6 Planning Your Replication Environment
Before you begin to plan your replication environment, it is important to understand the replication concepts and architecture described in the previous chapters of this book. After you understand replication concepts and architecture, this chapter presents important considerations for planning a replication environment.
This chapter contains these topics:
Considerations for Replicated Tables
The following sections discuss considerations for tables you plan to use in a replication environment:
Primary Keys and Replicated Tables
If possible, each replicated table should have a primary key. Where a primary key is not possible, each replicated table must have a set of columns that can be used as a unique identifier for each row of the table. If the tables that you plan to use in your replication environment do not have a primary key or a set of unique columns, then alter these tables accordingly. In addition, if you plan to create any primary key materialized views based on a master table or master materialized view, then that master must have a primary key.
Foreign Keys and Replicated Tables
When replicating tables with foreign key referential constraints, Oracle recommends that you always index foreign key columns and replicate these indexes, unless no updates and deletes are allowed in the parent table. Indexes are not replicated automatically. To replicate an index, add it to the master group containing its table using either the Advanced Replication interface in Oracle Enterprise Manager or the CREATE_MASTER_REPOBJECT procedure in the DBMS_REPCAT package.
Data Type Considerations for Replicated Tables
Advanced Replication supports the replication of tables and materialized views with columns that use the following data types:
-
VARCHAR2 -
NVARCHAR2 -
NUMBER -
DATE -
TIMESTAMP -
TIMESTAMPWITHTIMEZONE -
TIMESTAMPLOCALTIMEZONE -
INTERVALYEARTOMONTH -
INTERVALDAYTOSECOND -
RAW -
ROWID -
CHAR -
NCHAR -
CLOBwithBASICFILEstorage -
NCLOBwithBASICFILEstorage -
BLOBwithBASICFILEstorage -
XMLTypestored asCLOB -
User-defined types that do not use type inheritance or type evolution
-
Oracle-supplied types that do not use type inheritance or type evolution
The deferred and synchronous remote procedure call mechanism used for multimaster replication propagates only the piece-wise changes to the supported LOB data types when piece-wise updates and appends are applied to these LOB columns. Also, you cannot reference LOB columns in a WHERE clause of a materialized view's defining query.
You can replicate tables and materialized views that use user-defined types, including column objects, object tables, REFs, varrays, and nested tables.
Advanced Replication does not support the replication of tables and materialized views with columns that use the following data types:
-
FLOAT -
BINARY_FLOAT -
BINARY_DOUBLE -
LONG -
LONGRAW -
CLOBwithSECUREFILEstorage -
NCLOBwithSECUREFILEstorage -
BLOBwithSECUREFILEstorage -
BFILE -
XMLTypestored object relationally or as binary XML -
Expressiontype -
User-defined types that use type inheritance or type evolution
-
Oracle-supplied types that use type inheritance or type evolution
For Advanced Replication support, you should convert LONG data types to LOBs with BASICFILE storage.
Oracle also does not support the replication of UROWID columns in master tables or updatable materialized views. However, UROWID columns are allowed in read-only materialized views.
See Also:
-
Oracle Database Advanced Replication Management API Reference for information about converting a
LONGcolumn into a LOB column in a replicated table -
Oracle Database SQL Language Reference for information about data types
Unsupported Table Types
Advanced Replication does not support the replication of the following types of tables and does not support materialized views based on these types of tables:
In addition, tables with columns that have been encrypted using transparent data encryption are not supported for master replication. However, materialized views based on tables with columns that have been encrypted are supported.
Row-Level Dependency Tracking
When you create a table, you can specify the following options for tracking system change numbers (SCNs):
-
NOROWDEPENDENCIES, the default, specifies that the SCN is tracked at the data block level. -
ROWDEPENDENCIESspecifies that the SCN is tracked for each row in the table.
Using the ROWDEPENDENCIES option improves performance and scalability when using parallel propagation, but this option also requires six bytes of additional storage space for each row.
The following SQL statement creates a table with the ROWDEPENDENCIES option:
CREATE TABLE order_items (order_id NUMBER(12), line_item_id NUMBER(3) NOT NULL, product_id NUMBER(6) NOT NULL, unit_price NUMBER(8,2), quantity NUMBER(8) ) ROWDEPENDENCIES;
Oracle tracks the SCN for each row in this order_items table. You can also use the ROWDEPENDENCIES option in a CREATE CLUSTER statement if your tables are part of a cluster.
See Also:
"Data Propagation Dependency Maintenance" for more information about theROWDEPENDENCIES optionInitialization Parameters
Table 6-1 lists initialization parameters that are important for the operation, reliability, and performance of a replication environment. This table specifies whether each parameter is modifiable. A modifiable initialization parameter can be modified using the ALTER SYSTEM statement while an instance is running. Some of the modifiable parameters can also be modified for a single session using the ALTER SESSION statement.
