1 Understanding Oracle Text Application Development
This chapter discusses the following topics:
1.1 Introduction to Oracle Text
Oracle Text enables you to build text query applications and document classification applications. Oracle Text provides indexing, word and theme searching, and viewing capabilities for text.
To design an Oracle Text application, first determine the type of queries you expect to run. This enables you to choose the most suitable index for the task.
Consider the following three categories of applications for Oracle Text:
1.2 Document Collection Applications
A text query application enables users to search document collections, such as Web sites, digital libraries, or document warehouses. The collection is typically static with no significant change in content after the initial indexing run. Documents can be of any size and of different formats, such as HTML, PDF, or Microsoft Word. These documents are stored in a document table. Searching is enabled by first indexing the document collection.
Queries usually consist of words or phrases. Application users can specify logical combinations of words and phrases using operators such as OR and AND. Other query operations can be used to improve the search results, such as stemming, proximity searching, and wildcarding.
An important factor for this type of application is retrieving documents relevant to a query while retrieving as few non-relevant documents as possible. The most relevant documents must be ranked high in the result list.
The queries for this type of application are best served with a CONTEXT index on your document table. To query this index, the application uses the SQL CONTAINS operator in the WHERE clause of a SELECT statement.
Figure 1-1 Overview of Text Query Application
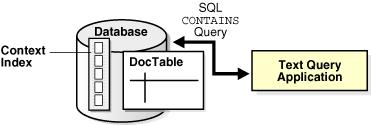
Description of "Figure 1-1 Overview of Text Query Application"
1.2.1 Flowchart of Text Query Application
A typical text query application on a document collection enables the user to enter a query. The application enters a CONTAINS query and returns a list, called a hitlist, of documents that satisfy the query. The results are usually ranked by relevance. The application enables the user to view one or more documents in the hitlist.
For example, an application might index URLs (HTML files) on the World Wide Web and provide query capabilities across the set of indexed URLs. Hitlists returned by the query application are composed of URLs that the user can visit.
Figure 1-2 illustrates the flowchart of how a user interacts with a simple query application:
-
The user enters a query.
-
The application runs a
CONTAINSquery. -
The application presents a hitlist.
-
The user selects document from hitlist.
-
The application presents a document to the user for viewing.
Figure 1-2 Flowchart of a query application
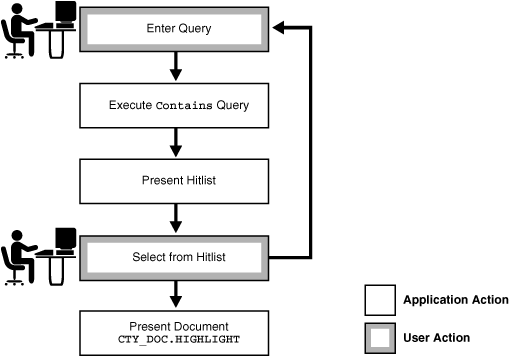
Description of "Figure 1-2 Flowchart of a query application"
1.3 Catalog Information Applications
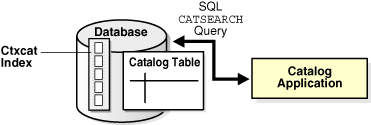
Catalog information consists of inventory type information, such as that of an online book store or auction site. The stored information consists of text information, such as book titles, and related structured information, such as price. The information is usually updated regularly to keep the online catalog up to date with the inventory.
Queries are usually a combination of a text component and a structured component. Results are almost always sorted by a structured component, such as date or price. Good response time is always an important factor with this type of query application.
Catalog applications are best served by a CTXCAT index. Query this index with the CATSEARCH operator in the WHERE clause of a SELECT statement.
Figure 1-3 illustrates the relation of the catalog table, its CTXCAT index, and the catalog application that uses the CATSEARCH operator to query the index.
1.3.1 Flowchart for Catalog Query Application
A catalog application enables users to search for specific items in catalogs. For example, an online store application enables users to search for and purchase items in inventory. Typically, the user query consists of a text component that searches across the textual descriptions plus some other ordering criteria, such as price or date.
Figure 1-4 illustrates the flowchart of a catalog query application for an online electronics store.
-
The user enters the query, consisting of a text component (for example, cd player) and a structured component (for example, order by price).
-
The application executes the
CATSEARCHquery. -
The application shows the results ordered accordingly.
-
The user browses the results.
-
The user then either enters another query or performs an action, such as purchasing the item.
Figure 1-4 Flowchart of a Catalog Query Application
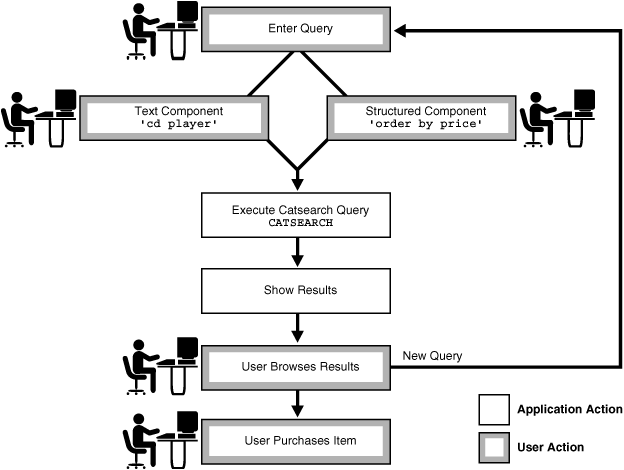
Description of "Figure 1-4 Flowchart of a Catalog Query Application"
1.4 Document Classification Applications
In a document classification application, an incoming stream or a set of documents is compared to a pre-defined set of rules. When a document matches one or more rules, the application performs some action.
