2 Single-Source Heterogeneous Replication Example
This chapter illustrates an example of a single-source heterogeneous replication environment that can be constructed using Oracle Streams, as well as the tasks required to add new objects and databases to such an environment.
This chapter contains these topics:
-
Overview of the Single-Source Heterogeneous Replication Example
-
Add Objects to an Existing Oracle Streams Replication Environment
-
Add a Database to an Existing Oracle Streams Replication Environment
Overview of the Single-Source Heterogeneous Replication Example
This example illustrates using Oracle Streams to replicate data between four databases. The environment is heterogeneous because three of the databases are Oracle databases and one is a Sybase database. DML and DDL changes made to tables in the hr schema at the dbs1.example.com Oracle database are captured and propagated to the other two Oracle databases. Only DML changes are captured and propagated to the dbs4.example.com database, because an apply process cannot apply DDL changes to a non-Oracle database. Changes to the hr schema occur only at dbs1.example.com. The hr schema is read-only at the other databases in the environment.
Figure 2-1 provides an overview of the environment.
Figure 2-1 Sample Environment that Shares Data from a Single Source Database
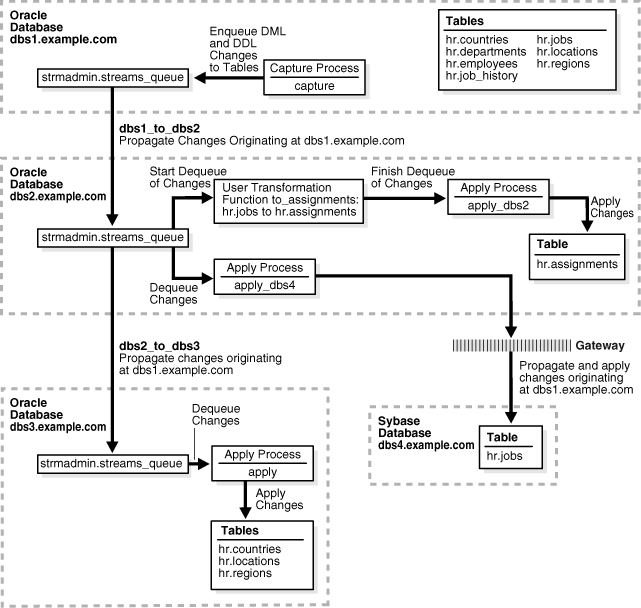
Description of "Figure 2-1 Sample Environment that Shares Data from a Single Source Database"
As illustrated in Figure 2-1, dbs1.example.com contains the following tables in the hr schema:
-
countries -
departments -
employees -
job_history -
jobs -
locations -
regions
This example uses directed networks, which means that captured changes at a source database are propagated to another database through one or more intermediate databases. Here, the dbs1.example.com database propagates changes to the dbs3.example.com database through the intermediate database dbs2.example.com. This configuration is an example of queue forwarding in a directed network. Also, the dbs1.example.com database propagates changes to the dbs2.example.com database, which applies the changes directly to the dbs4.example.com database through an Oracle Database Gateway.
Some of the databases in the environment do not have certain tables. If the database is not an intermediate database for a table and the database does not contain the table, then changes to the table do not need to be propagated to that database. For example, the departments, employees, job_history, and jobs tables do not exist at dbs3.example.com. Therefore, dbs2.example.com does not propagate changes to these tables to dbs3.example.com.
In this example, Oracle Streams is used to perform the following series of actions:
-
The capture process captures DML and DDL changes for all of the tables in the
hrschema and enqueues them at thedbs1.example.comdatabase. In this example, changes to only four of the seven tables are propagated to destination databases, but in the example that illustrates "Add Objects to an Existing Oracle Streams Replication Environment", the remaining tables in thehrschema are added to a destination database. -
The
dbs1.example.comdatabase propagates these changes in the form of messages to a queue atdbs2.example.com. -
At
dbs2.example.com, DML changes to thejobstable are transformed into DML changes for theassignmentstable (which is a direct mapping ofjobs) and then applied. Changes to other tables in thehrschema are not applied atdbs2.example.com. -
Because the queue at
dbs3.example.comreceives changes from the queue atdbs2.example.comthat originated incountries,locations, andregionstables atdbs1.example.com, these changes are propagated fromdbs2.example.comtodbs3.example.com. This configuration is an example of directed networks. -
The apply process at
dbs3.example.comapplies changes to thecountries,locations, andregionstables. -
Because
dbs4.example.com, a Sybase database, receives changes from the queue atdbs2.example.comto thejobstable that originated atdbs1.example.com, these changes are applied remotely fromdbs2.example.comusing thedbs4.example.comdatabase link through an Oracle Database Gateway. This configuration is an example of heterogeneous support.
Prerequisites
The following prerequisites must be completed before you begin the example in this chapter.
-
Set the following initialization parameters to the values indicated for all databases in the environment:
-
GLOBAL_NAMES: This parameter must be set toTRUEat each database that is participating in your Oracle Streams environment. -
COMPATIBLE: This parameter must be set to10.2.0or higher. -
STREAMS_POOL_SIZE: Optionally set this parameter to an appropriate value for each database in the environment. This parameter specifies the size of the Oracle Streams pool. The Oracle Streams pool stores messages in a buffered queue and is used for internal communications during parallel capture and apply. When theMEMORY_TARGET,MEMORY_MAX_TARGET, orSGA_TARGETinitialization parameter is set to a nonzero value, the Oracle Streams pool size is managed automatically.
See Also:
Oracle Streams Replication Administrator's Guide for information about other initialization parameters that are important in an Oracle Streams environment -
-
Any database producing changes that will be captured must be running in
ARCHIVELOGmode. In this example, changes are produced atdbs1.example.com, and sodbs1.example.commust be running inARCHIVELOGmode.See Also:
Oracle Database Administrator's Guide for information about running a database inARCHIVELOGmode -
Configure an Oracle Database Gateway on
dbs2.example.comto communicate with the Sybase databasedbs4.example.com. -
At the Sybase database
dbs4.example.com, set up thehruser.See Also:
Your Sybase documentation for information about creating users and tables in your Sybase database -
Instantiate the
hr.jobstable from thedbs1.example.comOracle database at thedbs4.example.comSybase database. -
Configure your network and Oracle Net so that the following databases can communicate with each other:
-
dbs1.example.comanddbs2.example.com -
dbs2.example.comanddbs3.example.com -
dbs2.example.comanddbs4.example.com -
dbs3.example.comanddbs1.example.com(for optional Data Pump network instantiation)
-
-
Create an Oracle Streams administrator at each Oracle database in the replication environment. In this example, the databases are
dbs1.example.com,dbs2.example.com, anddbs3.example.com. This example assumes that the user name of the Oracle Streams administrator isstrmadmin.See Also:
Oracle Streams Replication Administrator's Guide for instructions about creating an Oracle Streams administrator
Create Queues and Database Links
Complete the following steps to create queues and database links for an Oracle Streams replication environment that includes three Oracle databases and one Sybase database:
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
- Step 1 Show Output and Spool Results
-
Run
SETECHOONand specify the spool file for the script. Check the spool file for errors after you run this script.*/ SET ECHO ON SPOOL streams_setup_single.out /*
- Step 2 Create the ANYDATA Queue at dbs1.example.com
-
Connect as the Oracle Streams administrator at the database where you want to capture changes. In this example, that database is
dbs1.example.com.*/ CONNECT strmadmin@dbs1.example.com /*
Run the
SET_UP_QUEUEprocedure to create a queue namedstreams_queueatdbs1.example.com. This queue will function as theANYDATAqueue by holding the captured changes that will be propagated to other databases.Running the
SET_UP_QUEUEprocedure performs the following actions:-
Creates a queue table named
streams_queue_table. This queue table is owned by the Oracle Streams administrator (strmadmin) and uses the default storage of this user. -
Creates a queue named
streams_queueowned by the Oracle Streams administrator (strmadmin). -
Starts the queue.
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
-
- Step 3 Create the Database Link at dbs1.example.com
-
Create the database link from the database where changes are captured to the database where changes are propagated. In this example, the database where changes are captured is
dbs1.example.com, and these changes are propagated todbs2.example.com.*/ ACCEPT password PROMPT 'Enter password for user: ' HIDE CREATE DATABASE LINK dbs2.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs2.example.com'; /*
- Step 4 Create the ANYDATA Queue at dbs2.example.com
-
Connect as the Oracle Streams administrator at
dbs2.example.com.*/ CONNECT strmadmin@dbs2.example.com /*
Run the
SET_UP_QUEUEprocedure to create a queue namedstreams_queueatdbs2.example.com. This queue will function as theANYDATAqueue by holding the changes that will be applied at this database and the changes that will be propagated to other databases.Running the
SET_UP_QUEUEprocedure performs the following actions:-
Creates a queue table named
streams_queue_table. This queue table is owned by the Oracle Streams administrator (strmadmin) and uses the default storage of this user. -
Creates a queue named
streams_queueowned by the Oracle Streams administrator (strmadmin). -
Starts the queue.