Table 6-1 Initialization Parameters Important for Advanced Replication
| Parameter | Values | Description | Recommendation |
|---|---|---|---|
GLOBAL_NAMES |
Default: Range: Modifiable?: Yes |
Specifies whether a database link is required to have the same name as the database to which it connects. |
|
JOB_QUEUE_PROCESSES |
Default: Range: Modifiable?: Yes |
Specifies the number of Jn job slaves for each instance ( When |
This parameter should either be unset or set to at least 1. If it is set, then it should be set to the same value as the maximum number of jobs that can run simultaneously plus one. |
MEMORY_MAX_TARGET |
Default: Range: Modifiable?: No |
Specifies the maximum system-wide usable memory for the Oracle database. |
If the |
MEMORY_TARGET |
Default: Range: Modifiable?: Yes |
Specifies the system-wide usable memory for the Oracle database. |
Oracle recommends enabling the autotuning of the memory usage of the Oracle database by setting |
OPEN_LINKS |
Default: Range: Modifiable?: No |
Specifies the maximum number of concurrent open connections to remote databases in one session. These connections include the schema objects called database links, as well as external procedures and cartridges, each of which uses a separate process. |
If you are using synchronous replication, |
PARALLEL_MAX_SERVERS |
Default: Derived automatically Range: Modifiable?: Yes |
Specifies the maximum number of parallel execution processes and parallel recovery processes for an instance. As demand increases, Oracle increases the number of processes from the number created at instance startup up to this value. |
If you use parallel propagation, then ensure that the value of this parameter is set high enough to support it. |
PARALLEL_MIN_SERVERS |
Default: Range: Modifiable?: Yes |
Specifies the minimum number of parallel execution processes for the instance. This value is the number of parallel execution processes Oracle creates when the instance is started. |
If you use parallel propagation, then ensure that you have at least one process for each stream. |
PROCESSES |
Default: Range: Modifiable?: No |
Specifies the maximum number of operating system user processes that can simultaneously connect to Oracle. |
Ensure that the value of this parameter allows for all background processes, such as locks, job slaves, and parallel execution processes. |
REPLICATION_DEPENDENCY_TRACKING |
Default: Range: Modifiable?: No |
Enables or disables dependency tracking for read/write operations to the database. Dependency tracking is essential for propagating changes in a replication environment in parallel.
|
Typically, specify |
SGA_TARGET |
Default: Range: Modifiable?: Yes |
Specifies the total size of all SGA components. |
If |
SHARED_POOL_SIZE |
Default: If If If Range: The granule size to operating system-dependent limit Modifiable?: Yes |
Specifies in bytes the size of the shared pool. The shared pool contains shared cursors, stored procedures, control structures, and other structures. Larger values improve performance in multiuser systems. Smaller values use less memory. |
Typically, the shared pool should be larger for an Oracle database in a replication environment than in a nonreplication environment. You can monitor utilization of the shared pool by querying the view |
See Also:
-
Oracle Database Reference for more information about these initialization parameters
-
Oracle Database Administrator's Guide for more information about the
MEMORY_TARGET,MEMORY_MAX_TARGET, andSGA_TARGETparameters
Master Sites and Materialized View Sites
When you are planning your replication environment, you must decide whether the sites participating in the replication environment will be master sites or materialized view sites. Consider the characteristics and advantages of both types of replication sites when you are deciding whether a particular site in your replication environment should be a master site or a materialized view site. One replication environment can support both master sites and materialized view sites.
Table 6-2 Characteristics of Master Sites and Materialized View Sites
| Master Sites | Materialized View Sites |
|---|---|
|
Typically communicate with a small number of other master sites, and might communicate with a large number of materialized view sites |
Communicate with one master site or one master materialized view site |
|
Contain large amounts of data that are full copies of the other master sites' data |
Contain small amounts of data that can be subsets of the master site's or master materialized view site's data |
|
Typically communicate continuously with short intervals between data propagation |
Communicate periodically with longer intervals between bulk data transfers |
Advantages of Master Sites
Master sites have the following advantages:
-
Support for highly available data access by remote sites
-
Provide better support for frequent data manipulation language (DML) changes because changes are propagated automatically and, typically, at short intervals
-
Allow simultaneous DML changes and data propagation without locking tables
-
Can provide failover protection
To set up a master site, use either the Advanced Replication interface's Configure Master Sites for Replication Wizard or the replication management API.
See Also:
-
The Advanced Replication interface's online Help for instructions on using the Configure Master Sites for Replication Wizard to set up master sites in Oracle Enterprise Manager
-
The Oracle Database Advanced Replication Management API Reference for instructions on using the replication management API to set up a master site
-
"Designing for Survivability" for information about designing your replication environment for failover protection
Advantages of Materialized View Sites
Materialized view sites have the following advantages:
-
Support disconnected computing
-
Can contain a subset of its master site's or master materialized view site's data
To set up a materialized view site, you can use either the Advanced Replication interface's Configure Master and Materialized View Sites for Replication Wizard or the replication management API.
See Also:
-
The Advanced Replication interface's online Help for instructions on using the Configure Materialized View Sites for Replication Wizard to set up materialized view sites in Oracle Enterprise Manager
-
Oracle Database Advanced Replication Management API Reference for instructions on using the replication management API to set up a materialized view site
Preparing for Materialized Views
Most problems encountered with materialized view replication result from not preparing the environment properly. There are four essential tasks that you must perform before you begin creating your materialized view environment:
-
Create the necessary schema.
-
Create the necessary database links.
-
Assign the appropriate privileges.
-
Allocate sufficient job processes.
The Advanced Replication interface's Configure Master and Materialized View Sites for Replication Wizard automatically performs these tasks. The following discussion is provided to help you understand the replication environment and to help those who use the replication management API. After running Setup Wizard, create the necessary materialized view logs. See the Advanced Replication interface's online Help in Oracle Enterprise Manager for instructions on using the interface to set up your materialized view site.
See Also:
"Creating a Materialized View Log"If you are not able to use the Advanced Replication interface, then review the "Set Up Materialized View Sites" section in Chapter 2 of the Oracle Database Advanced Replication Management API Reference for detailed instructions on setting up your materialized view site using the replication management API.
The following sections describe what the Advanced Replication interface's Configure Master and Materialized View Sites for Replication Wizard or the script in the Oracle Database Advanced Replication Management API Reference does to set up your materialized view site.
Create Materialized View Site Users
Each materialized view site needs several users to perform the administrative and refreshing activities at the materialized view site. You must create and grant the necessary privileges to the materialized view administrator and to the refresher.
Create Master Site Users
You need equivalent proxy users at the target master site to perform tasks on behalf of the materialized view site users. Usually, a proxy materialized view administrator and a proxy refresher are created.
