4 Partitions, Views, and Other Schema Objects
Although tables and indexes are the most important and commonly used schema objects, the database supports many other types of schema objects, the most common of which are discussed in this chapter.
This chapter contains the following sections:
Overview of Partitions
Partitioning enables you to decompose very large tables and indexes into smaller and more manageable pieces called partitions. Each partition is an independent object with its own name and optionally its own storage characteristics.
For an analogy that illustrates partitioning, suppose an HR manager has one big box that contains employee folders. Each folder lists the employee hire date. Queries are often made for employees hired in a particular month. One approach to satisfying such requests is to create an index on employee hire date that specifies the locations of the folders scattered throughout the box. In contrast, a partitioning strategy uses many smaller boxes, with each box containing folders for employees hired in a given month.
Using smaller boxes has several advantages. When asked to retrieve the folders for employees hired in June, the HR manager can retrieve the June box. Furthermore, if any small box is temporarily damaged, the other small boxes remain available. Moving offices also becomes easier because instead of moving a single heavy box, the manager can move several small boxes.
From the perspective of an application, only one schema object exists. DML statements require no modification to access partitioned tables. Partitioning is useful for many different types of database applications, particularly those that manage large volumes of data. Benefits include:
-
Increased availability
The unavailability of a partition does not entail the unavailability of the object. The query optimizer automatically removes unreferenced partitions from the query plan so queries are not affected when the partitions are unavailable.
-
Easier administration of schema objects
A partitioned object has pieces that can be managed either collectively or individually. DDL statements can manipulate partitions rather than entire tables or indexes. Thus, you can break up resource-intensive tasks such as rebuilding an index or table. For example, you can move one table partition at a time. If a problem occurs, then only the partition move must be redone, not the table move. Also, dropping a partition avoids executing numerous
DELETEstatements. -
Reduced contention for shared resources in OLTP systems
In some OLTP systems, partitions can decrease contention for a shared resource. For example, DML is distributed over many segments rather than one segment.
-
Enhanced query performance in data warehouses
In a data warehouse, partitioning can speed processing of ad hoc queries. For example, a sales table containing a million rows can be partitioned by quarter.
See Also:
Oracle Database VLDB and Partitioning Guide for an introduction to partitioningPartition Characteristics
Each partition of a table or index must have the same logical attributes, such as column names, data types, and constraints. For example, all partitions in a table share the same column and constraint definitions, and all partitions in an index share the same indexed columns. However, each partition can have separate physical attributes, such as the tablespace to which it belongs.
Partition Key
The partition key is a set of one or more columns that determines the partition in which each row in a partitioned table should go. Each row is unambiguously assigned to a single partition.
In the sales table, you could specify the time_id column as the key of a range partition. The database assigns rows to partitions based on whether the date in this column falls in a specified range. Oracle Database automatically directs insert, update, and delete operations to the appropriate partition by using the partition key.
Partitioning Strategies
Oracle Partitioning offers several partitioning strategies that control how the database places data into partitions. The basic strategies are range, list, and hash partitioning.
A single-level partitioning strategy uses only one method of data distribution, for example, only list partitioning or only range partitioning. In composite partitioning, a table is partitioned by one data distribution method and then each partition is further divided into subpartitions using a second data distribution method. For example, you could use a list partition for channel_id and a range subpartition for time_id.
Range Partitioning
In range partitioning, the database maps rows to partitions based on ranges of values of the partitioning key. Range partitioning is the most common type of partitioning and is often used with dates.
Suppose that you want to populate a partitioned table with the sales rows shown in Example 4-1.
Example 4-1 Sample Row Set for Partitioned Table
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
116 11393 05-JUN-99 2 999 1 12.18
40 100530 30-NOV-98 9 33 1 44.99
118 133 06-JUN-01 2 999 1 17.12
133 9450 01-DEC-00 2 999 1 31.28
36 4523 27-JAN-99 3 999 1 53.89
125 9417 04-FEB-98 3 999 1 16.86
30 170 23-FEB-01 2 999 1 8.8
24 11899 26-JUN-99 4 999 1 43.04
35 2606 17-FEB-00 3 999 1 54.94
45 9491 28-AUG-98 4 350 1 47.45
You create time_range_sales as a partitioned table using the statement in Example 4-2. The time_id column is the partition key.
Example 4-2 Range-Partitioned Table
CREATE TABLE time_range_sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY RANGE (time_id) (PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')), PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')), PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')), PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE) );
Afterward, you load time_range_sales with the rows from Example 4-1. Figure 4-1 shows the row distributions in the four partitions. The database chooses the partition for each row based on the time_id value according to the rules specified in the PARTITION BY RANGE clause.