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
-
- Step 5 Create the Database Links at dbs2.example.com
-
Create the database links to the databases where changes are propagated. In this example, database
dbs2.example.compropagates changes todbs3.example.com, which is another Oracle database, and todbs4.example.com, which is a Sybase database. Notice that the database link to the Sybase database connects to the owner of the tables, not to the Oracle Streams administrator. This database link can connect to any user atdbs4.example.comthat has privileges to change thehr.jobstable at that database.Note:
On some non-Oracle databases, including Sybase, you must ensure that the characters in the user name and password are in the correct case. Therefore, double quotation marks are specified for the user name and password at the Sybase database.*/ CREATE DATABASE LINK dbs3.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs3.example.com'; CREATE DATABASE LINK dbs4.example.com CONNECT TO "hr" IDENTIFIED BY "&password" USING 'dbs4.example.com'; /*
- Step 6 Create the hr.assignments Table at dbs2.example.com
-
This example illustrates a custom rule-based transformation in which changes to the
hr.jobstable atdbs1.example.comare transformed into changes to thehr.assignmentstable atdbs2.example.com. You must create thehr.assignmentstable ondbs2.example.comfor the transformation portion of this example to work properly.Note:
Instead of using a custom rule-based transformation to change the name of the table, you can use aRENAME_TABLEdeclarative rule-based transformation. See Oracle Streams Concepts and Administration.Connect as hr at
dbs2.example.com.*/ CONNECT hr@dbs2.example.com /*
Create the
hr.assignmentstable in thedbs2.example.comdatabase.*/ CREATE TABLE hr.assignments AS SELECT * FROM hr.jobs; ALTER TABLE hr.assignments ADD PRIMARY KEY (job_id); /*
- Step 7 Create the ANYDATA Queue at dbs3.example.com
-
Connect as the Oracle Streams administrator at
dbs3.example.com.*/ CONNECT strmadmin@dbs3.example.com /*
Run the
SET_UP_QUEUEprocedure to create a queue namedstreams_queueatdbs3.example.com. This queue will function as theANYDATAqueue by holding the changes that will be applied at this database.Running the
SET_UP_QUEUEprocedure performs the following actions:-
Creates a queue table named
streams_queue_table. This queue table is owned by the Oracle Streams administrator (strmadmin) and uses the default storage of this user. -
Creates a queue named
streams_queueowned by the Oracle Streams administrator (strmadmin). -
Starts the queue.
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
-
- Step 8 Create a Database Link at dbs3.example.com to dbs1.example.com
-
Create a database link from
dbs3.example.comtodbs1.example.com. Later in this example, this database link is used for the instantiation of some of the database objects that were dropped in Step 9. This example uses theDBMS_DATAPUMPpackage to perform a network import of these database objects directly from thedbs1.example.comdatabase. Because this example performs a network import, no dump file is required.Alternatively, you can perform an export at the source database
dbs1.example.com, transfer the export dump file to the destination databasedbs3.example.com, and then import the export dump file at the destination database. In this case, the database link created in this step is not required.*/ CREATE DATABASE LINK dbs1.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs1.example.com'; /*
- Step 9 Drop All of the Tables in the hr Schema at dbs3.example.com
-
This example illustrates instantiating tables in the
hrschema by importing them fromdbs1.example.comintodbs3.example.comwith Data Pump. You must delete these tables atdbs3.example.comfor the instantiation portion of this example to work properly.Connect as
hratdbs3.example.com.*/ CONNECT hr@dbs3.example.com /*
Drop all tables in the
hrschema in thedbs3.example.comdatabase.Note:
If you complete this step and drop all of the tables in thehrschema, then you should complete the remaining sections of this example to reinstantiate thehrschema atdbs3.example.com. If thehrschema does not exist in an Oracle database, then some examples in the Oracle documentation set can fail.*/ DROP TABLE hr.countries CASCADE CONSTRAINTS; DROP TABLE hr.departments CASCADE CONSTRAINTS; DROP TABLE hr.employees CASCADE CONSTRAINTS; DROP TABLE hr.job_history CASCADE CONSTRAINTS; DROP TABLE hr.jobs CASCADE CONSTRAINTS; DROP TABLE hr.locations CASCADE CONSTRAINTS; DROP TABLE hr.regions CASCADE CONSTRAINTS; /*
- Step 10 Check the Spool Results
-
Check the
streams_setup_single.outspool file to ensure that all actions finished successfully after this script is completed.*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
Example Scripts for Sharing Data from One Database
This example illustrates two ways to accomplish the replication of the tables in the hr schema using Oracle Streams.
-
"Simple Configuration for Sharing Data from a Single Database" demonstrates a simple way to configure the environment. This example uses the
DBMS_STREAMS_ADMpackage to create a capture process, propagations, and apply processes, as well as the rule sets associated with them. Using theDBMS_STREAMS_ADMpackage is the simplest way to configure an Oracle Streams environment. -
"Flexible Configuration for Sharing Data from a Single Database" demonstrates a more flexible way to configure this environment. This example uses the
DBMS_CAPTURE_ADMpackage to create a capture process, theDBMS_PROPAGATION_ADMpackage to create propagations, and theDBMS_APPLY_ADMpackage to create apply processes. Also, this example uses theDBMS_RULES_ADMpackage to create and populate the rule sets associated with these capture processes, propagations, and apply processes. Using these packages, instead of theDBMS_STREAMS_ADMpackage, provides more configuration options and flexibility.Note:
These examples illustrate two different ways to configure the same Oracle Streams environment. Therefore, you should run only one of the examples for a particular distributed database system. Otherwise, errors stating that objects already exist will result.
Simple Configuration for Sharing Data from a Single Database
Complete the following steps to specify the capture, propagation, and apply definitions using primarily the DBMS_STEAMS_ADM package.
-
Set the Instantiation SCN for the Existing Tables at Other Databases
-
Specify hr as the Apply User for the Apply Process at dbs3.example.com
-
Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Create the Custom Rule-Based Transformation for Row LCRs at dbs2.example.com
-
Configure the Apply Process for Local Apply at dbs2.example.com
-
Specify hr as the Apply User for the Apply Process at dbs2.example.com
-
Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Configure the Apply Process at dbs2.example.com for Apply at dbs4.example.com
-
Start the Apply Process at dbs2.example.com for Apply at dbs4.example.com
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
- Step 1 Show Output and Spool Results
-
Run
SETECHOONand specify the spool file for the script. Check the spool file for errors after you run this script.*/ SET ECHO ON SPOOL streams_share_schema1.out /*
- Step 2 Configure Propagation at dbs1.example.com
-
Connect to
dbs1.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs1.example.com /*
Configure and schedule propagation of DML and DDL changes in the
hrschema from the queue atdbs1.example.comto the queue atdbs2.example.com.*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'dbs1_to_dbs2', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs2.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE, queue_to_queue => TRUE); END; / /* - Step 3 Configure the Capture Process at dbs1.example.com
-
Configure the capture process to capture changes to the entire
hrschema atdbs1.example.com. This step specifies that changes to the tables in the specified schema are captured by the capture process and enqueued into the specified queue.This step also prepares the
hrschema for instantiation and enables supplemental logging for any primary key, unique key, bitmap index, and foreign key columns in the tables in this schema. Supplemental logging places additional information in the redo log for changes made to tables. The apply process needs this extra information to perform certain operations, such as unique row identification and conflict resolution. Becausedbs1.example.comis the only database where changes are captured in this environment, it is the only database where you must specify supplemental logging for the tables in thehrschema.*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'capture', streams_name => 'capture', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, inclusion_rule => TRUE); END; / /* - Step 4 Set the Instantiation SCN for the Existing Tables at Other Databases
-
In this example, the
hr.jobstable already exists atdbs2.example.comanddbs4.example.com. Atdbs2.example.com, this table is namedassignments, but it has the same shape and data as thejobstable atdbs1.example.com. Also, in this example,dbs4.example.comis a Sybase database. All of the other tables in the Oracle Streams environment are instantiated at the other destination databases using Data Pump import.Because the
hr.jobstable already exists atdbs2.example.comanddbs4.example.com, this example uses theGET_SYSTEM_CHANGE_NUMBERfunction in theDBMS_FLASHBACKpackage atdbs1.example.comto obtain the current SCN for the database. This SCN is used atdbs2.example.comto run theSET_TABLE_INSTANTIATION_SCNprocedure in theDBMS_APPLY_ADMpackage. Running this procedure twice sets the instantiation SCN for thehr.jobstable atdbs2.example.comanddbs4.example.com.The
SET_TABLE_INSTANTIATION_SCNprocedure controls which LCRs for a table are ignored by an apply process and which LCRs for a table are applied by an apply process. If the commit SCN of an LCR for a table from a source database is less than or equal to the instantiation SCN for that table at a destination database, then the apply process at the destination database discards the LCR. Otherwise, the apply process applies the LCR.In this example, both of the apply processes at
dbs2.example.comwill apply transactions to thehr.jobstable with SCNs that were committed after SCN obtained in this step.Note:
This example assumes that the contents of thehr.jobstable atdbs1.example.com,dbs2.example.com(ashr.assignments), anddbs4.example.comare consistent when you complete this step. You might want to lock the table at each database while you complete this step to ensure consistency.*/ DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM( source_object_name => 'hr.jobs', source_database_name => 'dbs1.example.com', instantiation_scn => iscn); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM( source_object_name => 'hr.jobs', source_database_name => 'dbs1.example.com', instantiation_scn => iscn, apply_database_link => 'dbs4.example.com'); END; / /* - Step 5 Instantiate the dbs1.example.com Tables at dbs3.example.com
-
This example performs a network Data Pump import of the following tables:
-
hr.countries -
hr.locations -
hr.regions
A network import means that Data Pump imports these tables from
dbs1.example.comwithout using an export dump file.See Also:
Oracle Database Utilities for information about performing an importConnect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
This example will do a table import using the