Create Schemas at Materialized View Site
A schema containing a materialized view in a remote database must correspond to the schema that contains the master table in the master database. Therefore, identify the schemas that contain the master tables that you want to replicate with materialized views. After you have identified the target schemas at the master database, create the corresponding accounts with the same names at the remote database. For example, if all master tables are in the sales schema of the ny.example.com database, then create a corresponding sales schema in the materialized view database sf.example.com.
See Also:
If you are reviewing the steps in Oracle Database Advanced Replication Management API Reference, then the necessary schemas are created as part of the script described in the instructions for creating a materialized view groupCreate Database Links
The defining query of a materialized view can use one or more database links to reference remote table data. Before creating materialized views, the database links you plan to use must be available. Furthermore, the account that a database link uses to access a remote database defines the security context under which Oracle creates and subsequently refreshes a materialized view.
To ensure proper behavior, a materialized view's defining query must use a database link that includes an embedded user name and password in its definition; you cannot use a public database link when creating a materialized view. A database link with an embedded name and password always establishes connections to the remote database using the specified account. Additionally, the remote account that the link uses must have the SELECT privileges necessary to access the data referenced in the materialized view's defining query.
Before creating your materialized views, you must create several administrative database links. Specifically, you should create a PUBLIC database link from the materialized view site to the master site. Doing so makes defining your private database links easier because you do not need to include the USING clause in each link. You also need private database links from the materialized view administrator to the proxy administrator and from the propagator to the receiver, but, if you use the Advanced Replication interface's Configure Master and Materialized View Sites for Replication Wizard, then these database links are created for you automatically.
See Also:
The information about security options in Oracle Database Advanced Replication Management API Reference for more informationAfter the administrative database links have been created, a private database link must be created connecting each replicated materialized view schema at the materialized view database to the corresponding schema at the master database. Be sure to embed the associated master database account information in each private database link at the materialized view database. For example, the hr schema at a materialized view database should have a private database link to the master database that connects using the hr user name and password.
Figure 6-1 Recommended Schema and Database Link Configuration
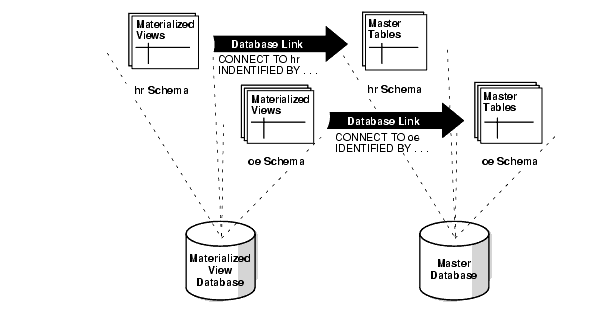
Description of "Figure 6-1 Recommended Schema and Database Link Configuration"
For multimaster replication, there must be no Virtual Private Database (VPD) restrictions on the replication propagator and receiver schemas. For materialized views, the defining query for the materialized view cannot be modified by VPD. VPD must return a NULL policy for the schema that performs both the create and refresh of the materialized view. Creating a materialized view with a non-NULL VPD policy is allowed when the USING TRUSTED CONSTRAINTS clause is specified. In this case, ensure that the materialized view behaves correctly. Materialized view results are computed based on the rows and columns filtered by VPD policy. Therefore, you must coordinate the materialized view definition with the VPD policy to ensure the correct results.
See Also:
-
Oracle Database Administrator's Guide for more information about database links
-
Oracle Database Security Guide for more information about VPD
-
Oracle Label Security Administrator's Guide for information about Advanced Replication and Oracle Label Security
Assign Privileges
Both the creator and the owner of the materialized view must be able to issue the defining SELECT statement of the materialized view. The owner is the schema that contains the materialized view. If a user other than the replication or materialized view administrator creates the materialized view, then that user must have the CREATE MATERIALIZED VIEW privilege and the appropriate SELECT privileges to execute the defining SELECT statement.
See Also:
If you are reviewing the steps in Oracle Database Advanced Replication Management API Reference, then the necessary privileges are granted as part of the script described in instructions for creating a materialized view group. Privilege requirements are also described in "Required Privileges for Materialized View Operations"Schedule Purge at Master Site
To keep the size of the deferred transaction queues in check, schedule a purge operation to remove all successfully completed deferred transactions from the deferred transaction queue. This operation might have already been performed at the master site. Scheduling the purge operation again does not harm the master site, but might change the purge scheduling characteristics.
Schedule Push
Scheduling a push at the materialized view site automatically propagates the deferred transactions at the materialized view site to the associated target master site using a database link. These types of database links are called scheduled links. Typically, there is only a single scheduled link for each materialized view group at a materialized view site, because a materialized view group only has a single target master site.
Allocate Job Slaves
It is important that you have allocated sufficient job slaves to handle the automation of your replication environment. The job slaves automatically propagate the deferred transaction queue, purge the deferred transaction queue, refresh materialized views, and so on.
For multimaster replication, each site has a scheduled link to each of the other master sites. For example, if you have six master sites, then each site has scheduled links to the other five sites. You typically need one process for each scheduled link. You might also want to add additional job processes for purging the deferred transaction queue and other user-defined jobs.
By the nature of materialized view replication, each materialized view site typically has one scheduled link to the master database and requires at least one job process. Materialized view sites typically require between one and three job processes, depending on purge scheduling, user-defined jobs, and the scheduled link. Also, you need at least one job slave for each degree of parallelism.
Alternatively, if your users are responsible for manually refreshing the materialized view through an application interface, then you do not need to create a scheduled link and your materialized view site requires one less job process.
The job slaves are defined using the JOB_QUEUE_PROCESSES initialization parameter in the initialization parameter file for your database. This initialization parameter is modifiable. Therefore, you can modify it while an instance is running. Oracle automatically determines the interval for job slaves. That is, Oracle determines when the job slaves should "wake up" to execute jobs.