For example, assume there is an incoming stream of news articles. You can define a rule to represent the category of Finance. The rule is essentially one or more queries that select document about the subject of Finance. The rule might have the form 'stocks or bonds or earnings'.
When a document arrives about a Wall Street earnings forecast and satisfies the rules for this category, the application takes an action, such as tagging the document as Finance or e-mailing one or more users.
To create a document classification application, create a table of rules and then create a CTXRULE index. To classify an incoming stream of text, use the MATCHES operator in the WHERE clause of a SELECT statement. See Figure 1-5 for the general flow of a classification application.
Figure 1-5 Overview of a Document Classification Application

Description of "Figure 1-5 Overview of a Document Classification Application"
1.5 XML Search Applications
An XML search application performs searches over XML documents. A regular document search usually searches across a set of documents to return documents that satisfy a text predicate; an XML search often uses the structure of the XML document to restrict the search. Typically, only that part of the document that satisfies the search is returned. For example, instead of finding all purchase orders that contain the word electric, the user might need only purchase orders in which the comment field contains electric.
Oracle Text enables you to perform XML searching using the following approaches:
1.5.1 Using Oracle Text
The CONTAINS operator is well suited to structured searching, enabling you to perform restrictive searches with the WITHIN, HASPATH, and INPATH operators. If you use a CONTEXT index, then you can also benefit from the following characteristics of Oracle Text searches:
-
Searches are token-based, whitespace-normalized
-
Hitlists are ranked by relevance
-
Case-sensitive searching
-
Section searching
-
Linguistic features such as stemming and fuzzy searching
-
Performance-optimized queries for large document sets
See Also:
"XML Section Searching with Oracle Text"1.5.2 Using the Oracle XML DB Framework
With Oracle XML DB, you load your XML documents in an XMLType column. XML searching with Oracle XML DB usually consists of an XPATH expression within an existsNode(), extract(), or extractValue() query. This type of search can be characterized as follows:
-
It is a non-text search with equality and range on dates and numbers.
-
It is a string search that is character-based, where all characters are treated the same.
-
It has the ability to leverage the
ora:contains()function with aCTXXPATHindex to speed upexistsNode()queries.
This type of search has the following disadvantages:
-
It has no special linguistic processing.
-
It uses exact matching, so there is no notion of relevance.
-
It can be very slow for some searches, such as wildcarding, as with:
WHERE col1 like '%dog%'
See Also:
Oracle XML DB Developer's Guide1.5.3 Combining Oracle Text features with Oracle XML DB
You can combine the features of Oracle Text and Oracle XML DB for applications where you want to do a full-text retrieval, leveraging the XML structure by entering queries such as "find all nodes that contain the word Pentium." Do so in one of two ways:
1.5.3.1 Using the Text-on-XML Method
With Oracle Text, you can create a CONTEXT index on a column that contains XML data. The column type can be XMLType, but it can also be any supported type provided you use the correct index preference for XML data.
With the Text-on-XML method, use the standard CONTAINS query and add a structured constraint to limit the scope of a search to a particular section, field, tag, or attribute. This amounts to specifying the structure inside text operators, such as WITHIN, HASPATH, and INPATH.
For example, set up your CONTEXT index to create sections with XML documents. Consider the following XML document that defines a purchase order.
<?xml version="1.0"?>
<PURCHASEORDER pono="1">
<PNAME>Po_1</PNAME>
<CUSTNAME>John</CUSTNAME>
<SHIPADDR>
<STREET>1033 Main Street</STREET>
<CITY>Sunnyvalue</CITY>
<STATE>CA</STATE>
</SHIPADDR>
<ITEMS>
<ITEM>
<ITEM_NAME> Dell Computer </ITEM_NAME>
<DESC> Pentium 2.0 Ghz 500MB RAM </DESC>
</ITEM>
<ITEM>
<ITEM_NAME> Norelco R100 </ITEM_NAME>
<DESC>Electric Razor </DESC>
</ITEM>
</ITEMS>
</PURCHASEORDER>
To query all purchase orders that contain Pentium within the item description section, use the WITHIN operator:
SELECT id from po_tab where CONTAINS( doc, 'Pentium WITHIN desc') > 0;
Specify more complex criteria with XPATH expressions using the INPATH operator:
SELECT id from po_tab where CONTAINS(doc, 'Pentium INPATH (/purchaseOrder/items/item/desc') > 0;
1.5.3.2 Using the XML-on-Text Method
With the XML-on-Text method, you add text operations to an XML search. This includes using the ora:contains() function in the XPATH expression with existsNode(), extract(), and extractValue() queries. This amounts to including the full-text predicate inside the structure. For example:
SELECT
Extract(doc, '/purchaseOrder//desc{ora:contains(.,"pentium")>0]',
'xmlns:ora=http://xmlns.oracle.com/xdb')
"Item Comment" FROM po_tab_xmltype
/
Additionally you can improve the performance of existsNode(), extract(), and extractValue() queries using the CTXXPATH Text domain index.