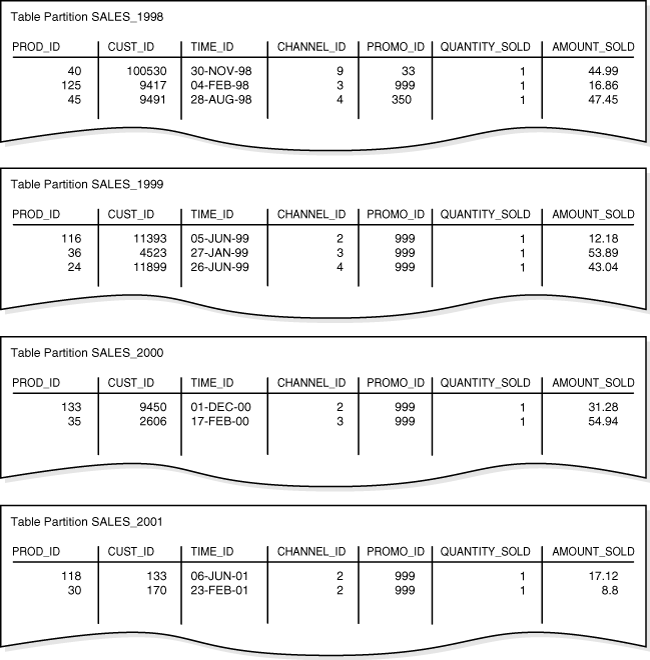
The range partition key value determines the high value of the range partitions, which is called the transition point. In Figure 4-1, the SALES_1998 partition contains rows with partitioning key time_id values less than the transition point 01-JAN-1999.
The database creates interval partitions for data beyond that transition point. Interval partitions extend range partitioning by instructing the database to create partitions of the specified range or interval automatically when data inserted into the table exceeds all of the range partitions. In Figure 4-1, the SALES_2001 partition contains rows with partitioning key time_id values greater than or equal to 01-JAN-2001.
List Partitioning
In list partitioning, the database uses a list of discrete values as the partition key for each partition. You can use list partitioning to control how individual rows map to specific partitions. By using lists, you can group and organize related sets of data when the key used to identify them is not conveniently ordered.
Assume that you create list_sales as a list-partitioned table using the statement in Example 4-3. The channel_id column is the partition key.
Example 4-3 List-Partitioned Table
CREATE TABLE list_sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY LIST (channel_id) (PARTITION even_channels VALUES (2,4), PARTITION odd_channels VALUES (3,9) );
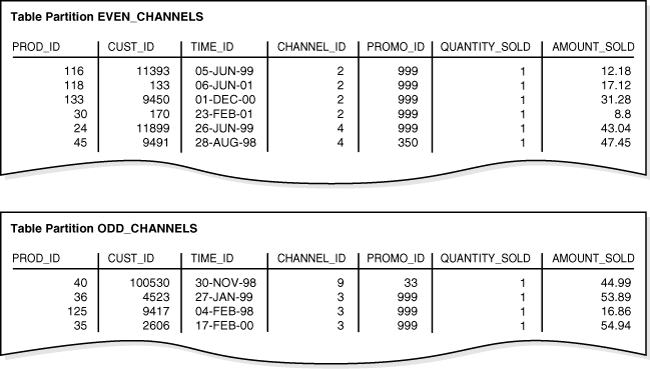
Afterward, you load the table with the rows from Example 4-1. Figure 4-2 shows the row distribution in the two partitions. The database chooses the partition for each row based on the channel_id value according to the rules specified in the PARTITION BY LIST clause. Rows with a channel_id value of 2 or 4 are stored in the EVEN_CHANNELS partitions, while rows with a channel_id value of 3 or 9 are stored in the ODD_CHANNELS partition.
Hash Partitioning
In hash partitioning, the database maps rows to partitions based on a hashing algorithm that the database applies to the user-specified partitioning key. The destination of a row is determined by the internal hash function applied to the row by the database. The hashing algorithm is designed to evenly distributes rows across devices so that each partition contains about the same number of rows.
Hash partitioning is useful for dividing large tables to increase manageability. Instead of one large table to manage, you have several smaller pieces. The loss of a single hash partition does not affect the remaining partitions and can be recovered independently. Hash partitioning is also useful in OLTP systems with high update contention. For example, a segment is divided into several pieces, each of which is updated, instead of a single segment that experiences contention.
Assume that you create the partitioned hash_sales table using the statement in Example 4-4. The prod_id column is the partition key.
Example 4-4 Hash-Partitioned Table
CREATE TABLE hash_sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY HASH (prod_id) PARTITIONS 2;
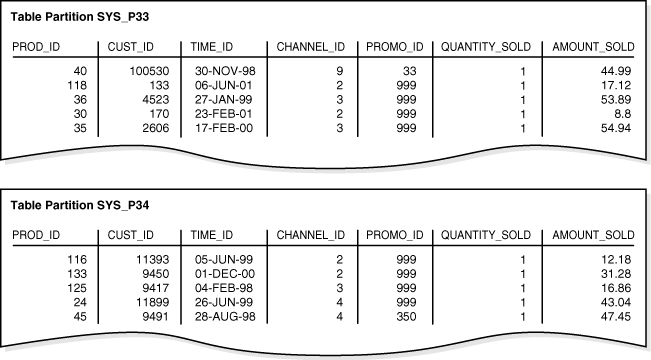
Afterward, you load the table with the rows from Example 4-1. Figure 4-3 shows a possible row distribution in the two partitions. Note that the names of these partitions are system-generated.
As you insert rows, the database attempts to randomly and evenly distribute them across partitions. You cannot specify the partition into which a row is placed. The database applies the hash function, whose outcome determines which partition contains the row. If you change the number of partitions, then the database redistributes the data over all of the partitions.
See Also:
-
Oracle Database VLDB and Partitioning Guide to learn how to create partitions
-
Oracle Database SQL Language Reference for
CREATE TABLE ... PARTITION BYexamples
Partitioned Tables
A partitioned table consists of one or more partitions, which are managed individually and can operate independently of the other partitions. A table is either partitioned or nonpartitioned. Even if a partitioned table consists of only one partition, this table is different from a nonpartitioned table, which cannot have partitions added to it. "Partition Characteristics" gives examples of partitioned tables.