See Also:
"Initialization Parameters" and the Oracle Database Reference for information aboutJOB_QUEUE_PROCESSESCreating a Materialized View Log
Before creating materialized view groups and materialized views for a remote materialized view site, ensure that you create the necessary materialized view logs at the master site or master materialized view site. A materialized view log is necessary for every master table or master materialized view that supports at least one materialized view with fast refreshes.
To create a materialized view log, you need the following privileges:
-
CREATEANYTABLE -
CREATEANYTRIGGER -
SELECT(on the materialized view log's master) -
COMMENTANYTABLE
See Also:
The Advanced Replication interface's online Help for detailed information about creating materialized view logs at the master site or master materialized view site with the Advanced Replication interface in Oracle Enterprise Manager.Logging Columns in the Materialized View Log
When you create a materialized view log, you can add columns to the log when necessary. To perform a fast refresh on a materialized view, the following types of columns must be added to the materialized view log:
-
A column referenced in the
WHEREclause of a subquery that is not part of an equi-join and is not a primary key column. These columns are called filter columns. -
A column in an equi-join that is not a primary key column, if the subquery is either many to many or one to many. If the subquery is many to one, then you do not need to add the join column to the materialized view log.
A collection column cannot be added to a materialized view log. Also, materialized view logs are not required for materialized views that use complete refresh.
For example, consider the following DDL:
1) CREATE MATERIALIZED VIEW oe.customers REFRESH FAST AS 2) SELECT * FROM oe.customers@orc1.example.com c 3) WHERE EXISTS 4) (SELECT * FROM oe.orders@orc1.example.com o 5) WHERE c.customer_id = o.customer_id AND o.order_total > 20000);
Notice in line 5 of the preceding DDL that three columns are referenced in the WHERE clause. Columns orders.customer_id and customers.customer_id are referenced as part of the equi-join clause. Because customers.customer_id is a primary key column, it is logged by default, but orders.customer_id is not a primary key column and so must be added to the materialized view log. Also, the column orders.order_total is an additional filter column and so must be logged.
Therefore, add orders.customer_id and orders.order_total the materialized view log for the oe.orders table.
To create the materialized view log with these columns added, issue the following statement:
CREATE MATERIALIZED VIEW LOG ON oe.orders WITH PRIMARY KEY (customer_id,order_total);
If a materialized view log already exists on the oe.customers table, you can add these columns by issuing the following statement:
ALTER MATERIALIZED VIEW LOG ON oe.orders ADD (customer_id,order_total);
If you are using user-defined data types, then the attributes of column objects can be logged in the materialized view log. For example, the oe.customers table has the cust_address.postal_code attribute, which can be logged in the materialized view log by issuing the following statement:
ALTER MATERIALIZED VIEW LOG ON oe.customers ADD (cust_address.postal_code);
You are encouraged to analyze the defining queries of your planned materialized views and identify which columns must be added to your materialized view logs. If you try to create or refresh a materialized view that requires an added column without adding the column to the materialized view log, then your materialized view creation or refresh might fail.
Note:
To perform a fast refresh on a materialized view, you must add join columns in subqueries to the materialized view log if the join column is not a primary key and the subquery is either many to many or one to many. If the subquery is many to one, then you do not need to add the join column to the materialized view log.See Also:
-
"Data Subsetting with Materialized Views" for information about materialized views with subqueries
-
"Restrictions for Materialized Views with Subqueries" for additional information about materialized views with subqueries
-
"Creating a Materialized View Log" for information about creating a materialized view log
Creating a Materialized View Environment
Materialized view environments can be created in several different ways and from several different locations. In most cases, you should use deployment templates at the master site to locally precreate a materialized view environment that will be individually deployed to the target materialized view site.
You can also individually create the materialized view environment by establishing a connection to the materialized view site and building the materialized view environment directly.
Creating a Materialized View Environment Using the Replication Management Interface
See the Advanced Replication interface's online Help in Oracle Enterprise Manager for information about using deployment templates to centrally create a materialized view environment using the Advanced Replication interface.
See the Advanced Replication interface's online Help in Enterprise Manager for information about individually creating the materialized view environment with a direct connection to the remote materialized view site using the Advanced Replication interface.
Figure 6-2 Flowchart for Creating Materialized Views
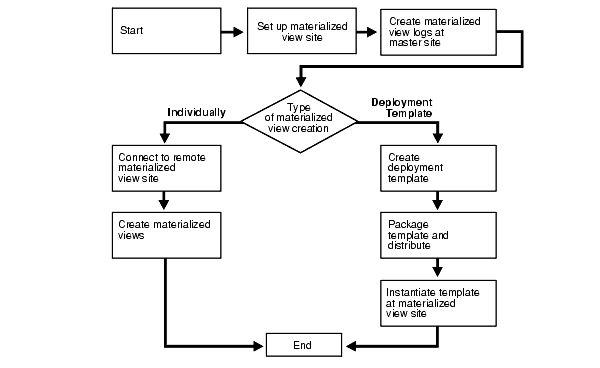
Description of "Figure 6-2 Flowchart for Creating Materialized Views"
Creating a Materialized View Environment Using the Replication Management API
The instructions for creating a deployment template in the Oracle Database Advanced Replication Management API Reference manual for information about using deployment templates to centrally precreate a materialized view environment using the replication management API.
The instructions for creating a materialized view group the Oracle Database Advanced Replication Management API Reference manual for information about individually creating the materialized view environment with a direct connection to the remote materialized view site using the replication management API.
Avoiding Problems When Adding a New Materialized View Site
After you have created a materialized view environment with one or more materialized view sites, you might need to add new materialized view sites. You might encounter problems when you try to perform a fast refresh on the materialized views you create at a new materialized view site if both of the following conditions are true:
-
Materialized views at the new materialized view site and existing materialized views at other materialized view sites are based on the same master table or master materialized view.