DBMS_DATAPUMPpackage. For simplicity, exceptions from any of the API calls will not be trapped. However, Oracle recommends that you define exception handlers and callGET_STATUSto retrieve more detailed error information if a failure occurs. If you want to monitor the import, then query theDBA_DATAPUMP_JOBSdata dictionary view at the import database.*/ SET SERVEROUTPUT ON DECLARE h1 NUMBER; -- Data Pump job handle sscn NUMBER; -- Variable to hold current source SCN job_state VARCHAR2(30); -- To keep track of job state js ku$_JobStatus; -- The job status from GET_STATUS sts ku$_Status; -- The status object returned by GET_STATUS job_not_exist exception; pragma exception_init(job_not_exist, -31626); BEGIN -- Create a (user-named) Data Pump job to do a table-level import. h1 := DBMS_DATAPUMP.OPEN( operation => 'IMPORT', job_mode => 'TABLE', remote_link => 'DBS1.EXAMPLE.COM', job_name => 'dp_sing1'); -- A metadata filter is used to specify the schema that owns the tables -- that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'SCHEMA_EXPR', value => '=''HR'''); -- A metadata filter is used to specify the tables that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'NAME_EXPR', value => 'IN(''COUNTRIES'', ''REGIONS'', ''LOCATIONS'')'); -- Get the current SCN of the source database, and set the FLASHBACK_SCN -- parameter to this value to ensure consistency between all of the -- objects included in the import. sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com(); DBMS_DATAPUMP.SET_PARAMETER( handle => h1, name => 'FLASHBACK_SCN', value => sscn); -- Start the job. DBMS_DATAPUMP.START_JOB(h1); -- The import job should be running. In the following loop, the job -- is monitored until it completes. job_state := 'UNDEFINED'; BEGIN WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP sts:=DBMS_DATAPUMP.GET_STATUS( handle => h1, mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR + DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS + DBMS_DATAPUMP.KU$_STATUS_WIP, timeout => -1); js := sts.job_status; DBMS_LOCK.SLEEP(10); job_state := js.state; END LOOP; -- Gets an exception when job no longer exists EXCEPTION WHEN job_not_exist THEN DBMS_OUTPUT.PUT_LINE('Data Pump job has completed'); DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn); END; END; / /* -
- Step 6 Configure the Apply Process at dbs3.example.com
-
Connect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
Configure
dbs3.example.comto apply changes to thecountriestable,locationstable, andregionstable.*/ BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.countries', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.locations', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.regions', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / /* - Step 7 Specify hr as the Apply User for the Apply Process at dbs3.example.com
-
In this example, the
hruser owns all of the database objects for which changes are applied by the apply process at this database. Therefore,hralready has the necessary privileges to change these database objects, and it is convenient to makehrthe apply user.When the apply process was created in the previous step, the Oracle Streams administrator
strmadminwas specified as the apply user by default, becausestrmadminran the procedure that created the apply process. Instead of specifying hr as the apply user, you could retainstrmadminas the apply user, but then you must grantstrmadminprivileges on all of the database objects for which changes are applied and privileges to execute all user procedures used by the apply process. In an environment where an apply process applies changes to database objects in multiple schemas, it might be more convenient to use the Oracle Streams administrator as the apply user.See Also:
Oracle Streams Replication Administrator's Guide for more information about configuring an Oracle Streams administrator*/ BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply', apply_user => 'hr'); END; / /* - Step 8 Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Because the
hruser was specified as the apply user in the previous step, thehruser requiresEXECUTEprivilege on the positive rule set used by the apply process*/ DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / /* - Step 9 Start the Apply Process at dbs3.example.com
-
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start the apply process atdbs3.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply'); END; / /* - Step 10 Configure Propagation at dbs2.example.com
-
Connect to
dbs2.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs2.example.com /*
Configure and schedule propagation from the queue at
dbs2.example.comto the queue atdbs3.example.com. You must specify this propagation for each table that will apply changes atdbs3.example.com. This configuration is an example of directed networks because the changes atdbs2.example.comoriginated atdbs1.example.com.*/ BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.countries', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE, queue_to_queue => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.locations', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.regions', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / /* - Step 11 Create the Custom Rule-Based Transformation for Row LCRs at dbs2.example.com
-
Connect to
dbs2.example.comas thehruser.*/ CONNECT hr@dbs2.example.com /*
Create the custom rule-based transformation function that transforms row changes resulting from DML statements to the
jobstable fromdbs1.example.cominto row changes to theassignmentstable ondbs2.example.com.The following function transforms every row LCR for the
jobstable into a row LCR for theassignmentstable.Note:
If DDL changes were also applied to theassignmentstable, then another transformation would be required for the DDL LCRs. This transformation would need to change the object name and the DDL text.*/ CREATE OR REPLACE FUNCTION hr.to_assignments_trans_dml( p_in_data in ANYDATA) RETURN ANYDATA IS out_data SYS.LCR$_ROW_RECORD; tc pls_integer; BEGIN -- Typecast AnyData to LCR$_ROW_RECORD tc := p_in_data.GetObject(out_data); IF out_data.GET_OBJECT_NAME() = 'JOBS' THEN -- Transform the in_data into the out_data out_data.SET_OBJECT_NAME('ASSIGNMENTS'); END IF; -- Convert to AnyData RETURN ANYDATA.ConvertObject(out_data); END; / /* - Step 12 Configure the Apply Process for Local Apply at dbs2.example.com
-
Connect to
dbs2.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs2.example.com /*
Configure
dbs2.example.comto apply changes to theassignmentstable. Remember that theassignmentstable receives changes from thejobstable atdbs1.example.com.*/ DECLARE to_assignments_rulename_dml VARCHAR2(30); dummy_rule VARCHAR2(30); BEGIN -- DML changes to the jobs table from dbs1.example.com are applied -- to the assignments table. The to_assignments_rulename_dml variable -- is an out parameter in this call. DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.jobs', -- jobs, not assignments, specified streams_type => 'apply', streams_name => 'apply_dbs2', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => FALSE, source_database => 'dbs1.example.com', dml_rule_name => to_assignments_rulename_dml, ddl_rule_name => dummy_rule, inclusion_rule => TRUE); -- Modify the rule for the hr.jobs table to use the transformation function. DBMS_STREAMS_ADM.SET_RULE_TRANSFORM_FUNCTION( rule_name => to_assignments_rulename_dml, transform_function => 'hr.to_assignments_trans_dml'); END; / /* - Step 13 Specify hr as the Apply User for the Apply Process at dbs2.example.com
-
In this example, the
hruser owns all of the database objects for which changes are applied by the apply process at this database. Therefore,hralready has the necessary privileges to change these database objects, and it is convenient to makehrthe apply user.When the apply process was created in the previous step, the Oracle Streams administrator
strmadminwas specified as the apply user by default, becausestrmadminran the procedure that created the apply process. Instead of specifying hr as the apply user, you could retainstrmadminas the apply user, but then you must grantstrmadminprivileges on all of the database objects for which changes are applied and privileges to execute all user procedures used by the apply process. In an environment where an apply process applies changes to database objects in multiple schemas, it might be more convenient to use the Oracle Streams administrator as the apply user.See Also:
Oracle Streams Replication Administrator's Guide for more information about configuring an Oracle Streams administrator*/ BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_dbs2', apply_user => 'hr'); END; / /* - Step 14 Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Because the
hruser was specified as the apply user in the previous step, thehruser requiresEXECUTEprivilege on the positive rule set used by the apply process*/ DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_DBS2'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / /* - Step 15 Start the Apply Process at dbs2.example.com for Local Apply
-
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start the apply process for local apply atdbs2.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_dbs2', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_dbs2'); END; / /* - Step 16 Configure the Apply Process at dbs2.example.com for Apply at dbs4.example.com
-
Configure the apply process for
dbs4.example.com, which is a Sybase database. Thedbs2.example.comdatabase is acting as a gateway todbs4.example.com. Therefore, the apply process fordbs4.example.commust be configured atdbs2.example.com. The apply process cannot apply DDL changes to non-Oracle databases. Therefore, theinclude_ddlparameter is set toFALSEwhen theADD_TABLE_RULESprocedure is run.*/ BEGIN DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.streams_queue', apply_name => 'apply_dbs4', apply_database_link => 'dbs4.example.com', apply_captured => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.jobs', streams_type => 'apply', streams_name => 'apply_dbs4', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => FALSE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / /* - Step 17 Start the Apply Process at dbs2.example.com for Apply at dbs4.example.com
-
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start the remote apply for Sybase using database linkdbs4.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_dbs4', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_dbs4'); END; / /* - Step 18 Start the Capture Process at dbs1.example.com
-
Connect to
dbs1.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs1.example.com /*
Start the capture process at
dbs1.example.com.*/ BEGIN DBMS_CAPTURE_ADM.START_CAPTURE( capture_name => 'capture'); END; / /* - Step 19 Check the Spool Results
-
Check the
streams_share_schema1.outspool file to ensure that all actions finished successfully after this script is completed.*/ SET ECHO OFF SPOOL OFF /*
You can now make DML and DDL changes to specific tables at
dbs1.example.comand see these changes replicated to the other databases in the environment based on the rules you configured for the Oracle Streams processes and propagations in this environment.See Also:
"Make DML and DDL Changes to Tables in the hr Schema" for examples of changes that are replicated in this environment/*************************** END OF SCRIPT ******************************/
Flexible Configuration for Sharing Data from a Single Database
Complete the following steps to use a more flexible approach for specifying the capture, propagation, and apply definitions. This approach does not use the DBMS_STREAMS_ADM package. Instead, it uses the following packages:
-
The
DBMS_CAPTURE_ADMpackage to configure capture processes -
The
DBMS_PROPAGATION_ADMpackage to configure propagations -
The
DBMS_APPLY_ADMpackage to configure apply processes -
The
DBMS_RULES_ADMpackage to specify capture process, propagation, and apply process rules and rule setsNote:
Neither theALL_STREAMS_TABLE_RULESnor theDBA_STREAMS_TABLE_RULESdata dictionary view is populated by the rules created in this example. To view the rules created in this example, you can query theALL_STREAMS_RULESorDBA_STREAMS_RULESdata dictionary view.