A partitioned table is made up of one or more table partition segments. If you create a partitioned table named hash_products, then no table segment is allocated for this table. Instead, the database stores data for each table partition in its own partition segment. Each table partition segment contains a portion of the table data.
Some or all partitions of a heap-organized table can be stored in a compressed format. Compression saves space and can speed query execution. Thus, compression can be useful in environments such as data warehouses, where the amount of insert and update operations is small, and in OLTP environments.
The attributes for table compression can be declared for a tablespace, table, or table partition. If declared at the tablespace level, then tables created in the tablespace are compressed by default. You can alter the compression attribute for a table, in which case the change only applies to new data going into that table. Consequently, a single table or partition may contain compressed and uncompressed blocks, which guarantees that data size will not increase because of compression. If compression could increase the size of a block, then the database does not apply it to the block.
See Also:
-
Oracle Database Data Warehousing Guide to learn about table compression in a data warehouse
Partitioned Indexes
A partitioned index is an index that, like a partitioned table, has been decomposed into smaller and more manageable pieces. Global indexes are partitioned independently of the table on which they are created, whereas local indexes are automatically linked to the partitioning method for a table. Like partitioned tables, partitioned indexes improve manageability, availability, performance, and scalability.
The following graphic shows index partitioning options.
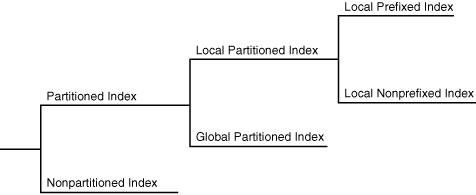
Description of the illustration cncpt301.gif
See Also:
-
Oracle Database VLDB and Partitioning Guide and Oracle Database Performance Tuning Guide for more information about partitioned indexes and how to decide which type to use
Local Partitioned Indexes
In a local partitioned index, the index is partitioned on the same columns, with the same number of partitions and the same partition bounds as its table. Each index partition is associated with exactly one partition of the underlying table, so that all keys in an index partition refer only to rows stored in a single table partition. In this way, the database automatically synchronizes index partitions with their associated table partitions, making each table-index pair independent.
Local partitioned indexes are common in data warehousing environments. Local indexes offer the following advantages:
-
Availability is increased because actions that make data invalid or unavailable in a partition affect this partition only.
-
Partition maintenance is simplified. When moving a table partition, or when data ages out of a partition, only the associated local index partition must be rebuilt or maintained. In a global index, all index partitions must be rebuilt or maintained.
-
If point-in-time recovery of a partition occurs, then the indexes can be recovered to the recovery time (see "Data File Recovery"). The entire index does not need to be rebuilt.
Example 4-4 shows the creation statement for the partitioned hash_sales table, using the prod_id column as partition key. Example 4-5 creates a local partitioned index on the time_id column of the hash_sales table.
In Figure 4-4, the hash_products table has two partitions, so hash_sales_idx has two partitions. Each index partition is associated with a different table partition. Index partition SYS_P38 indexes rows in table partition SYS_P33, whereas index partition SYS_P39 indexes rows in table partition SYS_P34.
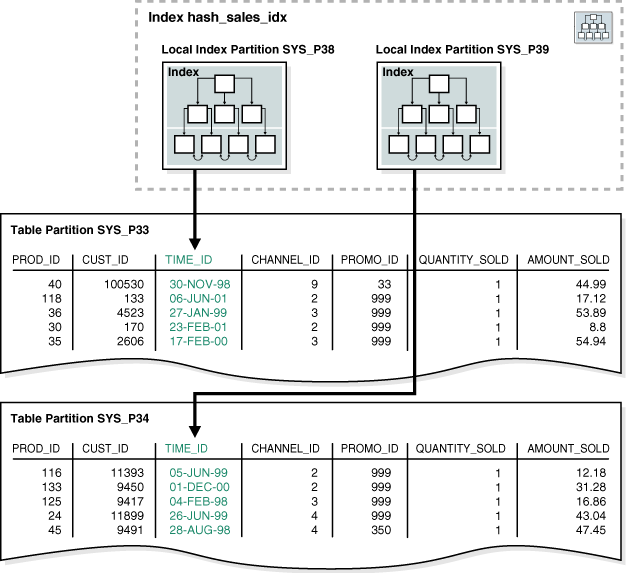
You cannot explicitly add a partition to a local index. Instead, new partitions are added to local indexes only when you add a partition to the underlying table. Likewise, you cannot explicitly drop a partition from a local index. Instead, local index partitions are dropped only when you drop a partition from the underlying table.
Like other indexes, you can create a bitmap index on partitioned tables. The only restriction is that bitmap indexes must be local to the partitioned table—they cannot be global indexes. Global bitmap indexes are supported only on nonpartitioned tables.
Local Prefixed and Nonprefixed Indexes
Local partitioned indexes are divided into the following subcategories:
-
In this case, the partition keys are on the leading edge of the index definition. In Example 4-2, the table is partitioned by range on
time_id. A local prefixed index on this table would havetime_idas the first column in its list. -
Local nonprefixed indexes
In this case, the partition keys are not on the leading edge of the indexed column list and need not be in the list at all. In Example 4-5, the index is local nonprefixed because the partition key
product_idis not on the leading edge.