-
Existing materialized views can be refreshed while you create the new materialized views at the new materialized view site.
The problem arises when the materialized view logs for the masters are purged before a new materialized view can perform its first fast refresh. If this happens and you try to perform a fast refresh on the materialized views at the new materialized view site, then you might encounter the following errors:
ORA-12004 REFRESH FAST cannot be used for materialized view materialized_view_name ORA-12034 materialized view log on materialized_view_name younger than last refresh
If you receive these errors, then the only solution is to perform a complete refresh of the new materialized view.
To avoid this problem, choose one of the following options:
-
Use deployment templates to create the materialized view environment at materialized view sites. You will not encounter this problem if you use deployment templates.
See Also:
Chapter 4, "Deployment Templates Concepts and Architecture" for information about deployment templates -
Create a dummy materialized view at the new materialized view site before you create your production materialized views. The dummy materialized view ensures that the materialized view log will not be purged while your production materialized views are being created.
If you choose to create a dummy materialized view at the materialized view site, complete the following steps:
-
Create a dummy materialized view called
dummy_mviewbased on the master table or master materialized view. For example, to create a dummy materialized view based on a master table namedsales, issue the following statement at the new materialized view site:CREATE MATERIALIZED VIEW dummy_mview REFRESH FAST AS SELECT * FROM pr.sales@orc1.example.com WHERE 1=0;
-
Create your production materialized views at the new materialized view site.
-
Perform fast refresh of your production materialized views at the new materialized view site.
-
Drop the dummy materialized view.
Interoperability in an Advanced Replication Environment
If you plan to configure an Advanced Replication environment that involves different releases of Oracle Database at different replication sites, then your environment must meet the following requirements:
-
Oracle Database 11g master sites can only interact with Oracle9i Release 2 (9.2) or later master sites.
-
Oracle Database 11g materialized view sites can only interact with Oracle9i Release 2 (9.2) or later master sites.
-
Oracle Database 11g master sites can only interact with Oracle9i Release 2 (9.2) or later materialized view sites.
See Also:
"Replication Support for Unicode" for information about interoperability in Advanced Replication environments that useNCHAR or NVARCHAR2 data typesGuidelines for Scheduled Links
A scheduled link determines how a master site propagates its deferred transaction queue to another master site, or how a materialized view site propagates its deferred transaction queue to its master site or master materialized view site. When you create a scheduled link, Oracle creates a job in the local job queue to push the deferred transaction queue to another site in the system. When Oracle propagates deferred transactions to a remote master site, it does so within the security context of the replication propagator.
You can configure a scheduled link to push information using serial or parallel propagation. In general, you should use parallel propagation, even if you set the parallelism parameter to 1.
Before creating the scheduled links for a replication environment, carefully consider how you want replication to occur globally throughout the system. For example, you can choose to propagate deferred transactions at intervals, with time in between these intervals when the deferred transactions are not propagated. In this case, you must decide how often and when to schedule pushes. Alternatively, to simulate real-time (or synchronous) replication, you might want to have each scheduled link continuously push a master site's deferred transaction queue to its destination.
Also, you might want to schedule pushes at a time of the day when connectivity is guaranteed or when communications costs are lowest, such as during evening hours. Furthermore, you might want to stagger the scheduling for links among all master sites to distribute the load that replication places on network resources.
See Also:
"Serial and Parallel Propagation" for more information about issues related to serial and parallel propagationScheduling Periodic Pushes
You can schedule periodic intervals between pushes of a site's deferred transaction queue to a remote destination. Examples of periodic intervals are once an hour or once a day. To do so, you can use the DBMS_DEFER_SYS.SCHEDULE_PUSH procedure and specify the settings shown in Table 6-3.
Table 6-3 Settings to Schedule Periodic Pushes
| SCHEDULE_PUSH Procedure Parameter | Value |
|---|---|
|
|
0 |
|
|
An appropriate date expression; for example, to specify an interval of one hour, use |
You can also use the Advanced Replication interface in Oracle Enterprise Manager to schedule periodic pushes. To do so, set delay seconds to 0 (zero) when configuring a scheduled link.
Then configure the interval (the "then push every" control) to push the deferred transaction queue periodically.
The following is an example that schedules a periodic push once an hour:
BEGIN
DBMS_DEFER_SYS.SCHEDULE_PUSH (
destination => 'orc2.example.com',
interval => 'SYSDATE + (1/24)',
next_date => SYSDATE,
delay_seconds => 0);
END;
/
See Also:
-
"Delay Seconds" for more information about setting delay seconds
-
Oracle Database Advanced Replication Management API Reference for information about the
DBMS_DEFER_SYS.SCHEDULE_PUSHprocedure -
The Advanced Replication interface online Help for information about using this interface in Enterprise Manager
Scheduling Continuous Pushes
Even when using Oracle's asynchronous replication mechanisms, you can configure a scheduled link to simulate continuous, real-time replication. To do so, use the DBMS_DEFER_SYS.SCHEDULE_PUSH procedure and specify the settings shown in Table 6-4.
Table 6-4 Settings to Simulate Continuous Push
| SCHEDULE_PUSH Procedure Parameter | Value |
|---|---|
|
|
1200 |
|
|
Lower than the |
|
|
1 or higher |
|
|
Higher than the |
With this configuration, Oracle continues to push transactions that enter the deferred transaction queue for the duration of the entire interval. If the deferred transaction queue has no transactions to propagate for the amount of time specified by the delay_seconds parameter, then Oracle releases the resources used by the job and starts fresh when the next job slave becomes available.
If you are using serial propagation by setting the parallelism parameter to 0 (zero), then you can simulate continuous push by reducing the settings of the delay_seconds and interval parameters to an appropriate value for your environment. However, if you are using serial propagation, simulating continuous push is costly when the push job must initiate often.