This example includes the following steps:
-
Set the Instantiation SCN for the Existing Tables at Other Databases
-
Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Create the Custom Rule-Based Transformation for Row LCRs at dbs2.example.com
-
Configure the Apply Process for Local Apply at dbs2.example.com
-
Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Configure the Apply Process at dbs2.example.com for Apply at dbs4.example.com
-
Start the Apply Process at dbs2.example.com for Apply at dbs4.example.com
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
- Step 1 Show Output and Spool Results
-
Run
SETECHOONand specify the spool file for the script. Check the spool file for errors after you run this script.*/ SET ECHO ON SPOOL streams_share_schema2.out /*
- Step 2 Configure Propagation at dbs1.example.com
-
Connect to
dbs1.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs1.example.com /*
Configure and schedule propagation from the queue at
dbs1.example.comto the queue atdbs2.example.com. This configuration specifies that the propagation propagates all changes to thehrschema. You have the option of omitting the rule set specification, but then everything in the queue will be propagated, which might not be desired if, in the future, multiple capture processes will use thestreams_queue.*/ BEGIN -- Create the rule set DBMS_RULE_ADM.CREATE_RULE_SET( rule_set_name => 'strmadmin.propagation_dbs1_rules', evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT'); -- Create rules for all modifications to the hr schema DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_hr_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_hr_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Add rules to rule set DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_hr_dml', rule_set_name => 'strmadmin.propagation_dbs1_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_hr_ddl', rule_set_name => 'strmadmin.propagation_dbs1_rules'); -- Create a propagation that uses the rule set as its positive rule set DBMS_PROPAGATION_ADM.CREATE_PROPAGATION( propagation_name => 'dbs1_to_dbs2', source_queue => 'strmadmin.streams_queue', destination_queue => 'strmadmin.streams_queue', destination_dblink => 'dbs2.example.com', rule_set_name => 'strmadmin.propagation_dbs1_rules'); END; / /* - Step 3 Configure the Capture Process at dbs1.example.com
-
Create a capture process and rules to capture the entire
hrschema atdbs1.example.com.*/ BEGIN -- Create the rule set DBMS_RULE_ADM.CREATE_RULE_SET( rule_set_name => 'strmadmin.demo_rules', evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT'); -- Create rules that specify the entire hr schema DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.schema_hr_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.schema_hr_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Add the rules to the rule set DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.schema_hr_dml', rule_set_name => 'strmadmin.demo_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.schema_hr_ddl', rule_set_name => 'strmadmin.demo_rules'); -- Create a capture process that uses the rule set as its positive rule set DBMS_CAPTURE_ADM.CREATE_CAPTURE( queue_name => 'strmadmin.streams_queue', capture_name => 'capture', rule_set_name => 'strmadmin.demo_rules'); END; / /* - Step 4 Prepare the hr Schema at dbs1.example.com for Instantiation
-
While still connected as the Oracle Streams administrator at
dbs1.example.com, prepare thehrschema atdbs1.example.comfor instantiation atdbs3.example.com. This step marks the lowest SCN of the tables in the schema for instantiation. SCNs subsequent to the lowest SCN can be used for instantiation.This step also enables supplemental logging for any primary key, unique key, bitmap index, and foreign key columns in the tables in the
hrschema. Supplemental logging places additional information in the redo log for changes made to tables. The apply process needs this extra information to perform certain operations, such as unique row identification and conflict resolution. Becausedbs1.example.comis the only database where changes are captured in this environment, it is the only database where you must specify supplemental logging for the tables in thehrschema.Note:
This step is not required in the "Simple Configuration for Sharing Data from a Single Database". In that example, when theADD_SCHEMA_RULESprocedure in theDBMS_STREAMS_ADMpackage is run in Step 3, thePREPARE_SCHEMA_INSTANTIATIONprocedure in theDBMS_CAPTURE_ADMpackage is run automatically for thehrschema.*/ BEGIN DBMS_CAPTURE_ADM.PREPARE_SCHEMA_INSTANTIATION( schema_name => 'hr', supplemental_logging => 'keys'); END; / /* - Step 5 Set the Instantiation SCN for the Existing Tables at Other Databases
-
In this example, the
hr.jobstable already exists atdbs2.example.comanddbs4.example.com. Atdbs2.example.com, this table is namedassignments, but it has the same shape and data as thejobstable atdbs1.example.com. Also, in this example,dbs4.example.comis a Sybase database. All of the other tables in the Oracle Streams environment are instantiated at the other destination databases using Data Pump import.Because the
hr.jobstable already exists atdbs2.example.comanddbs4.example.com, this example uses theGET_SYSTEM_CHANGE_NUMBERfunction in theDBMS_FLASHBACKpackage atdbs1.example.comto obtain the current SCN for the database. This SCN is used atdbs2.example.comto run theSET_TABLE_INSTANTIATION_SCNprocedure in theDBMS_APPLY_ADMpackage. Running this procedure twice sets the instantiation SCN for thehr.jobstable atdbs2.example.comanddbs4.example.com.The
SET_TABLE_INSTANTIATION_SCNprocedure controls which LCRs for a table are ignored by an apply process and which LCRs for a table are applied by an apply process. If the commit SCN of an LCR for a table from a source database is less than or equal to the instantiation SCN for that table at a destination database, then the apply process at the destination database discards the LCR. Otherwise, the apply process applies the LCR.In this example, both of the apply processes at
dbs2.example.comwill apply transactions to thehr.jobstable with SCNs that were committed after SCN obtained in this step.Note:
This example assumes that the contents of thehr.jobstable atdbs1.example.com,dbs2.example.com(ashr.assignments), anddbs4.example.comare consistent when you complete this step. You might want to lock the table at each database while you complete this step to ensure consistency.*/ DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM( source_object_name => 'hr.jobs', source_database_name => 'dbs1.example.com', instantiation_scn => iscn); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@DBS2.EXAMPLE.COM( source_object_name => 'hr.jobs', source_database_name => 'dbs1.example.com', instantiation_scn => iscn, apply_database_link => 'dbs4.example.com'); END; //*
- Step 6 Instantiate the dbs1.example.com Tables at dbs3.example.com
-
This example performs a network Data Pump import of the following tables:
-
hr.countries -
hr.locations -
hr.regions
A network import means that Data Pump imports these tables from
dbs1.example.comwithout using an export dump file.See Also:
Oracle Database Utilities for information about performing an importConnect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
This example will do a table import using the
DBMS_DATAPUMPpackage. For simplicity, exceptions from any of the API calls will not be trapped. However, Oracle recommends that you define exception handlers and callGET_STATUSto retrieve more detailed error information if a failure occurs. If you want to monitor the import, then query theDBA_DATAPUMP_JOBSdata dictionary view at the import database.*/ SET SERVEROUTPUT ON DECLARE h1 NUMBER; -- Data Pump job handle sscn NUMBER; -- Variable to hold current source SCN job_state VARCHAR2(30); -- To keep track of job state js ku$_JobStatus; -- The job status from GET_STATUS sts ku$_Status; -- The status object returned by GET_STATUS job_not_exist exception; pragma exception_init(job_not_exist, -31626); BEGIN -- Create a (user-named) Data Pump job to do a table-level import. h1 := DBMS_DATAPUMP.OPEN( operation => 'IMPORT', job_mode => 'TABLE', remote_link => 'DBS1.EXAMPLE.COM', job_name => 'dp_sing2'); -- A metadata filter is used to specify the schema that owns the tables -- that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'SCHEMA_EXPR', value => '=''HR'''); -- A metadata filter is used to specify the tables that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'NAME_EXPR', value => 'IN(''COUNTRIES'', ''REGIONS'', ''LOCATIONS'')'); -- Get the current SCN of the source database, and set the FLASHBACK_SCN -- parameter to this value to ensure consistency between all of the -- objects included in the import. sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com(); DBMS_DATAPUMP.SET_PARAMETER( handle => h1, name => 'FLASHBACK_SCN', value => sscn); -- Start the job. DBMS_DATAPUMP.START_JOB(h1); -- The import job should be running. In the following loop, the job -- is monitored until it completes. job_state := 'UNDEFINED'; BEGIN WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP sts:=DBMS_DATAPUMP.GET_STATUS( handle => h1, mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR + DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS + DBMS_DATAPUMP.KU$_STATUS_WIP, timeout => -1); js := sts.job_status; DBMS_LOCK.SLEEP(10); job_state := js.state; END LOOP; -- Gets an exception when job no longer exists EXCEPTION WHEN job_not_exist THEN DBMS_OUTPUT.PUT_LINE('Data Pump job has completed'); DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn); END; END; / /* -
- Step 7 Configure the Apply Process at dbs3.example.com
-
Connect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
Configure
dbs3.example.comto apply DML and DDL changes to thecountriestable,locationstable, andregionstable.*/ BEGIN -- Create the rule set DBMS_RULE_ADM.CREATE_RULE_SET( rule_set_name => 'strmadmin.apply_rules', evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT'); -- Rules for hr.countries DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_countries_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''COUNTRIES'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_countries_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.get_object_name() = ''COUNTRIES'' AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Rules for hr.locations DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_locations_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''LOCATIONS'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_locations_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.get_object_name() = ''LOCATIONS'' AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Rules for hr.regions DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_regions_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''REGIONS'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_regions_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.get_object_name() = ''REGIONS'' AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Add rules to rule set DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_countries_dml', rule_set_name => 'strmadmin.apply_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_countries_ddl', rule_set_name => 'strmadmin.apply_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_locations_dml', rule_set_name => 'strmadmin.apply_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_locations_ddl', rule_set_name => 'strmadmin.apply_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_regions_dml', rule_set_name => 'strmadmin.apply_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_regions_ddl', rule_set_name => 'strmadmin.apply_rules'); -- Create an apply process that uses the rule set as its positive rule set DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.streams_queue', apply_name => 'apply', rule_set_name => 'strmadmin.apply_rules', apply_user => 'hr', apply_captured => TRUE, source_database => 'dbs1.example.com'); END; / /* - Step 8 Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Because the