Both types of indexes can take advantage of partition elimination (also called partition pruning), which occurs when the optimizer speeds data access by excluding partitions from consideration. Whether a query can eliminate partitions depends on the query predicate. A query that uses a local prefixed index always allows for index partition elimination, whereas a query that uses a local nonprefixed index might not.
See Also:
Oracle Database VLDB and Partitioning Guide to learn how to use prefixed and nonprefixed indexesGlobal Partitioned Indexes
A global partitioned index is a B-tree index that is partitioned independently of the underlying table on which it is created. A single index partition can point to any or all table partitions, whereas in a locally partitioned index, a one-to-one parity exists between index partitions and table partitions.
In general, global indexes are useful for OLTP applications, where rapid access, data integrity, and availability are important. In an OLTP system, a table may be partitioned by one key, for example, the employees.department_id column, but an application may need to access the data with many different keys, for example, by employee_id or job_id. Global indexes can be useful in this scenario.
You can partition a global index by range or by hash. If partitioned by range, then the database partitions the global index on the ranges of values from the table columns you specify in the column list. If partitioned by hash, then the database assigns rows to the partitions using a hash function on values in the partitioning key columns.
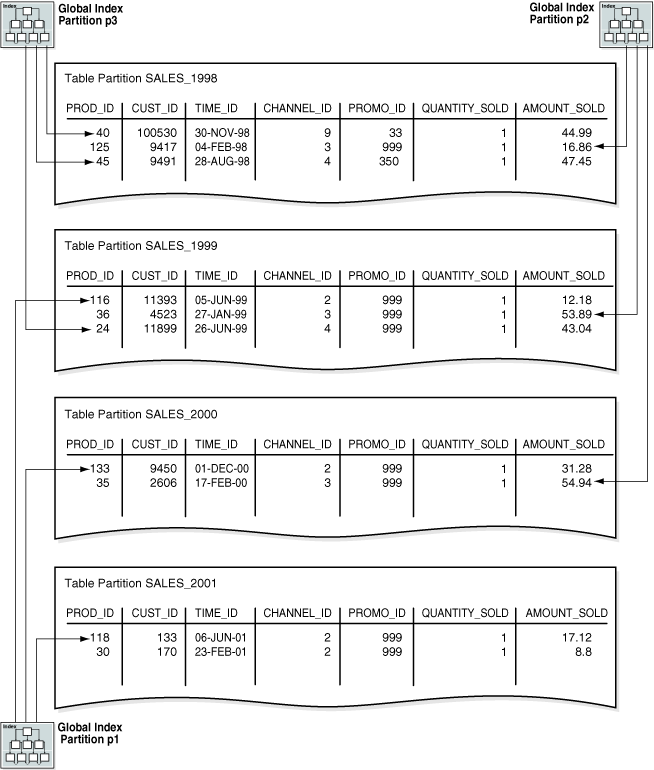
As an illustration, suppose that you create a global partitioned index on the time_range_sales table from Example 4-2. In this table, rows for sales from 1998 are stored in one partition, rows for sales from 1999 are in another, and so on. Example 4-6 creates a global index partitioned by range on the channel_id column.
Example 4-6 Global Partitioned Index
CREATE INDEX time_channel_sales_idx ON time_range_sales (channel_id) GLOBAL PARTITION BY RANGE (channel_id) (PARTITION p1 VALUES LESS THAN (3), PARTITION p2 VALUES LESS THAN (4), PARTITION p3 VALUES LESS THAN (MAXVALUE));
As shown in Figure 4-5, a global index partition can contain entries that point to multiple table partitions. Index partition p1 points to the rows with a channel_id of 2, index partition p2 points to the rows with a channel_id of 3, and index partition p3 points to the rows with a channel_id of 4 or 9.
See Also:
-
Oracle Database VLDB and Partitioning Guide to learn how to use global partitioned indexes
-
Oracle Database SQL Language Reference for
CREATE INDEX ... GLOBALexamples
Partitioned Index-Organized Tables
You can partition an index-organized table (IOT) by range, list, or hash. Partitioning is useful for providing improved manageability, availability, and performance for IOTs. In addition, data cartridges that use IOTs can take advantage of the ability to partition their stored data.
Note the following characteristics of partitioned IOTs:
-
Partition columns must be a subset of primary key columns.
-
Secondary indexes can be partitioned locally and globally.
-
OVERFLOWdata segments are always equipartitioned with the table partitions.
Oracle Database supports bitmap indexes on partitioned and nonpartitioned index-organized tables. A mapping table is required for creating bitmap indexes on an index-organized table.
See Also:
"Overview of Index-Organized Tables"Overview of Views
A view is a logical representation of one or more tables. In essence, a view is a stored query. A view derives its data from the tables on which it is based, called base tables. Base tables can be tables or other views. All operations performed on a view actually affect the base tables. You can use views in most places where tables are used.