The following is an example that simulates continual pushes:
BEGIN
DBMS_DEFER_SYS.SCHEDULE_PUSH (
destination => 'orc2.example.com',
interval => 'SYSDATE + (1/144)',
next_date => SYSDATE,
parallelism => 1,
execution_seconds => 1500,
delay_seconds => 1200);
END;
/
See Also:
-
"Delay Seconds" for more information about setting delay seconds
-
"Serial and Parallel Propagation" for more information about issues related to serial and parallel propagation
-
Oracle Database Advanced Replication Management API Reference for information about the
DBMS_DEFER_SYS.SCHEDULE_PUSHprocedure
Guidelines for Scheduled Purges of a Deferred Transaction Queue
A scheduled purge determines how a master site or materialized view site purges applied transactions from its deferred transaction queue. When you use a configuration wizard in the Advanced Replication interface in Oracle Enterprise Manager to set up a master site or materialized view site, Oracle creates a job in each site's local job queue to purge the local deferred transaction queue on a regular basis. Carefully consider how you want purging to occur before configuring the sites in a replication environment. For example, consider the following options:
-
You can synchronize the pushing and purging of a site's deferred transaction queue. For example, you can configure continuous pushing and purging of the transaction queue. This type of configuration can offer performance advantages because it is likely that information about recently pushed transactions is already in the server's buffer cache for the corresponding purge operation.
-
When a server is not CPU bound, you can schedule continuous purging of the deferred transaction queue to keep the size of the queue as small as possible.
-
For servers that experience a high-volume of transaction throughput during normal business hours, you can schedule purges to occur during off-peak hours if you can store an entire day's deferred transactions.
Scheduling Periodic Purges
You can schedule periodic purges of a site's deferred transaction queue. Examples of periodic purges are purges that occur once a day or once a week. To do so, you can use the DBMS_DEFER_SYS.SCHEDULE_PURGE procedure and specify the settings shown in Table 6-5.
Table 6-5 Settings to Schedule Periodic Purges
| SCHEDULE_PURGE Procedure Parameter | Value |
|---|---|
|
|
0 |
|
|
An appropriate date expression; for example, to specify an interval of one day, use |
You can also use the Advanced Replication interface in Oracle Enterprise Manager to schedule periodic purges. To do so, set delay seconds to 0 (zero). Then configure the interval (the "then purge every" control) to purge the deferred transaction queue.
The following is an example that schedules a periodic purge once a day:
BEGIN
DBMS_DEFER_SYS.SCHEDULE_PURGE (
next_date => SYSDATE,
interval => 'SYSDATE + 1',
delay_seconds => 0);
END;
/
See Also:
-
Oracle Database Advanced Replication Management API Reference for information about the
DBMS_DEFER_SYS.SCHEDULE_PURGEprocedure -
The Advanced Replication interface online Help for information about using this interface in Enterprise Manager
Scheduling Continuous Purges
To configure continuous purging of a site's deferred transaction queue, you can use the DBMS_DEFER_SYS.SCHEDULE_PURGE procedure and specify the settings shown in Table 6-6.
Table 6-6 Settings to Schedule Continuous Purges
| SCHEDULE_PURGE Procedure Parameter | Value |
|---|---|
|
|
500000 |
|
|
Lower than the |
|
|
|
You can also use the Advanced Replication interface to configure continuous purge. To do so, on the Purge Schedule page, set Delay Seconds to 500,000 and set interval (the Every field) to a value less than the Delay Seconds setting.
The following is an example that simulates continuous purges:
BEGIN
DBMS_DEFER_SYS.SCHEDULE_PURGE (
next_date => SYSDATE,
interval => 'SYSDATE + (1/144)',
purge_method => dbms_defer_sys.purge_method_quick,
delay_seconds => 500000);
END;
/
See Also:
-
"Delay Seconds" for more information about setting delay seconds
-
Oracle Database Advanced Replication Management API Reference for information about the
DBMS_DEFER_SYS.SCHEDULE_PURGEprocedure -
The Advanced Replication interface online Help for information about using this interface in Enterprise Manager
Serial and Parallel Propagation
When you create the scheduled links for a replication environment, each link can asynchronously propagate changes to a destination using either serial or parallel propagation. Before you configure your replication environment, decide whether you want to use serial propagation or parallel propagation.
-
With serial propagation, Oracle propagates replicated transactions one at a time in the same order that they are committed on the source system. To configure a scheduled link with serial propagation, set the
parallelismparameter to 0 (zero) in theDBMS_DEFER_SYS.SCHEDULE_PUSHprocedure. Or, using the Advanced Replication interface in Oracle Enterprise Manager, set the Propagation Processes control to 0 (zero) in the Edit Push Schedule page. -
With parallel propagation, Oracle propagates replicated transactions using multiple parallel streams for higher throughput. When necessary, Oracle orders the execution of dependent transactions to preserve data integrity. To configure a scheduled link with parallel propagation, set the
parallelismparameter to 1 or higher in theDBMS_DEFER_SYS.SCHEDULE_PUSHprocedure. Or, using the Advanced Replication interface in Oracle Enterprise Manager, set the Propagation Processes control to 1 or higher in the Edit Push Schedule page. Typically, you should use parallel propagation.
See Also:
-
Oracle Database Advanced Replication Management API Reference for information about the
DBMS_DEFER_SYSpackage -
The Advanced Replication interface online Help for information about using this interface in Enterprise Manager
Deployment Templates
If you plan to include materialized view sites in your replication environment, then consider using deployment templates to create the replicated objects at the materialized view sites.