hruser was specified as the apply user in the previous step, thehruser requiresEXECUTEprivilege on the positive rule set used by the apply process*/ BEGIN DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => 'strmadmin.apply_rules', grantee => 'hr'); END; / /* - Step 9 Start the Apply Process at dbs3.example.com
-
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start the apply process atdbs3.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply'); END; / /* - Step 10 Configure Propagation at dbs2.example.com
-
Connect to
dbs2.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs2.example.com /*
Configure and schedule propagation from the queue at
dbs2.example.comto the queue atdbs3.example.com. This configuration is an example of directed networks because the changes atdbs2.example.comoriginated atdbs1.example.com.*/ BEGIN -- Create the rule set DBMS_RULE_ADM.CREATE_RULE_SET( rule_set_name => 'strmadmin.propagation_dbs3_rules', evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT'); -- Create rules for all modifications to the countries table DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_countries_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''COUNTRIES'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_countries_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.get_object_name() = ''COUNTRIES'' AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Create rules for all modifications to the locations table DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_locations_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''LOCATIONS'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_locations_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.get_object_name() = ''LOCATIONS'' AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Create rules for all modifications to the regions table DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_regions_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''REGIONS'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_regions_ddl', condition => ' (:ddl.get_object_owner() = ''HR'' OR ' || ' :ddl.get_base_table_owner() = ''HR'') AND ' || ' :ddl.get_object_name() = ''REGIONS'' AND ' || ' :ddl.is_null_tag() = ''Y'' AND ' || ' :ddl.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Add rules to rule set DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_countries_dml', rule_set_name => 'strmadmin.propagation_dbs3_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_countries_ddl', rule_set_name => 'strmadmin.propagation_dbs3_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_locations_dml', rule_set_name => 'strmadmin.propagation_dbs3_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_locations_ddl', rule_set_name => 'strmadmin.propagation_dbs3_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_regions_dml', rule_set_name => 'strmadmin.propagation_dbs3_rules'); DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_regions_ddl', rule_set_name => 'strmadmin.propagation_dbs3_rules'); -- Create a propagation that uses the rule set as its positive rule set DBMS_PROPAGATION_ADM.CREATE_PROPAGATION( propagation_name => 'dbs2_to_dbs3', source_queue => 'strmadmin.streams_queue', destination_queue => 'strmadmin.streams_queue', destination_dblink => 'dbs3.example.com', rule_set_name => 'strmadmin.propagation_dbs3_rules'); END; / /* - Step 11 Create the Custom Rule-Based Transformation for Row LCRs at dbs2.example.com
-
Connect to
dbs2.example.comas thehruser.*/ CONNECT hr@dbs2.example.com /*
Create the custom rule-based transformation function that transforms row changes resulting from DML statements to the
jobstable fromdbs1.example.cominto row changes to theassignmentstable ondbs2.example.com.The following function transforms every row LCR for the
jobstable into a row LCR for theassignmentstable.Note:
If DDL changes were also applied to theassignmentstable, then another transformation would be required for the DDL LCRs. This transformation would need to change the object name and the DDL text.*/ CREATE OR REPLACE FUNCTION hr.to_assignments_trans_dml( p_in_data in ANYDATA) RETURN ANYDATA IS out_data SYS.LCR$_ROW_RECORD; tc pls_integer; BEGIN -- Typecast AnyData to LCR$_ROW_RECORD tc := p_in_data.GetObject(out_data); IF out_data.GET_OBJECT_NAME() = 'JOBS' THEN -- Transform the in_data into the out_data out_data.SET_OBJECT_NAME('ASSIGNMENTS'); END IF; -- Convert to AnyData RETURN ANYDATA.ConvertObject(out_data); END; / /* - Step 12 Configure the Apply Process for Local Apply at dbs2.example.com
-
Connect to
dbs2.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs2.example.com /*
Configure
dbs2.example.comto apply changes to the localassignmentstable. Remember that theassignmentstable receives changes from thejobstable atdbs1.example.com. This step specifies a custom rule-based transformation without using theSET_RULE_TRANSFORM_FUNCTIONprocedure in theDBMS_STREAMS_ADMpackage. Instead, a name-value pair is added manually to the action context of the rule. The name-value pair specifiesSTREAMS$_TRANSFORM_FUNCTIONfor the name andhr.to_assignments_trans_dmlfor the value.*/ DECLARE action_ctx_dml SYS.RE$NV_LIST; action_ctx_ddl SYS.RE$NV_LIST; ac_name VARCHAR2(30) := 'STREAMS$_TRANSFORM_FUNCTION'; BEGIN -- Specify the name-value pair in the action context action_ctx_dml := SYS.RE$NV_LIST(SYS.RE$NV_ARRAY()); action_ctx_dml.ADD_PAIR( ac_name, ANYDATA.CONVERTVARCHAR2('hr.to_assignments_trans_dml')); -- Create the rule set strmadmin.apply_rules DBMS_RULE_ADM.CREATE_RULE_SET( rule_set_name => 'strmadmin.apply_rules', evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT'); -- Create a rule that transforms all DML changes to the jobs table into -- DML changes for assignments table DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_jobs_dml', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''JOBS'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' ', action_context => action_ctx_dml); -- Add the rule to the rule set DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_jobs_dml', rule_set_name => 'strmadmin.apply_rules'); -- Create an apply process that uses the rule set as its positive rule set DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.streams_queue', apply_name => 'apply_dbs2', rule_set_name => 'strmadmin.apply_rules', apply_user => 'hr', apply_captured => TRUE, source_database => 'dbs1.example.com'); END; / /* - Step 13 Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Because the
hruser was specified as the apply user in the previous step, thehruser requiresEXECUTEprivilege on the positive rule set used by the apply process*/ BEGIN DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => 'strmadmin.apply_rules', grantee => 'hr'); END; / /* - Step 14 Start the Apply Process at dbs2.example.com for Local Apply
-
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start the apply process for local apply atdbs2.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_dbs2', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_dbs2'); END; / /* - Step 15 Configure the Apply Process at dbs2.example.com for Apply at dbs4.example.com
-
Configure
dbs2.example.comto apply DML changes to thejobstable atdbs4.example.com, which is a Sybase database. Remember that these changes originated atdbs1.example.com.*/ BEGIN -- Create the rule set DBMS_RULE_ADM.CREATE_RULE_SET( rule_set_name => 'strmadmin.apply_dbs4_rules', evaluation_context => 'SYS.STREAMS$_EVALUATION_CONTEXT'); -- Create rule strmadmin.all_jobs_remote for all modifications -- to the jobs table DBMS_RULE_ADM.CREATE_RULE( rule_name => 'strmadmin.all_jobs_remote', condition => ' :dml.get_object_owner() = ''HR'' AND ' || ' :dml.get_object_name() = ''JOBS'' AND ' || ' :dml.is_null_tag() = ''Y'' AND ' || ' :dml.get_source_database_name() = ''DBS1.EXAMPLE.COM'' '); -- Add the rule to the rule set DBMS_RULE_ADM.ADD_RULE( rule_name => 'strmadmin.all_jobs_remote', rule_set_name => 'strmadmin.apply_dbs4_rules'); -- Create an apply process that uses the rule set as its positive rule set DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.streams_queue', apply_name => 'apply_dbs4', rule_set_name => 'strmadmin.apply_dbs4_rules', apply_database_link => 'dbs4.example.com', apply_captured => TRUE, source_database => 'dbs1.example.com'); END; / /* - Step 16 Start the Apply Process at dbs2.example.com for Apply at dbs4.example.com
-
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start the remote apply for Sybase using database linkdbs4.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_dbs4', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_dbs4'); END; / /* - Step 17 Start the Capture Process at dbs1.example.com
-
Connect to
dbs1.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs1.example.com /*
Start the capture process at
dbs1.example.com.*/ BEGIN DBMS_CAPTURE_ADM.START_CAPTURE( capture_name => 'capture'); END; / /* - Step 18 Check the Spool Results
-
Check the
streams_share_schema2.outspool file to ensure that all actions finished successfully after this script is completed.*/ SET ECHO OFF SPOOL OFF /*
You can now make DML and DDL changes to specific tables at
dbs1.example.comand see these changes replicated to the other databases in the environment based on the rules you configured for the Oracle Streams processes and propagations in this environment.See Also:
"Make DML and DDL Changes to Tables in the hr Schema" for examples of changes that are replicated in this environment/*************************** END OF SCRIPT ******************************/
Make DML and DDL Changes to Tables in the hr Schema
After completing either of the examples described in "Example Scripts for Sharing Data from One Database", you can make DML and DDL changes to the tables in the hr schema at the dbs1.example.com database. These changes will be replicated to the other databases in the environment based on the rules you configured for Oracle Streams processes and propagations. You can check the other databases to see that the changes have been replicated.