Note:
Materialized views use a different data structure from standard views. See "Overview of Materialized Views".Views enable you to tailor the presentation of data to different types of users. Views are often used to:
-
Provide an additional level of table security by restricting access to a predetermined set of rows or columns of a table
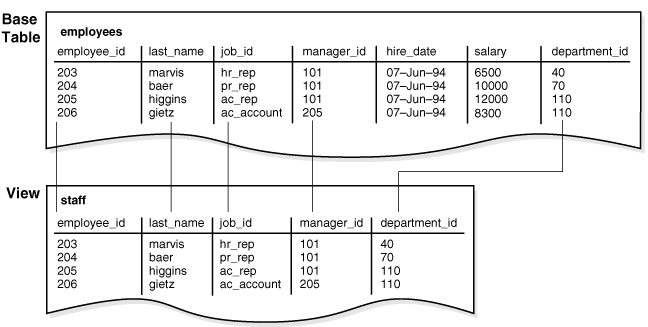
For example, Figure 4-6 shows how the
staffview does not show thesalaryorcommission_pctcolumns of the base tableemployees. -
For example, a single view can be defined with a join, which is a collection of related columns or rows in multiple tables. However, the view hides the fact that this information actually originates from several tables. A query might also perform extensive calculations with table information. Thus, users can query a view without knowing how to perform a join or calculations.
-
Present the data in a different perspective from that of the base table
For example, the columns of a view can be renamed without affecting the tables on which the view is based.
-
Isolate applications from changes in definitions of base tables
For example, if the defining query of a view references three columns of a four column table, and a fifth column is added to the table, then the definition of the view is not affected, and all applications using the view are not affected.
For an example of the use of views, consider the hr.employees table, which has several columns and numerous rows. To allow users to see only five of these columns or only specific rows, you could create a view as follows:
CREATE VIEW staff AS SELECT employee_id, last_name, job_id, manager_id, department_id FROM employees;
As with all subqueries, the query that defines a view cannot contain the FOR UPDATE clause. Figure 4-6 graphically illustrates the view named staff. Notice that the view shows only five of the columns in the base table.
See Also:
-
Oracle Database Administrator's Guide to learn how to manage views
-
Oracle Database SQL Language Reference for
CREATE VIEWsyntax and semantics
Characteristics of Views
Unlike a table, a view is not allocated storage space, nor does a view contain data. Rather, a view is defined by a query that extracts or derives data from the base tables referenced by the view. Because a view is based on other objects, it requires no storage other than storage for the query that defines the view in the data dictionary.
A view has dependencies on its referenced objects, which are automatically handled by the database. For example, if you drop and re-create a base table of a view, then the database determines whether the new base table is acceptable to the view definition.
Data Manipulation in Views
Because views are derived from tables, they have many similarities. For example, a view can contain up to 1000 columns, just like a table. Users can query views, and with some restrictions they can perform DML on views. Operations performed on a view affect data in some base table of the view and are subject to the integrity constraints and triggers of the base tables.
The following example creates a view of the hr.employees table:
CREATE VIEW staff_dept_10 AS
SELECT employee_id, last_name, job_id,
manager_id, department_id
FROM employees
WHERE department_id = 10
WITH CHECK OPTION CONSTRAINT staff_dept_10_cnst;
The defining query references only rows for department 10. The CHECK OPTION creates the view with a constraint so that INSERT and UPDATE statements issued against the view cannot result in rows that the view cannot select. Thus, rows for employees in department 10 can be inserted, but not rows for department 30.
See Also:
Oracle Database SQL Language Reference to learn about subquery restrictions inCREATE VIEW statementsHow Data Is Accessed in Views
Oracle Database stores a view definition in the data dictionary as the text of the query that defines the view. When you reference a view in a SQL statement, Oracle Database performs the following tasks:
-
Merges a query (whenever possible) against a view with the queries that define the view and any underlying views
Oracle Database optimizes the merged query as if you issued the query without referencing the views. Therefore, Oracle Database can use indexes on any referenced base table columns, whether the columns are referenced in the view definition or in the user query against the view.
Sometimes Oracle Database cannot merge the view definition with the user query. In such cases, Oracle Database may not use all indexes on referenced columns.
-
Parses the merged statement in a shared SQL area
Oracle Database parses a statement that references a view in a new shared SQL area only if no existing shared SQL area contains a similar statement. Thus, views provide the benefit of reduced memory use associated with shared SQL.
-
Executes the SQL statement
The following example illustrates data access when a view is queried. Assume that you create employees_view based on the employees and departments tables:
CREATE VIEW employees_view AS SELECT employee_id, last_name, salary, location_id FROM employees JOIN departments USING (department_id) WHERE department_id = 10;
A user executes the following query of employees_view:
SELECT last_name FROM employees_view WHERE employee_id = 200;
Oracle Database merges the view and the user query to construct the following query, which it then executes to retrieve the data:
SELECT last_name FROM employees, departments WHERE employees.department_id = departments.department_id AND departments.department_id = 10 AND employees.employee_id = 200;
See Also:
-
"Overview of the Optimizer" and Oracle Database Performance Tuning Guide to learn about query optimization
Updatable Join Views
A join view is defined as a view that has multiple tables or views in its FROM clause. In Example 4-7, the staff_dept_10_30 view joins the employees and departments tables, including only employees in departments 10 or 30.
CREATE VIEW staff_dept_10_30 AS SELECT employee_id, last_name, job_id, e.department_id FROM employees e, departments d WHERE e.department_id IN (10, 30) AND e.department_id = d.department_id;
An updatable join view, also called a modifiable join view, involves two or more base tables or views and permits DML operations. An updatable view contains multiple tables in the top-level FROM clause of the SELECT statement and is not restricted by the WITH READ ONLY clause.