See Also:
Chapter 4, "Deployment Templates Concepts and Architecture" for information about deployment templatesPreparing Materialized View Sites for Instantiation of Deployment Templates
If you decide to use deployment templates, then you must prepare your materialized view sites for instantiation. If a deployment template has been designed well, then little preparation is necessary at the remote materialized view site. This section describes the most common preparations that must be performed at the remote materialized view site. After any required preparations have been completed, you are ready to perform either an online or offline instantiation.
Use the following questions to assess which actions are necessary to prepare the remote materialized view site for instantiation:
-
Does the remote materialized view site have network connectivity to the target master site?
-
Does the materialized view site have an Oracle9i Release 2 (9.2) or later database?
-
Has the remote materialized view site been set up to support materialized view replication?
-
Do the schemas required by the deployment template exist at the materialized view site?
-
If required database links are not part of the deployment template, then do the required database links from the materialized view site to the master site exist?
-
Will you use online instantiation or offline instantiation to instantiate the deployment template at the materialized view sites?
-
Do the rollback segments that might be required by the deployment template exist at the materialized view site and are they online?
The following sections provide guidance for the issues raised by each of these questions.
Network Connectivity
As with all replication environments, network connectivity is a key component in Advanced Replication. Verify that the remote materialized view site has a proper Oracle Net connection to the target master site.
See Also:
Oracle Database Net Services Administrator's Guide for information about setting up an Oracle network connectionDatabase Version
The materialized view site must have an Oracle9i Release 2 (9.2) or later database to work with Oracle Database 11g. If your materialized view site does not meet the database version requirements, then you must upgrade your database at the materialized view site before instantiating a deployment template.
Materialized View Site Setup
Each materialized view site needs several users that have special privileges to support a materialized view site. In addition to having the administrative privileges, these users also participate in the propagation and refreshing of data.
Materialized view site setup also includes scheduling several automated jobs to handle the automatic refreshing of the materialized view (optional) and the purging of the deferred transaction queue.
You can set up your materialized view site with:
-
Advanced Replication Interface: You can connect to the remote materialized view site with the Advanced Replication interface and use the Configure Master and Materialized View Sites for Replication Wizard.
See Also:
The Advanced Replication interface's online Help for instructions on setting up your materialized view site with the Advanced Replication interface in Oracle Enterprise Manager -
Replication Management API: Using the replication management API to setup your materialized view site is an ideal solution when you are not able to connect to the remote materialized view site with the Advanced Replication interface in Enterprise Manager. When you build a SQL script containing the API calls to setup your materialized view site, you can also add the DDL and API calls to complete the remaining preparation (such as creating any necessary schemas, database links, and rollback segments, as described in the following three sections). The script that you create should be distributed with the offline instantiation file and executed before the offline instantiation file.
See Also:
Oracle Database Advanced Replication Management API Reference for instructions on setting up your materialized view site with the replication management API
Create Necessary Schemas
If the deployment template that you are instantiating creates objects in multiple schemas, then ensure that all of the necessary schemas have been created. Additionally, the user instantiating the deployment template must have the appropriate CREATE privileges on that schema. For example, if the deployment template will create a procedure in schema oe and the user hr is instantiating the template, then hr must have the CREATE ANY PROCEDURE privilege on schema oe.
Create Database Links
While it is advantageous to include the DDL to create all necessary database links for a remote materialized view site in the deployment template, it is not required. If the database link DDL is not in the deployment template, then manually create the database links to the target master site before instantiating the deployment template. The database links are required to populate the materialized views during an online instantiation and are required for the proper maintenance of the materialized view environment.
Online or Offline Instantiation
You have the option of performing online or offline instantiation of deployment templates at materialized view sites. With online instantiation, the data in your materialized views is pulled from the master site during instantiation. With offline instantiation, the data in your materialized views is packaged in the template itself and is applied locally when you instantiate the template. In general, if your materialized views will contain a large amount of data, then offline instantiation is preferred to minimize utilization of your network resources.
See Also:
"Deployment Template Packaging and Instantiation" for more information about online and offline instantiationCreate Necessary Rollback Segments
If the deployment template that you are instantiating will use specific rollback segments that do not currently exist at the remote materialized view site, then create the necessary rollback segments. To see if your template objects use the default rollback segment or a specific rollback segment, query the DBA_REPCAT_TEMPLATE_OBJECTS data dictionary view.
See Also:
Oracle Database Advanced Replication Management API Reference for information about data dictionary views related to replicationConflict Resolution
Asynchronous multimaster and updatable materialized view replication environments must address the possibility of replication conflicts that can occur when, for example, two transactions originating from different sites update the same row at nearly the same time. If possible, plan your replication environment to avoid the possibility of conflicts. If data conflicts can occur in your replication environment, then you need a mechanism to ensure that the conflict is resolved in accordance with your business rules and to ensure that the data converges correctly at all sites.
See Also:
Chapter 5, "Conflict Resolution Concepts and Architecture", for more information about avoiding conflicts and for information about the conflict resolution methods available to you if conflicts can occurSecurity and Replication
Security might be a concern in both multimaster and materialized view replication environments. You should plan your security strategy before you configure your replication environment.
See Also:
Oracle Database Advanced Replication Management API Reference for information about security options in a replication environmentDesigning for Survivability
Survivability is the capability to continue running applications despite system or site failures. Survivability enables you to run applications on a fail over system, accessing the same, or very nearly the same, data as these systems accessed on the primary system when it failed. As shown in Figure 6-3, the Oracle server provides two different technologies for accomplishing survivability: multimaster replication and Oracle Real Application Clusters (Oracle RAC).