For example, complete the following steps to make DML changes to the hr.jobs and hr.locations tables at dbs1.example.com. You can also make a DDL change to the hr.locations table at dbs1.example.com.
After you make these changes, you can query the hr.assignments table at dbs2.example.com to see that the DML change you made to this table at dbs1.example.com has been replicated. Remember that a custom rule-based transformation configured for the apply process at dbs2.example.com transforms DML changes to the hr.jobs table into DML changes to the hr.assignments table. You can also query the hr.locations table at dbs3.example.com to see that the DML and DDL changes you made to this table at dbs1.example.com have been replicated.
- Step 1 Make DML and DDL Changes to Tables in the hr Schema
-
Make the following changes:
CONNECT hr@dbs1.example.com Enter password: password UPDATE hr.jobs SET max_salary=10000 WHERE job_id='MK_REP'; COMMIT; INSERT INTO hr.locations VALUES( 3300, '521 Ralston Avenue', '94002', 'Belmont', 'CA', 'US'); COMMIT; ALTER TABLE hr.locations RENAME COLUMN state_province TO state_or_province; - Step 2 Query the hr.assignments Table at dbs2.example.com
-
After some time passes to allow for capture, propagation, and apply of the changes performed the previous step, run the following query to confirm that the
UPDATEchange made to thehr.jobstable atdbs1.example.comhas been applied to thehr.assignmentstable atdbs2.example.com.CONNECT hr@dbs2.example.com Enter password: password SELECT max_salary FROM hr.assignments WHERE job_id='MK_REP';You should see
10000for the value of themax_salary. - Step 3 Query and Describe the hr.locations Table at dbs3.example.com
-
Run the following query to confirm that the
INSERTchange made to thehr.locationstable atdbs1.example.comhas been applied atdbs3.example.com.CONNECT hr@dbs3.example.com Enter password: password SELECT * FROM hr.locations WHERE location_id=3300;You should see the row inserted into the
hr.locationstable atdbs1.example.comin the previous step.Next, describe the
hr.locationstable at to confirm that theALTERTABLEchange was propagated and applied correctly.DESC hr.locations
The fifth column in the table should be
state_or_province.
Add Objects to an Existing Oracle Streams Replication Environment
This example extends the Oracle Streams environment configured in the previous sections by adding replicated objects to an existing database. To complete this example, you must have completed the tasks in one of the previous examples in this chapter.
This example will add the following tables to the hr schema in the dbs3.example.com database:
-
departments -
employees -
job_history -
jobs
When you complete this example, Oracle Streams processes changes to these tables with the following series of actions:
-
The capture process captures changes at
dbs1.example.comand enqueues them atdbs1.example.com. -
A propagation propagates changes from the queue at
dbs1.example.comto the queue atdbs2.example.com. -
A propagation propagates changes from the queue at
dbs2.example.comto the queue atdbs3.example.com. -
The apply process at
dbs3.example.comapplies the changes atdbs3.example.com.
When you complete this example, the hr schema at the dbs3.example.com database will have all of its original tables, because the countries, locations, and regions tables were instantiated at dbs3.example.com in the previous section.
Figure 2-2 provides an overview of the environment with the added tables.
Figure 2-2 Adding Objects to dbs3.example.com in the Environment
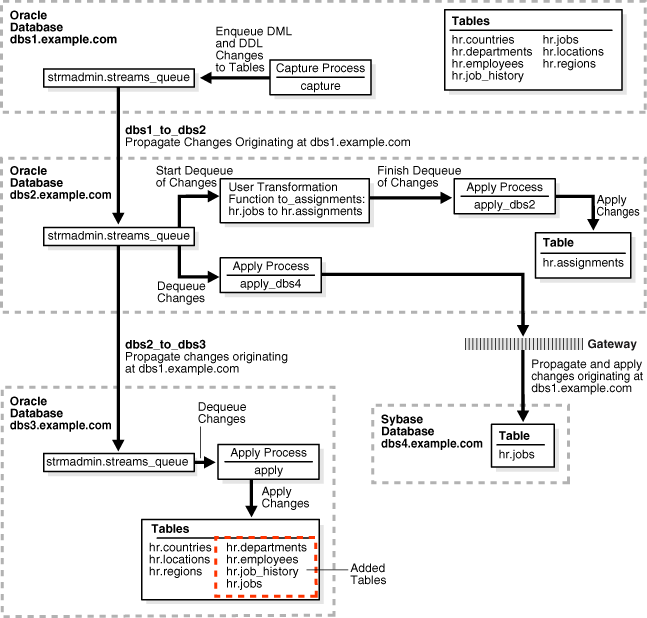
Description of "Figure 2-2 Adding Objects to dbs3.example.com in the Environment"
Complete the following steps to replicate these tables to the dbs3.example.com database.
-
Configure the Apply Process for the Added Tables at dbs3.example.com
-
Specify the Table Propagation Rules for the Added Tables at dbs2.example.com
-
Prepare the Four Added Tables for Instantiation at dbs1.example.com
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
- Step 1 Show Output and Spool Results
-
Run
SETECHOONand specify the spool file for the script. Check the spool file for errors after you run this script.*/ SET ECHO ON SPOOL streams_addobjs.out /*
- Step 2 Stop the Apply Process at dbs3.example.com
-
Until you finish adding objects to
dbs3.example.com, you must ensure that the apply process that will apply changes for the added objects does not try to apply changes for these objects. You can do this by stopping the capture process at the source database. Or, you can do this by stopping propagation of changes fromdbs2.example.comtodbs3.example.com. Yet another alternative is to stop the apply process atdbs3.example.com. This example stops the apply process atdbs3.example.com.Connect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
Stop the apply process at
dbs3.example.com.*/ BEGIN DBMS_APPLY_ADM.STOP_APPLY( apply_name => 'apply'); END; / /* - Step 3 Configure the Apply Process for the Added Tables at dbs3.example.com
-
Configure the apply process at
dbs3.example.comto apply changes to the tables you are adding.*/ BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.departments', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.employees', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.job_history', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.jobs', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / /* - Step 4 Specify the Table Propagation Rules for the Added Tables at dbs2.example.com
-
Connect to
dbs2.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs2.example.com /*
Add the tables to the rules for propagation from the queue at
dbs2.example.comto the queue atdbs3.example.com.*/ BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.departments', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.employees', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.job_history', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.jobs', streams_name => 'dbs2_to_dbs3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs3.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / /* - Step 5 Prepare the Four Added Tables for Instantiation at dbs1.example.com
-
Connect to
dbs1.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs1.example.com /*
Prepare the tables for instantiation. These tables will be instantiated at
dbs3.example.com. This step marks the lowest SCN of the tables for instantiation. SCNs subsequent to the lowest SCN can be used for instantiation. Also, this preparation is necessary so that the Oracle Streams data dictionary for the relevant propagations and the apply process atdbs3.example.comcontain information about these tables.Note:
When thePREPARE_TABLE_INSTANTIATIONprocedure is run in this step, thesupplemental_loggingparameter is not specified. Therefore, the default value (keys) is used for this parameter. Supplemental logging already was enabled for any primary key, unique key, bitmap index, and foreign key columns in these tables in Step 3.*/ BEGIN DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION( table_name => 'hr.departments'); END; / BEGIN DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION( table_name => 'hr.employees'); END; / BEGIN DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION( table_name => 'hr.job_history'); END; / BEGIN DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION( table_name => 'hr.jobs'); END; / /* - Step 6 Instantiate the dbs1.example.com Tables at dbs3.example.com
-
This example performs a network Data Pump import of the following tables:
-
hr.departments -
hr.employees -
hr.job_history -
hr.jobs
A network import means that Data Pump imports these tables from
dbs1.example.comwithout using an export dump file.See Also:
Oracle Database Utilities for information about performing an importConnect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
This example will do a table import using the