To be inherently updatable, a view must meet several criteria. For example, a general rule is that an INSERT, UPDATE, or DELETE operation on a join view can modify only one base table at a time. The following query of the USER_UPDATABLE_COLUMNS data dictionary view shows that the view created in Example 4-7 is updatable:
SQL> SELECT TABLE_NAME, COLUMN_NAME, UPDATABLE 2 FROM USER_UPDATABLE_COLUMNS 3 WHERE TABLE_NAME = 'STAFF_DEPT_10_30'; TABLE_NAME COLUMN_NAME UPD ------------------------------ ------------------------------ --- STAFF_DEPT_10_30 EMPLOYEE_ID YES STAFF_DEPT_10_30 LAST_NAME YES STAFF_DEPT_10_30 JOB_ID YES STAFF_DEPT_10_30 DEPARTMENT_ID YES
All updatable columns of a join view must map to columns of a key-preserved table. A key-preserved table in a join query is a table in which each row of the underlying table appears at most one time in the output of the query. In Example 4-7, department_id is the primary key of the departments table, so each row from the employees table appears at most once in the result set, making the employees table key-preserved. The departments table is not key-preserved because each of its rows may appear many times in the result set.
See Also:
Oracle Database Administrator's Guide to learn how to update join viewsObject Views
Just as a view is a virtual table, an object view is a virtual object table. Each row in the view is an object, which is an instance of an object type. An object type is a user-defined data type.
You can retrieve, update, insert, and delete relational data as if it was stored as an object type. You can also define views with columns that are object data types, such as objects, REFs, and collections (nested tables and VARRAYs).
Like relational views, object views can present only the data that you want users to see. For example, an object view could present data about IT programmers but omit sensitive data about salaries. The following example creates an employee_type object and then the view it_prog_view based on this object:
CREATE TYPE employee_type AS OBJECT ( employee_id NUMBER (6), last_name VARCHAR2 (25), job_id VARCHAR2 (10) ); / CREATE VIEW it_prog_view OF employee_type WITH OBJECT IDENTIFIER (employee_id) AS SELECT e.employee_id, e.last_name, e.job_id FROM employees e WHERE job_id = 'IT_PROG';
Object views are useful in prototyping or transitioning to object-oriented applications because the data in the view can be taken from relational tables and accessed as if the table were defined as an object table. You can run object-oriented applications without converting existing tables to a different physical structure.
See Also:
-
Oracle Database Object-Relational Developer's Guide to learn about object types and object views
-
Oracle Database SQL Language Reference to learn about the
CREATE TYPEcommand
Overview of Materialized Views
Materialized views are query results that have been stored or "materialized" in advance as schema objects. The FROM clause of the query can name tables, views, and materialized views. Collectively these objects are called master tables (a replication term) or detail tables (a data warehousing term).
Materialized views are used to summarize, compute, replicate, and distribute data. They are suitable in various computing environments, such as the following:
-
In data warehouses, you can use materialized views to compute and store data generated from aggregate functions such as sums and averages.
A summary is an aggregate view that reduces query time by precalculating joins and aggregation operations and storing the results in a table. Materialized views are equivalent to summaries (see "Data Warehouse Architecture (Basic)"). You can also use materialized views to compute joins with or without aggregations. If compatibility is set to Oracle9i or higher, then materialized views are usable for queries that include filter selections.
-
In materialized view replication, the view contains a complete or partial copy of a table from a single point in time. Materialized views replicate data at distributed sites and synchronize updates performed at several sites. This form of replication is suitable for environments such as field sales when databases are not always connected to the network.
-
In mobile computing environments, you can use materialized views to download a data subset from central servers to mobile clients, with periodic refreshes from the central servers and propagation of updates by clients to the central servers.
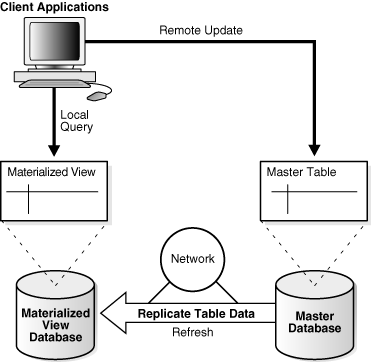
In a replication environment, a materialized view shares data with a table in a different database, called a master database. The table associated with the materialized view at the master site is the master table. Figure 4-7 illustrates a materialized view in one database based on a master table in another database. Updates to the master table replicate to the materialized view database.
See Also:
-
"Information Sharing" to learn about replication with Oracle Streams
-
Oracle Database 2 Day + Data Replication and Integration Guide and Oracle Database Advanced Replication to learn how to use materialized views
-
Oracle Database SQL Language Reference to learn about the
CREATE MATERIALIZED VIEWstatement
Characteristics of Materialized Views
Materialized views share some characteristics of nonmaterialized views and indexes. Materialized views are similar to indexes in the following ways:
-
They contain actual data and consume storage space.
-
They can be refreshed when the data in their master tables changes.
-
They can improve performance of SQL execution when used for query rewrite operations.
-
Their existence is transparent to SQL applications and users.
A materialized view is similar to a nonmaterialized view because it represents data in other tables and views. Unlike indexes, users can query materialized views directly using SELECT statements. Depending on the types of refresh that are required, the views can also be updated with DML statements.
The following example creates and populates a materialized aggregate view based on three master tables in the sh sample schema:
CREATE MATERIALIZED VIEW sales_mv AS SELECT t.calendar_year, p.prod_id, SUM(s.amount_sold) AS sum_sales FROM times t, products p, sales s WHERE t.time_id = s.time_id AND p.prod_id = s.prod_id GROUP BY t.calendar_year, p.prod_id;
The following example drops table sales, which is a master table for sales_mv, and then queries sales_mv. The query selects data because the rows are stored (materialized) separately from the data in the master tables.