Figure 6-3 Survivability Methods: Replication Or Oracle Real Application Clusters
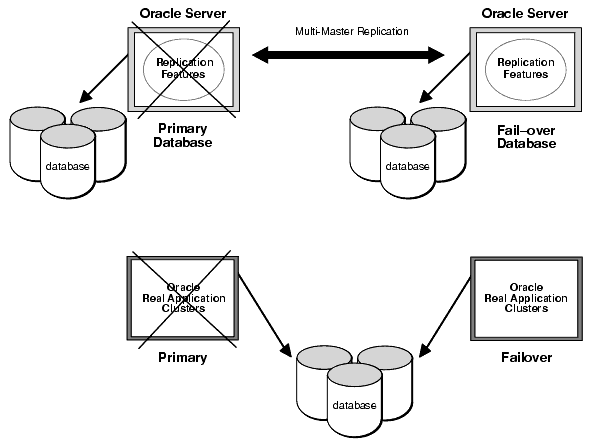
Description of "Figure 6-3 Survivability Methods: Replication Or Oracle Real Application Clusters"
Oracle Real Application Clusters versus Replication
Oracle Real Application Clusters (Oracle RAC) supports fail over to surviving systems when a system supporting an instance of the Oracle server fails. Oracle RAC requires a cluster or massively parallel hardware platform, and thus is applicable for protection against processor system failures in the local environment where the cluster or massively parallel system is running.
In these environments, Oracle RAC is a good solution for survivability — supporting high transaction volumes with no lost transactions or data inconsistencies in the event of an instance failure. If an instance fails in an Oracle RAC environment, then a surviving instance automatically recovers any incomplete transactions. Applications running on the failed system can execute on the fail over system, accessing all data in the database.
Oracle RAC does not, however, provide survivability for site failures (such as power outages, flood, fire, or sabotage) that render an entire site, and thus the entire cluster or massively parallel system, inoperable. To provide survivability for site failures, you can use the multimaster replication to maintain a replica of a database at a geographically remote location. In addition, you can use multimaster replication to replicate data between sites running different operating systems or different releases of Oracle or both.
Should the local system fail, the application can continue to execute at the remote site. Using multimaster replication, some administrative procedures might be necessary to recover transactions at the failed site and to prevent data inconsistencies when restarting the failed site.
Note:
You can also configure standby database to protect an Oracle database from site failures.See Also:
-
Oracle Real Application Clusters Administration and Deployment Guide
-
Oracle Data Guard Concepts and Administration for more information about standby database
Designing a Replication Environment for Survivability
If you choose to use the replication facility for survivability, then consider the following issues:
-
The replication facility must be able to keep up with the transaction volume of the primary system.
-
If a failure occurs at the primary site, then recently committed transactions at the primary site might not have been asynchronously propagated to the failover site yet. These transactions appear to be lost.
These "lost" transactions must be dealt with when the primary site is recovered.
Suppose, for example, you are running an order-entry system that uses replication to maintain a remote fail over order-entry system, and the primary system fails.
At the time of the failure, there were two transactions recently executed at the primary site that did not have their changes propagated and applied at the failover site. The first of these was a transaction that entered a new order, and the second was a transaction that canceled an existing order.
In the first case, someone might notice the absence of the new order when processing continues on the fail over system, and reenter it. In the second case, the cancellation of the order might not be noticed, and processing of the order might proceed; that is, the canceled item might be shipped and the customer billed.
What happens when you restore the primary site? If you simply push all of the changes executed on the failover system back to the primary system, then you will encounter conflicts.
Specifically, duplicate orders exist for the item originally ordered at the primary system just before it failed. Additionally, data changes result from the transactions to ship and bill the order that was originally canceled on the primary system.
You must carefully design your system to deal with these situations. The next section explains this process.
Implementing a Survivable System
Advanced Replication provides survivability against site failures by using multiple replicated master sites. You must configure your system using one of the following methods, which are listed in order of increasing implementation difficulty:
-
The failover site is used for read access only. That is, no updates are allowed at the failover site, even when the primary site fails.
-
After a failure, the primary site is restored from the fail over site using export/import, or through full backup.
-
Full conflict resolution is employed for all data/transactions. This requires careful design and implementation. You must ensure proper resolution of conflicts that can occur when the primary site is restored, such as duplicate transactions.
-
Provide your own special applications-level routines and procedures to deal with the inconsistencies that occur when the primary site is restored, and the queued transactions from the active fail over system are propagated and applied to the primary site.
You can use Oracle Net to configure automatic connect-time failover, which enables Oracle Net to fail over to a different master site if the first master site fails. You configure automatic connect-time failover in your tnsnames.ora file by setting the FAILOVER option to on and specifying multiple connect descriptors.
See Also:
Oracle Database Net Services Administrator's Guide for more information about configuring connect-time failoverDatabase Recovery in Replication Environments
If you recover a database that is a master site in a replication environment, then the replicated data might not be consistent, and you might encounter replication errors. For example, a restored master site might have propagated different transactions to different masters. You might need to perform extra steps to correct for an incorrect recovery operation. One such method is to drop and re-create all replicated objects in the recovered database.
Before dropping and re-creating replicated objects, remove pending deferred transactions and deferred error records from the restored database, and resolve any outstanding distributed transactions. If the restored database was a master definition site for some replication environments, then you should designate a new master definition site before dropping and creating objects. Any materialized views that are mastered at the restored database should be fully refreshed, as well as any materialized views in the restored database.
To provide continued access to your data, you might need to change master definition sites (assuming the database being recovered was the master definition site), or change the master site of materialized view sites (assuming their master site is being recovered).
Performing Checks on Imported Data
After performing an export/import of a replicated object or an object used by Advanced Replication, such as the DBA_REPSITES data dictionary view, you should run the REPCAT_IMPORT_CHECK procedure in the DBMS_REPCAT package.
In the following example, the procedure checks the objects in the hr_repg replication group at a materialized view site to ensure that they have the appropriate object identifiers and status values:
BEGIN
DBMS_REPCAT.REPCAT_IMPORT_CHECK( gname => 'hr_repg',
master => FALSE);
END;
/
See Also:
TheREPCAT_IMPORT_CHECK procedure in Oracle Database Advanced Replication Management API Reference