were committed at the primary database. This less strict ordering typically results in higher apply rates at the logical standby database. You can change the default order of committing transactions by performing the following steps:
-
Stop SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY; Database altered
-
Issue the following to allow transactions to be applied out of order from how they were committed on the primary databases:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('PRESERVE_COMMIT_ORDER', 'FALSE'); PL/SQL procedure successfully completed -
Start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE; Database altered
Should you ever wish to, you can change back the apply mode as follows:
-
Stop SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY; Database altered
-
Restore the default value for the
PRESERVE_COMMIT_ORDERparameter:SQL> EXECUTE DBMS_LOGSTDBY.APPLY_UNSET('PRESERVE_COMMIT_ORDER'); PL/SQL procedure successfully completed -
Start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE; Database altered
For a typical online transaction processing (OLTP) workload, the nondefault mode can provide a 50 percent or better throughput improvement over the default apply mode.
10.8 Backup and Recovery in the Context of a Logical Standby Database
You can back up your logical standby database using the traditional methods available and then recover it by restoring the database backup and performing media recovery on the archived logs, in conjunction with the backup. The following items are relevant in the context of a logical standby database.
Considerations When Creating and Using a Local RMAN Recovery Catalog
If you plan to create the RMAN recovery catalog or perform any RMAN activity that modifies the catalog, you must be running with GUARD set to STANDBY at the logical standby database.
You can leave GUARD set to ALL, if the local recovery catalog is kept only in the logical standby control file.
Considerations For Control File Backup
Oracle recommends that you take a control file backup immediately after instantiating a logical standby database.
Considerations For Point-in-Time Recovery
When SQL Apply is started for the first time following point-in-time recovery, it must be able to either find the required archived logs on the local system or to fetch them from the primary database. Use the V$LOGSTDBY_PROCESS view to determine if any archived logs need to be restored on the primary database.
Considerations For Tablespace Point-in-Time Recovery
If you perform point-in-time recovery for a tablespace in a logical standby database, you must ensure one of the following:
-
The tablespace contains no tables or partitions that are being maintained by the SQL Apply process
-
If the tablespace contains tables or partitions that are being maintained by the SQL Apply process, you should either use the
DBMS_LOGSTDBY.INSTANTIATE_TABLE procedure to reinstantiate all of the maintained tables contained in the recovered tablespace at the logical standby database, or useDBMS_LOGSTDBY.SKIPprocedure to register all tables contained in the recovered tablespace to be skipped from the maintained table list at the logical standby database.