SQL> DROP TABLE sales;
Table dropped.
SQL> SELECT * FROM sales_mv WHERE ROWNUM < 4;
CALENDAR_YEAR PROD_ID SUM_SALES
------------- ---------- ----------
1998 13 936197.53
1998 26 567533.83
1998 27 107968.24
A materialized view can be partitioned. You can define a materialized view on a partitioned table and one or more indexes on the materialized view.
See Also:
Oracle Database Data Warehousing Guide to learn how to use materialized views in a data warehouseRefresh Methods for Materialized Views
The database maintains data in materialized views by refreshing them after changes to their master tables. The refresh method can be incremental, known as fast refresh, or a complete refresh.
A complete refresh occurs when the materialized view is initially defined as BUILD IMMEDIATE, unless the materialized view references a prebuilt table. The refresh involves executing the query that defines the materialized view. This process can be slow, especially if the database must read and process huge amounts of data.
A fast refresh eliminates the need to rebuild materialized views from scratch. Thus, processing only the changes can result in a very fast refresh time. Materialized views can be refreshed either on demand or at regular time intervals. Alternatively, materialized views in the same database as their master tables can be refreshed whenever a transaction commits its changes to the master tables.
For materialized views that use the fast refresh method, a materialized view log or direct loader log keeps a record of changes to the master tables. A materialized view log is a schema object that records changes to master table data so that a materialized view defined on the master table can be refreshed incrementally. Each materialized view log is associated with a single master table. The materialized view log resides in the same database and schema as its master table.
See Also:
-
Oracle Database Data Warehousing Guide to learn how to refresh materialized views
-
Oracle Database Advanced Replication to learn about materialized view logs
Query Rewrite
Query rewrite is an optimization technique that transforms a user request written in terms of master tables into a semantically equivalent request that includes materialized views. When base tables contain large amounts of data, computing an aggregate or join is expensive and time-consuming. Because materialized views contain precomputed aggregates and joins, query rewrite can quickly answer queries using materialized views.
The optimizer query transformer transparently rewrites the request to use the materialized view, requiring no user intervention and no reference to the materialized view in the SQL statement. Because query rewrite is transparent, materialized views can be added or dropped without invalidating the SQL in the application code.
In general, rewriting queries to use materialized views rather than detail tables improves response time. Figure 4-8 shows the database generating an execution plan for the original and rewritten query and choosing the lowest-cost plan.
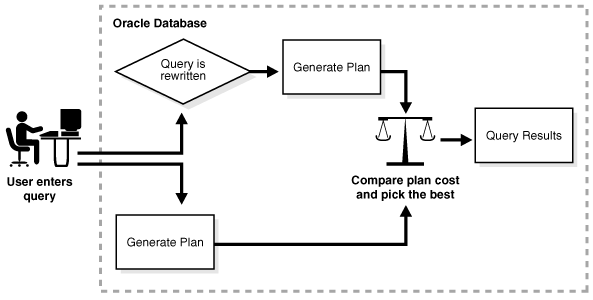
See Also:
-
Oracle Database Data Warehousing Guide to learn how to use query rewrite
Overview of Sequences
A sequence is a schema object from which multiple users can generate unique integers. A sequence generator provides a highly scalable and well-performing method to generate surrogate keys for a number data type.
Sequence Characteristics
A sequence definition indicates general information, such as the following:
-
The name of the sequence
-
Whether the sequence ascends or descends
-
The interval between numbers
-
Whether the database should cache sets of generated sequence numbers in memory
-
Whether the sequence should cycle when a limit is reached
The following example creates the sequence customers_seq in the sample schema oe. An application could use this sequence to provide customer ID numbers when rows are added to the customers table.
CREATE SEQUENCE customers_seq START WITH 1000 INCREMENT BY 1 NOCACHE NOCYCLE;
The first reference to customers_seq.nextval returns 1000. The second returns 1001. Each subsequent reference returns a value 1 greater than the previous reference.
See Also:
-
Oracle Database 2 Day Developer's Guide and Oracle Database Administrator's Guide to learn how to manage sequences
-
Oracle Database SQL Language Reference for
CREATE SEQUENCEsyntax and semantics
Concurrent Access to Sequences
The same sequence generator can generate numbers for multiple tables. In this way, the database can generate primary keys automatically and coordinate keys across multiple rows or tables. For example, a sequence can generate primary keys for an orders table and a customers table.
The sequence generator is useful in multiuser environments for generating unique numbers without the overhead of disk I/O or transaction locking. For example, two users simultaneously insert new rows into the orders table. By using a sequence to generate unique numbers for the order_id column, neither user has to wait for the other to enter the next available order number. The sequence automatically generates the correct values for each user.
Each user that references a sequence has access to his or her current sequence number, which is the last sequence generated in the session. A user can issue a statement to generate a new sequence number or use the current number last generated by the session. After a statement in a session generates a sequence number, it is available only to this session. Individual sequence numbers can be skipped if they were generated and used in a transaction that was ultimately rolled back.
Caution:
If your application requires a gap-free set of numbers, then you cannot use Oracle sequences. You must serialize activities in the database using your own developed code.
Overview of Dimensions
A typical data warehouse has two important components: dimensions and facts. A dimension is any category used in specifying business questions, for example, time, geography, product, department, and distribution channel. A fact is an event or entity associated with a particular set of dimension values, for example, units sold or profits.