DBMS_DATAPUMPpackage. For simplicity, exceptions from any of the API calls will not be trapped. However, Oracle recommends that you define exception handlers and callGET_STATUSto retrieve more detailed error information if a failure occurs. If you want to monitor the import, then query theDBA_DATAPUMP_JOBSdata dictionary view at the import database.*/ SET SERVEROUTPUT ON DECLARE h1 NUMBER; -- Data Pump job handle sscn NUMBER; -- Variable to hold current source SCN job_state VARCHAR2(30); -- To keep track of job state js ku$_JobStatus; -- The job status from GET_STATUS sts ku$_Status; -- The status object returned by GET_STATUS job_not_exist exception; pragma exception_init(job_not_exist, -31626); BEGIN -- Create a (user-named) Data Pump job to do a table-level import. h1 := DBMS_DATAPUMP.OPEN( operation => 'IMPORT', job_mode => 'TABLE', remote_link => 'DBS1.EXAMPLE.COM', job_name => 'dp_sing3'); -- A metadata filter is used to specify the schema that owns the tables -- that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'SCHEMA_EXPR', value => '=''HR'''); -- A metadata filter is used to specify the tables that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'NAME_EXPR', value => 'IN(''DEPARTMENTS'', ''EMPLOYEES'', ''JOB_HISTORY'', ''JOBS'')'); -- Get the current SCN of the source database, and set the FLASHBACK_SCN -- parameter to this value to ensure consistency between all of the -- objects included in the import. sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com(); DBMS_DATAPUMP.SET_PARAMETER( handle => h1, name => 'FLASHBACK_SCN', value => sscn); -- Start the job. DBMS_DATAPUMP.START_JOB(h1); -- The import job should be running. In the following loop, the job -- is monitored until it completes. job_state := 'UNDEFINED'; BEGIN WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP sts:=DBMS_DATAPUMP.GET_STATUS( handle => h1, mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR + DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS + DBMS_DATAPUMP.KU$_STATUS_WIP, timeout => -1); js := sts.job_status; DBMS_LOCK.SLEEP(10); job_state := js.state; END LOOP; -- Gets an exception when job no longer exists EXCEPTION WHEN job_not_exist THEN DBMS_OUTPUT.PUT_LINE('Data Pump job has completed'); DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn); END; END; / /* -
- Step 7 Start the Apply Process at dbs3.example.com
-
Start the apply process at
dbs3.example.com. This apply process was stopped in Step 2.Connect to
dbs3.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs3.example.com /*
Start the apply process at
dbs3.example.com.*/ BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply'); END; / /* - Step 8 Check the Spool Results
-
Check the
streams_addobjs.outspool file to ensure that all actions finished successfully after this script is completed.*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
Make a DML Change to the hr.employees Table
After completing the examples described in the "Add Objects to an Existing Oracle Streams Replication Environment" section, you can make DML and DDL changes to the tables in the hr schema at the dbs1.example.com database. These changes will be replicated to dbs3.example.com. You can check these tables at dbs3.example.com to see that the changes have been replicated.
For example, complete the following steps to make a DML change to the hr.employees table at dbs1.example.com. Next, query the hr.employees table at dbs3.example.com to see that the change has been replicated.
- Step 1 Make a DML Change to the hr.employees Table
-
Make the following change:
CONNECT hr@dbs1.example.com Enter password: password UPDATE hr.employees SET job_id='ST_MAN' WHERE employee_id=143; COMMIT; - Step 2 Query the hr.employees Table at dbs3.example.com
-
After some time passes to allow for capture, propagation, and apply of the change performed in the previous step, run the following query to confirm that the
UPDATEchange made to thehr.employeestable atdbs1.example.comhas been applied to thehr.employeestable atdbs3.example.com.CONNECT hr@dbs3.example.com Enter password: password SELECT job_id FROM hr.employees WHERE employee_id=143;You should see
ST_MANfor the value of thejob_id.
Add a Database to an Existing Oracle Streams Replication Environment
This example extends the Oracle Streams environment configured in the previous sections by adding an additional database to the existing configuration. In this example, an existing Oracle database named dbs5.example.com is added to receive changes to the entire hr schema from the queue at dbs2.example.com.
Figure 2-3 provides an overview of the environment with the added database.
Figure 2-3 Adding the dbs5.example.com Oracle Database to the Environment
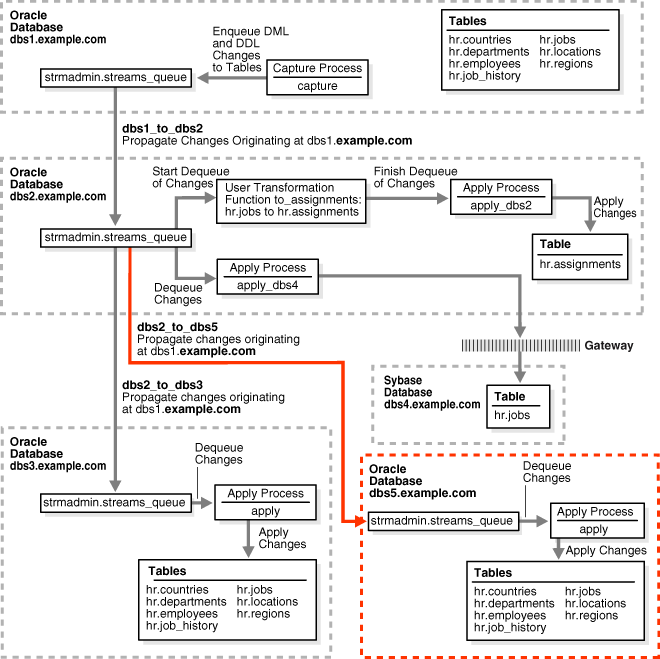
Description of "Figure 2-3 Adding the dbs5.example.com Oracle Database to the Environment"
To complete this example, you must meet the following prerequisites:
-
The
dbs5.example.comdatabase must exist. -
The
dbs2.example.comanddbs5.example.comdatabases must be able to communicate with each other through Oracle Net. -
The
dbs5.example.comanddbs1.example.comdatabases must be able to communicate with each other through Oracle Net (for optional Data Pump network instantiation). -
You must have completed the tasks in the previous examples in this chapter.
-
The "Prerequisites" must be met if you want the entire Oracle Streams environment to work properly.
-
This examples creates a new user to function as the Oracle Streams administrator (
strmadmin) at thedbs5.example.comdatabase and prompts you for the tablespace you want to use for this user's data. Before you start this example, either create a new tablespace or identify an existing tablespace for the Oracle Streams administrator to use at thedbs5.example.comdatabase. The Oracle Streams administrator should not use theSYSTEMtablespace.
Complete the following steps to add dbs5.example.com to the Oracle Streams environment.
-
Create a Database Link at dbs5.example.com to dbs1.example.com
-
Specify hr as the Apply User for the Apply Process at dbs5.example.com
-
Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Create the Database Link Between dbs2.example.com and dbs5.example.com
-
Configure Propagation Between dbs2.example.com and dbs5.example.com
Note:
If you are viewing this document online, then you can copy the text from the "BEGINNING OF SCRIPT" line after this note to the next "END OF SCRIPT" line into a text editor and then edit the text to create a script for your environment. Run the script with SQL*Plus on a computer that can connect to all of the databases in the environment./************************* BEGINNING OF SCRIPT ******************************
- Step 1 Show Output and Spool Results
-
Run
SETECHOONand specify the spool file for the script. Check the spool file for errors after you run this script.*/ SET ECHO ON SPOOL streams_adddb.out /*
- Step 2 Drop All of the Tables in the hr Schema at dbs5.example.com
-
This example illustrates instantiating the tables in the
hrschema by importing them fromdbs1.example.comintodbs5.example.comusing Data Pump. You must delete these tables atdbs5.example.comfor the instantiation portion of this example to work properly.Connect as
hratdbs5.example.com.*/ CONNECT hr@dbs5.example.com /*
Drop all tables in the
hrschema in thedbs5.example.comdatabase.Note:
If you complete this step and drop all of the tables in thehrschema, then you should complete the remaining sections of this example to reinstantiate thehrschema atdbs5.example.com. If thehrschema does not exist in an Oracle database, then some examples in the Oracle documentation set can fail.*/ DROP TABLE hr.countries CASCADE CONSTRAINTS; DROP TABLE hr.departments CASCADE CONSTRAINTS; DROP TABLE hr.employees CASCADE CONSTRAINTS; DROP TABLE hr.job_history CASCADE CONSTRAINTS; DROP TABLE hr.jobs CASCADE CONSTRAINTS; DROP TABLE hr.locations CASCADE CONSTRAINTS; DROP TABLE hr.regions CASCADE CONSTRAINTS; /*
- Step 3 Set Up Users at dbs5.example.com
-
Connect to
dbs5.example.comasSYSTEMuser.*/ CONNECT system@dbs5.example.com /*
Create the Oracle Streams administrator named
strmadminand grant this user the necessary privileges. These privileges enable the user to manage queues, execute subprograms in packages related to Oracle Streams, create rule sets, create rules, and monitor the Oracle Streams environment by querying data dictionary views and queue tables. You can choose a different name for this user.Note:
TheACCEPTcommand must appear on a single line in the script.See Also:
Oracle Streams Replication Administrator's Guide for more information about configuring an Oracle Streams administrator*/ ACCEPT password PROMPT 'Enter password for user: ' HIDE GRANT DBA TO strmadmin IDENTIFIED BY &password; ACCEPT streams_tbs PROMPT 'Enter Oracle Streams administrator tablespace on dbs5.example.com: ' HIDE ALTER USER strmadmin DEFAULT TABLESPACE &streams_tbs QUOTA UNLIMITED ON &streams_tbs; /* - Step 4 Create the ANYDATA Queue at dbs5.example.com
-
Connect as the Oracle Streams administrator at the database you are adding. In this example, that database is
dbs5.example.com.*/ CONNECT strmadmin@dbs5.example.com /*
Run the
SET_UP_QUEUEprocedure to create a queue namedstreams_queueatdbs5.example.com. This queue will function as theANYDATAqueue by holding the changes that will be applied at this database.Running the
SET_UP_QUEUEprocedure performs the following actions:-
Creates a queue table named
streams_queue_table. This queue table is owned by the Oracle Streams administrator (strmadmin) and uses the default storage of this user. -
Creates a queue named
streams_queueowned by the Oracle Streams administrator (strmadmin). -
Starts the queue.
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
-
- Step 5 Create a Database Link at dbs5.example.com to dbs1.example.com
-
Create a database link from
dbs5.example.comtodbs1.example.com. Later in this example, this database link is used for the instantiation of the database objects that were dropped in Step 2. This example uses theDBMS_DATAPUMPpackage to perform a network import of these database objects directly from thedbs1.example.comdatabase. Because this example performs a network import, no dump file is required.Alternatively, you can perform an export at the source database
dbs1.example.com, transfer the export dump file to the destination databasedbs5.example.com, and then import the export dump file at the destination database. In this case, the database link created in this step is not required.*/ CREATE DATABASE LINK dbs1.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs1.example.com'; /*
- Step 6 Configure the Apply Process at dbs5.example.com
-
While still connected as the Oracle Streams administrator at
dbs5.example.com, configure the apply process to apply changes to thehrschema.*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply', queue_name => 'strmadmin.streams_queue', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE); END; / /* - Step 7 Specify hr as the Apply User for the Apply Process at dbs5.example.com
-
In this example, the
hruser owns all of the database objects for which changes are applied by the apply process at this database. Therefore,hralready has the necessary privileges to change these database objects, and it is convenient to makehrthe apply user.When the apply process was created in the previous step, the Oracle Streams administrator
strmadminwas specified as the apply user by default, becausestrmadminran the procedure that created the apply process. Instead of specifying hr as the apply user, you could retainstrmadminas the apply user, but then you must grantstrmadminprivileges on all of the database objects for which changes are applied and privileges to execute all user procedures used by the apply process. In an environment where an apply process applies changes to database objects in multiple schemas, it might be more convenient to use the Oracle Streams administrator as the apply user.See Also:
Oracle Streams Replication Administrator's Guide for more information about configuring an Oracle Streams administrator*/ BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply', apply_user => 'hr'); END; / /* - Step 8 Grant the hr User Execute Privilege on the Apply Process Rule Set
-
Because the
hruser was specified as the apply user in the previous step, thehruser requiresEXECUTEprivilege on the positive rule set used by the apply process*/ DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / /* - Step 9 Create the Database Link Between dbs2.example.com and dbs5.example.com
-
Connect to
dbs2.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs2.example.com /*
Create the database links to the databases where changes are propagated. In this example, database
dbs2.example.compropagates changes todbs5.example.com.*/ CREATE DATABASE LINK dbs5.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'dbs5.example.com'; /*
- Step 10 Configure Propagation Between dbs2.example.com and dbs5.example.com
-
While still connected as the Oracle Streams administrator at
dbs2.example.com, configure and schedule propagation from the queue atdbs2.example.comto the queue atdbs5.example.com. Remember, changes to thehrschema originated atdbs1.example.com.*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'dbs2_to_dbs5', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@dbs5.example.com', include_dml => TRUE, include_ddl => TRUE, source_database => 'dbs1.example.com', inclusion_rule => TRUE, queue_to_queue => TRUE); END; / /* - Step 11 Prepare the hr Schema for Instantiation at dbs1.example.com
-
Connect to
dbs1.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs1.example.com /*
Prepare the
hrschema for instantiation. These tables in this schema will be instantiated atdbs5.example.com. This preparation is necessary so that the Oracle Streams data dictionary for the relevant propagations and the apply process atdbs5.example.comcontain information about thehrschema and the objects in the schema.*/ BEGIN DBMS_CAPTURE_ADM.PREPARE_SCHEMA_INSTANTIATION( schema_name => 'hr', supplemental_logging => 'keys'); END; / /* - Step 12 Instantiate the dbs1.example.com Tables at dbs5.example.com
-
This example performs a network Data Pump import of the following tables:
-
hr.countries -
hr.departments -
hr.employees -
hr.job_history -
hr.jobs -
hr.locations -
hr.regions
A network import means that Data Pump imports these tables from
dbs1.example.comwithout using an export dump file.See Also:
Oracle Database Utilities for information about performing an importConnect to
dbs5.example.comas thestrmadminuser.*/ CONNECT strmadmin@dbs5.example.com /*
This example will do a table import using the
DBMS_DATAPUMPpackage. For simplicity, exceptions from any of the API calls will not be trapped. However, Oracle recommends that you define exception handlers and callGET_STATUSto retrieve more detailed error information if a failure occurs. If you want to monitor the import, then query theDBA_DATAPUMP_JOBSdata dictionary view at the import database.*/ SET SERVEROUTPUT ON DECLARE h1 NUMBER; -- Data Pump job handle sscn NUMBER; -- Variable to hold current source SCN job_state VARCHAR2(30); -- To keep track of job state js ku$_JobStatus; -- The job status from GET_STATUS sts ku$_Status; -- The status object returned by GET_STATUS job_not_exist exception; pragma exception_init(job_not_exist, -31626); BEGIN -- Create a (user-named) Data Pump job to do a table-level import. h1 := DBMS_DATAPUMP.OPEN( operation => 'IMPORT', job_mode => 'TABLE', remote_link => 'DBS1.EXAMPLE.COM', job_name => 'dp_sing4'); -- A metadata filter is used to specify the schema that owns the tables -- that will be imported. DBMS_DATAPUMP.METADATA_FILTER( handle => h1, name => 'SCHEMA_EXPR', value => '=''HR'''); -- Get the current SCN of the source database, and set the FLASHBACK_SCN -- parameter to this value to ensure consistency between all of the -- objects included in the import. sscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER@dbs1.example.com(); DBMS_DATAPUMP.SET_PARAMETER( handle => h1, name => 'FLASHBACK_SCN', value => sscn); -- Start the job. DBMS_DATAPUMP.START_JOB(h1); -- The import job should be running. In the following loop, the job -- is monitored until it completes. job_state := 'UNDEFINED'; BEGIN WHILE (job_state != 'COMPLETED') AND (job_state != 'STOPPED') LOOP sts:=DBMS_DATAPUMP.GET_STATUS( handle => h1, mask => DBMS_DATAPUMP.KU$_STATUS_JOB_ERROR + DBMS_DATAPUMP.KU$_STATUS_JOB_STATUS + DBMS_DATAPUMP.KU$_STATUS_WIP, timeout => -1); js := sts.job_status; DBMS_LOCK.SLEEP(10); job_state := js.state; END LOOP; -- Gets an exception when job no longer exists EXCEPTION WHEN job_not_exist THEN DBMS_OUTPUT.PUT_LINE('Data Pump job has completed'); DBMS_OUTPUT.PUT_LINE('Instantiation SCN: ' ||sscn); END; END; / /* -
- Step 13 Start the Apply Process at dbs5.example.com
-
Connect as the Oracle Streams administrator at
dbs5.example.com.*/ CONNECT strmadmin@dbs5.example.com /*
Set the
disable_on_errorparameter tonso that the apply process will not be disabled if it encounters an error, and start apply process atdbs5.example.com.*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply', parameter => 'disable_on_error', value => 'N'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply'); END; / /* - Step 14 Check the Spool Results
-
Check the
streams_adddb.outspool file to ensure that all actions finished successfully after this script is completed.*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
Make a DML Change to the hr.departments Table
After completing the examples described in the "Add a Database to an Existing Oracle Streams Replication Environment" section, you can make DML and DDL changes to the tables in the hr schema at the dbs1.example.com database. These changes will be replicated to dbs5.example.com. You can check these tables at dbs5.example.com to see that the changes have been replicated.
For example, complete the following steps to make a DML change to the hr.departments table at dbs1.example.com. Next, query the hr.departments table at dbs5.example.com to see that the change has been replicated.
- Step 1 Make a DML Change to the hr.departments Table
-
Make the following change:
CONNECT hr@dbs1.example.com Enter password: password UPDATE hr.departments SET location_id=2400 WHERE department_id=270; COMMIT; - Step 2 Query the hr.departments Table at dbs5.example.com
-
After some time passes to allow for capture, propagation, and apply of the change performed in the previous step, run the following query to confirm that the
UPDATEchange made to thehr.departmentstable atdbs1.example.comhas been applied to thehr.departmentstable atdbs5.example.com.CONNECT hr@dbs5.example.com Enter password: password SELECT location_id FROM hr.departments WHERE department_id=270;You should see
2400for the value of thelocation_id.