Examples of multidimensional requests include the following:
-
Show total sales across all products at increasing aggregation levels for a geography dimension, from state to country to region, for 2010 and 2011.
-
Create a cross-tabular analysis of our operations showing expenses by territory in South America for 2010 and 2011. Include all possible subtotals.
-
List the top 10 sales representatives in Asia according to 2011 sales revenue for automotive products, and rank their commissions.
Many multidimensional questions require aggregated data and comparisons of data sets, often across time, geography or budgets.
Creating a dimension permits the broader use of the query rewrite feature. By transparently rewriting queries to use materialized views, the database can improve query performance.
Hierarchical Structure of a Dimension
A dimension table is a logical structure that defines hierarchical relationships between pairs of columns or column sets. A dimension has no data storage assigned to it. Dimensional information is stored in dimension tables, whereas fact information is stored in a fact table.
Within a customer dimension, customers could roll up to city, state, country, subregion, and region. Data analysis typically starts at higher levels in the dimensional hierarchy and gradually drills down if the situation warrants such analysis.
Each value at the child level is associated with one and only one value at the parent level. A hierarchical relationship is a functional dependency from one level of a hierarchy to the next level in the hierarchy.
See Also:
-
Oracle Database Data Warehousing Guide to learn about dimensions
-
Oracle OLAP User's Guide to learn how to create dimensions
Creation of Dimensions
Dimensions are created with SQL statements. The CREATE DIMENSION statement specifies:
-
Multiple
LEVELclauses, each of which identifies a column or column set in the dimension -
One or more
HIERARCHYclauses that specify the parent/child relationships between adjacent levels -
Optional
ATTRIBUTEclauses, each of which identifies an additional column or column set associated with an individual level
The following statement was used to create the customers_dim dimension in the sample schema sh:
CREATE DIMENSION customers_dim
LEVEL customer IS (customers.cust_id)
LEVEL city IS (customers.cust_city)
LEVEL state IS (customers.cust_state_province)
LEVEL country IS (countries.country_id)
LEVEL subregion IS (countries.country_subregion)
LEVEL region IS (countries.country_region)
HIERARCHY geog_rollup (
customer CHILD OF
city CHILD OF
state CHILD OF
country CHILD OF
subregion CHILD OF
region
JOIN KEY (customers.country_id) REFERENCES country )
ATTRIBUTE customer DETERMINES
(cust_first_name, cust_last_name, cust_gender,
cust_marital_status, cust_year_of_birth,
cust_income_level, cust_credit_limit)
ATTRIBUTE country DETERMINES (countries.country_name);
The columns in a dimension can come either from the same table (denormalized) or from multiple tables (fully or partially normalized). For example, a normalized time dimension can include a date table, a month table, and a year table, with join conditions that connect each date row to a month row, and each month row to a year row. In a fully denormalized time dimension, the date, month, and year columns are in the same table. Whether normalized or denormalized, the hierarchical relationships among the columns must be specified in the CREATE DIMENSION statement.
See Also:
-
Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide for information about how dimensions are used in a warehousing environment
-
Oracle Database SQL Language Reference for
CREATE DIMENSIONsyntax and semantics
Overview of Synonyms
A synonym is an alias for a schema object. For example, you can create a synonym for a table or view, sequence, PL/SQL program unit, user-defined object type, or another synonym. Because a synonym is simply an alias, it requires no storage other than its definition in the data dictionary.
Synonyms can simplify SQL statements for database users. Synonyms are also useful for hiding the identity and location of an underlying schema object. If the underlying object must be renamed or moved, then only the synonym must be redefined. Applications based on the synonym continue to work without modification.
You can create both private and public synonyms. A private synonym is in the schema of a specific user who has control over its availability to others. A public synonym is owned by the user group named PUBLIC and is accessible by every database user.
In Example 4-9, a database administrator creates a public synonym named people for the hr.employees table. The user then connects to the oe schema and counts the number of rows in the table referenced by the synonym.
SQL> CREATE PUBLIC SYNONYM people FOR hr.employees;
Synonym created.
SQL> CONNECT oe
Enter password: password
Connected.
SQL> SELECT COUNT(*) FROM people;
COUNT(*)
----------
107
Use public synonyms sparingly because they make database consolidation more difficult. As shown in Example 4-9, if another administrator attempts to create the public synonym people, then the creation fails because only one public synonym people can exist in the database. Overuse of public synonyms causes namespace conflicts between applications.
SQL> CREATE PUBLIC SYNONYM people FOR oe.customers;
CREATE PUBLIC SYNONYM people FOR oe.customers
*
ERROR at line 1:
ORA-00955: name is already used by an existing object
SQL> SELECT OWNER, SYNONYM_NAME, TABLE_OWNER, TABLE_NAME
2 FROM DBA_SYNONYMS
3 WHERE SYNONYM_NAME = 'PEOPLE';
OWNER SYNONYM_NAME TABLE_OWNER TABLE_NAME
---------- ------------ ----------- ----------
PUBLIC PEOPLE HR EMPLOYEES
Synonyms themselves are not securable. When you grant object privileges on a synonym, you are really granting privileges on the underlying object. The synonym is acting only as an alias for the object in the GRANT statement.
See Also:
-
Oracle Database Administrator's Guide to learn how to manage synonyms
-
Oracle Database SQL Language Reference for
CREATE SYNONYMsyntax and semantics